








本节是自己改编的用正则表达式抓取数据案例,在第一篇结尾我们留下了两个问题,学习了第二篇的正则表达式后,我们可以尝试去解决了。
一、 怎么获取目录中每章的信息
在获取小说内容之前,我肯定得先从目录拿到每一章的标题和链接
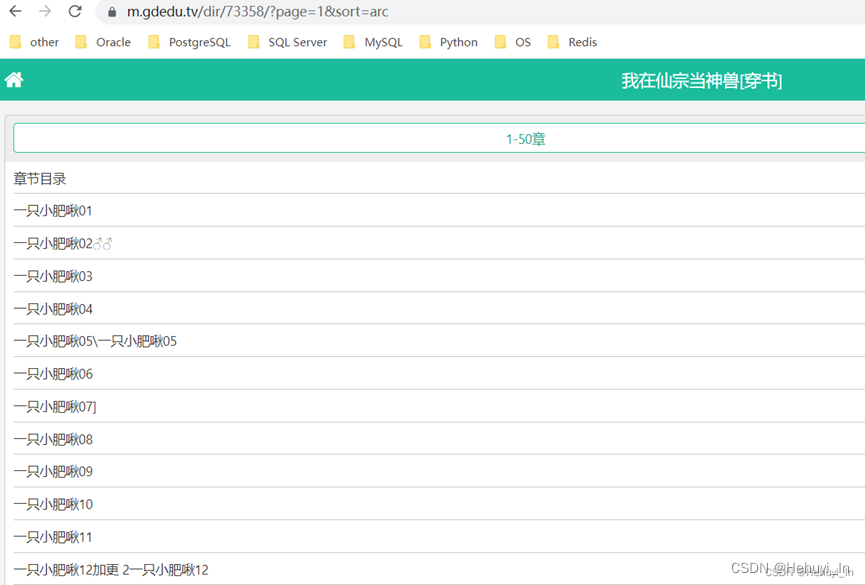
1. 首先确认渲染方式
也就是要的数据在不在源代码中。建议多往后翻几页看看,有些网页源码只是有第一页的数据,后面的就没有了(例如csdn)。如果是客户端渲染,就不能用正则表达式来取。
这里我看了几页,数据都是在源码中的,那就比较简单了。
2. 拿到网页源码
首先写个最简单的print,获取网页信息,方便起见headers参数一并加上。
import requests
url= "https://m.gdedu.tv/dir/73358/?page=1&sort=asc"
headers = {"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/102.0.5005.63 Safari/537.36"}
resp = requests.get(url=url,headers=headers)
print(resp.text)
resp.close()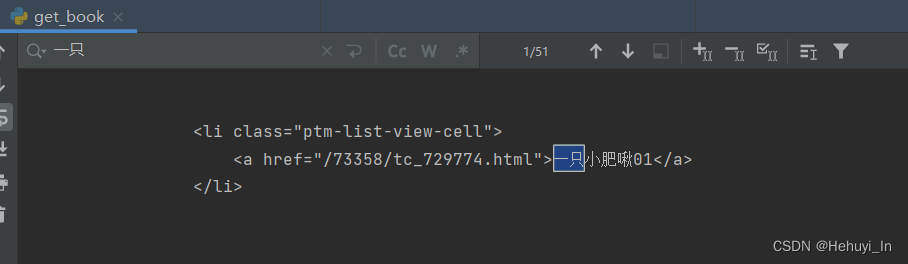
3. 正则匹配想要的信息
我们要标题、链接

随便点进去一章你会发现,上面herf的链接只是一部分,还要再拼上网站首页的地址 https://m.gdedu.tv
匹配思路如下:
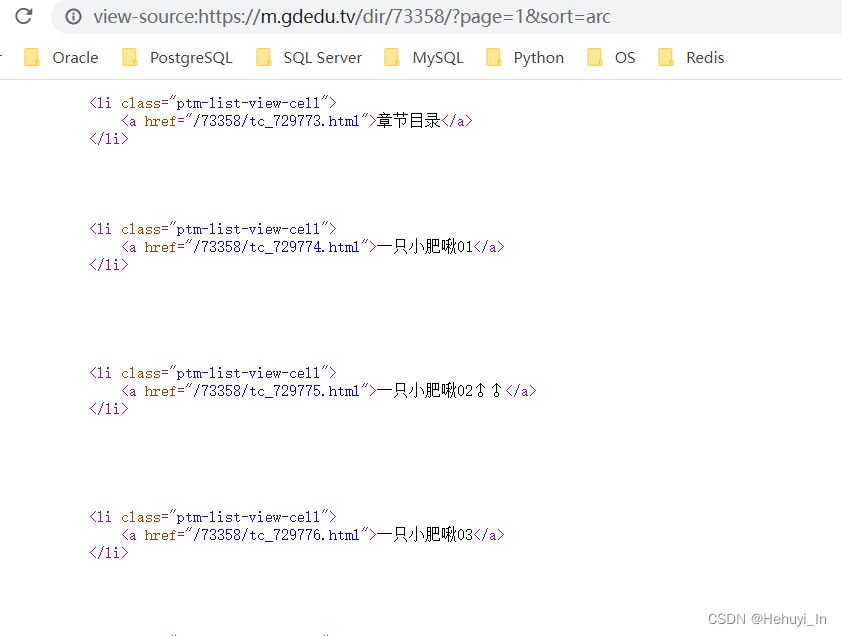
- 首先复制一行包含所需内容的html出来,看看需要的信息在哪里
<li class="ptm-list-view-cell">
<a href="/73358/tc_729773.html">章节目录</a>
</li>
<li class="ptm-list-view-cell">
<a href="/73358/tc_729774.html">一只小肥啾01</a>
</li>
简单是很简单,但你会发现不好把“章节目录”跟真正的章节区分开,不过也没关系,返回数据的时候再处理就可以。
- 找到之后开始写正则表达式
注意:从起始字符串开始,每个值可能会有变化的地方都要匹配到
- <a href=" 这段只在我们需要的内容部分出现,因此从它开始
- 因为这个链接特别简单,我们直接替换并保存值即可
<a href="/73358/tc_729774.html">一只小肥啾01</a>
obj = re.compile(r'<a href="(?P<link>.*?)">(?P<title>.*?)<',re.S)
- 取出匹配之后的数据
it = obj.finditer(html)
for i in it:
print(i.group("title")+'---'+i.group("link"))
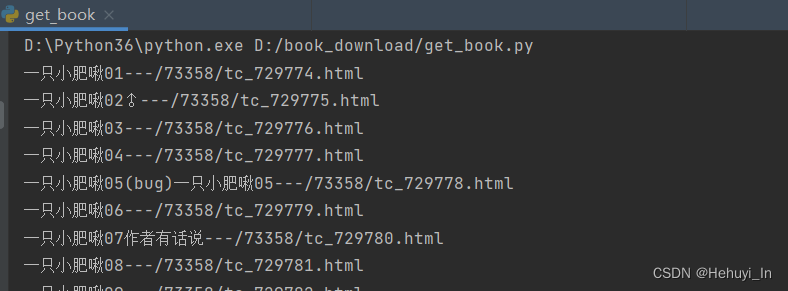
跑一下试试:
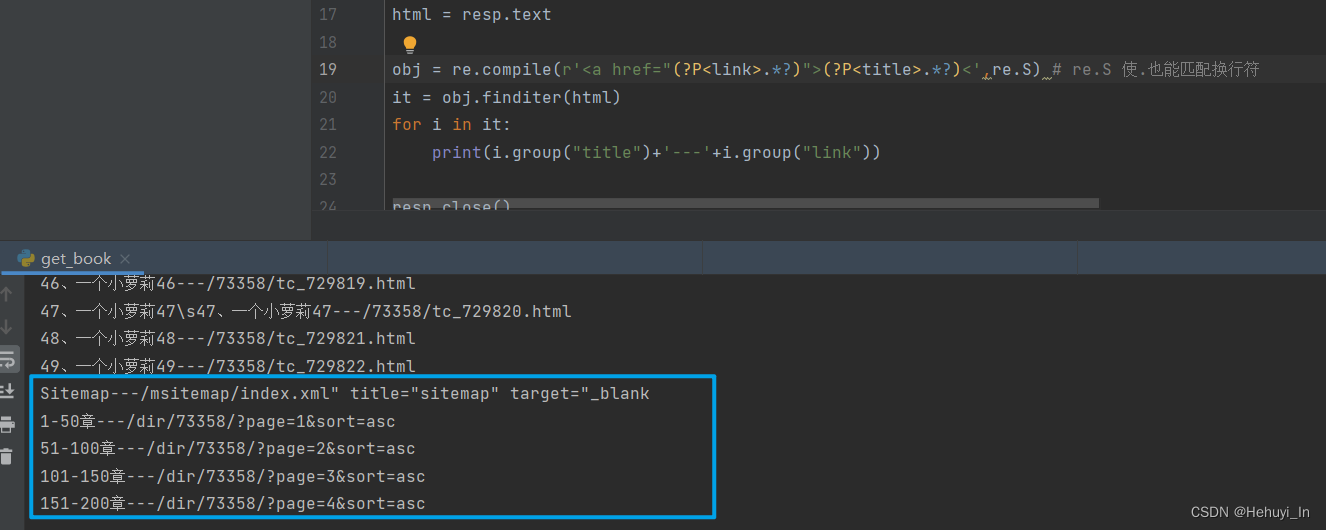
发现虽然取到了,但有些多余的数据,其实是翻页的链接。
这里我们还是用标准的传参方式翻页,所以在输出数据的时候过滤掉这些多余的。
it = obj.finditer(html)
for i in it:
if ("章节目录" in i.group("title")) or ("Sitemap" in i.group("title")) or ("page" in i.group("link")):
pass
else:
print(i.group("title")+'---'+i.group("link"))
ok~
4. 获取所有页
F12抓包,刷新页面,可以看到它有两个入参
但是这里没找到有总记录数的数据,如果想要自动判断一共多少页的话,可能还是把上面page链接存起来会简单点?
这里我人工看了下,一共4页,所以有几个地方要改:
- 改url地址,去掉?之后的部分
- 加一个page变量,循环赋值
- 加一个入参字典
- get方法加params参数
- 把link跟前面的root_page拼起来
url= "https://m.gdedu.tv/dir/73358/"
for page in range(1,5):
params = {
"page": page,
"sort": "asc"
}
resp = requests.get(url=url,headers=headers,params=params)
...
dic["link"] = root_page+i.group("link")
测试点击,可以打开
这两个变量既然取到了,后面保存到文档也好,保存到list做后续处理也好,就都OK了。
二、 怎么获取每章的子页面链接
如果用的是一页显示本章全部内容的网站,其实上面的步骤就ok了,不需要这里。
1. 页面分析
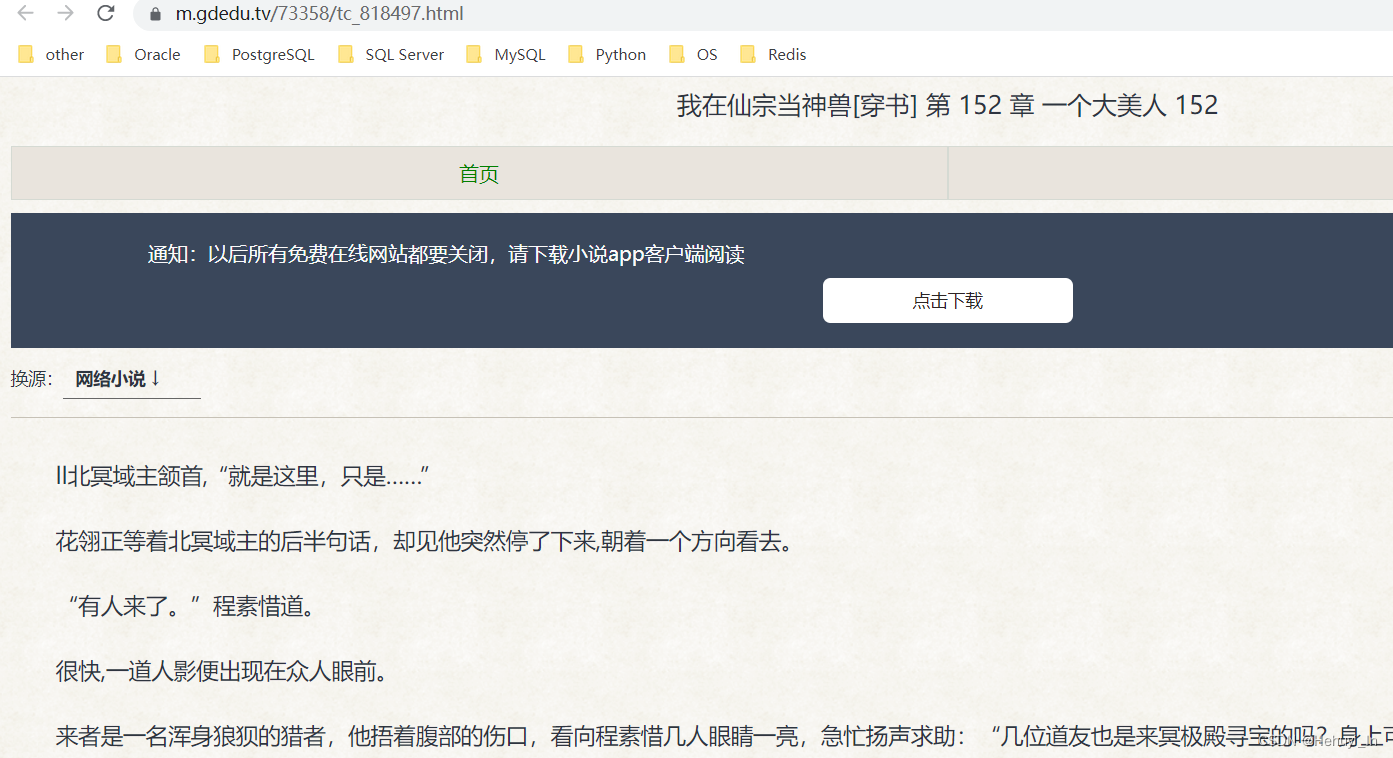
随便打开一章,会发现每章里面也是有分页的,并且这个页码不像目录的页码,抓包里是没有的。
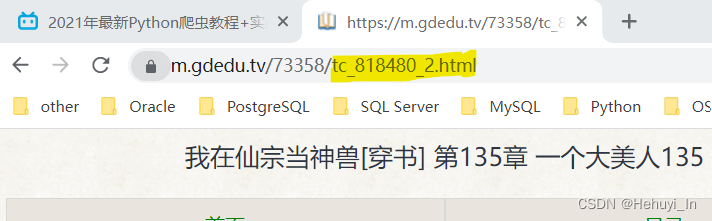
但是很明显这个页数就在链接里了,这种情况要怎么判断每章有多少页,下页链接是什么呢?
其实同理,这个“下一章”也有自己对应的链接
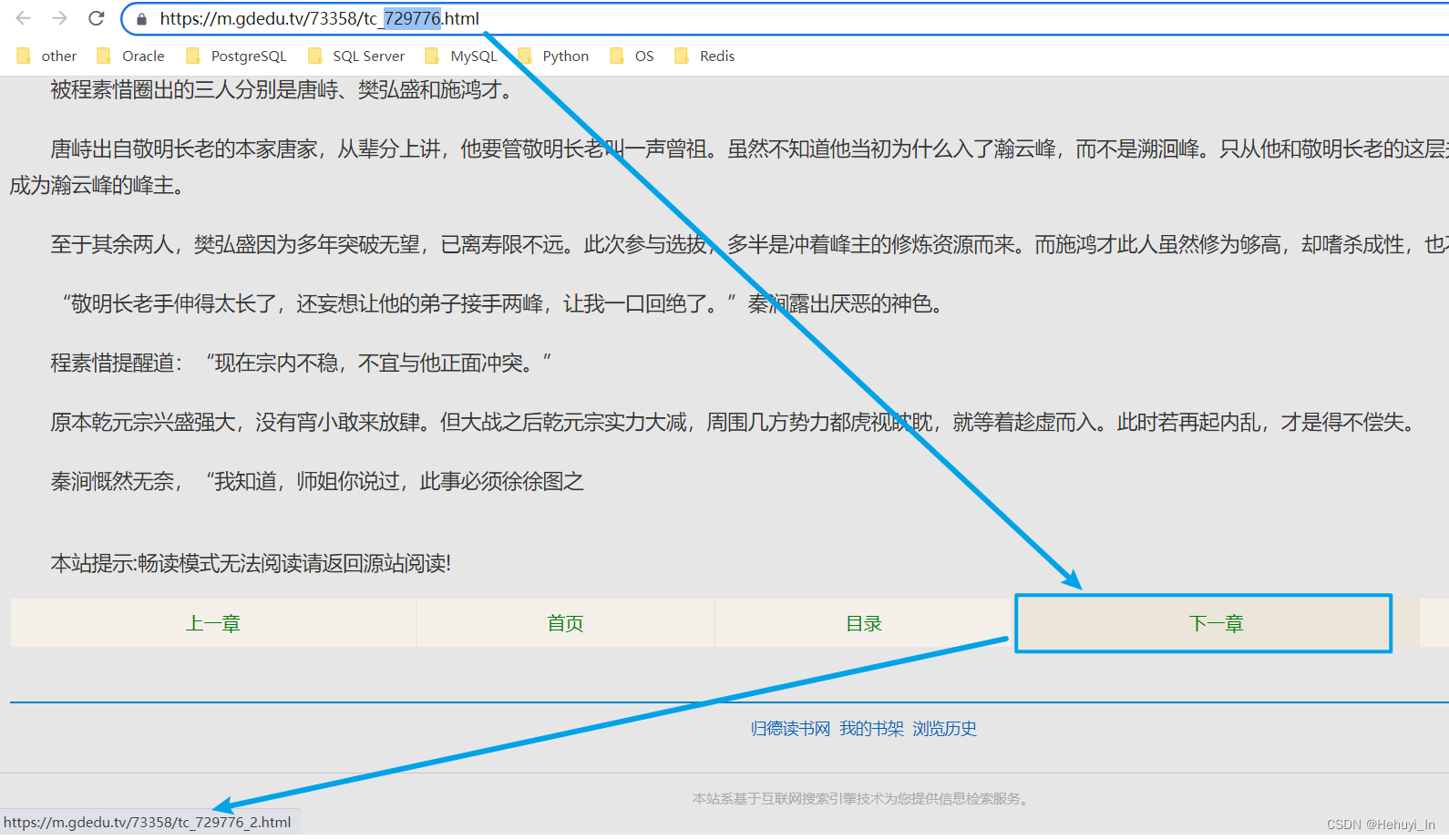
查看源码,搜729776,这玩意在JavaScript标签里。但是没关系,只要你会匹配上面的超链接,你自然就会匹配下面这个。
2. 匹配下一章链接
这个原理跟拿每章链接是一样的,传入url,然后通过正则表达式匹配链接,再拼起来。
# 传入每章链接,获取本章的子链接
def get_next_url(chapter_url,headers):
# chapter_url = "https://m.gdedu.tv/73358/tc_818487.html"
resp = requests.get(url=chapter_url, headers=headers)
# 获取各章源码
html = resp.text
# 匹配下一页链接
obj = re.compile(r'var nexturl = "(?P<nexturl>.*?)"', re.S) # re.S 使.也能匹配换行符
# 因为只会有一个nexturl,这里用search就可以
s = obj.search(html)
# 拼好的下一页链接
full_nexturl = root_page+s.group("nexturl")
return full_nexturl3. 怎么确定每章有几个子页面?
下面这个方法是我自己想的,比较直接,如果有更好的方法欢迎指教。
上面那个函数不难,但它只能拿到一个url的下一页,肯定得循环调用。但是我要怎么判断每章有几个子页面?这个不像是目录页数看一眼就知道,需要再观察下页面源码。
找到章节最后一页,看nexturl有什么特点:var nexturl = "/73358/tc_818488.html"; (下一章链接)
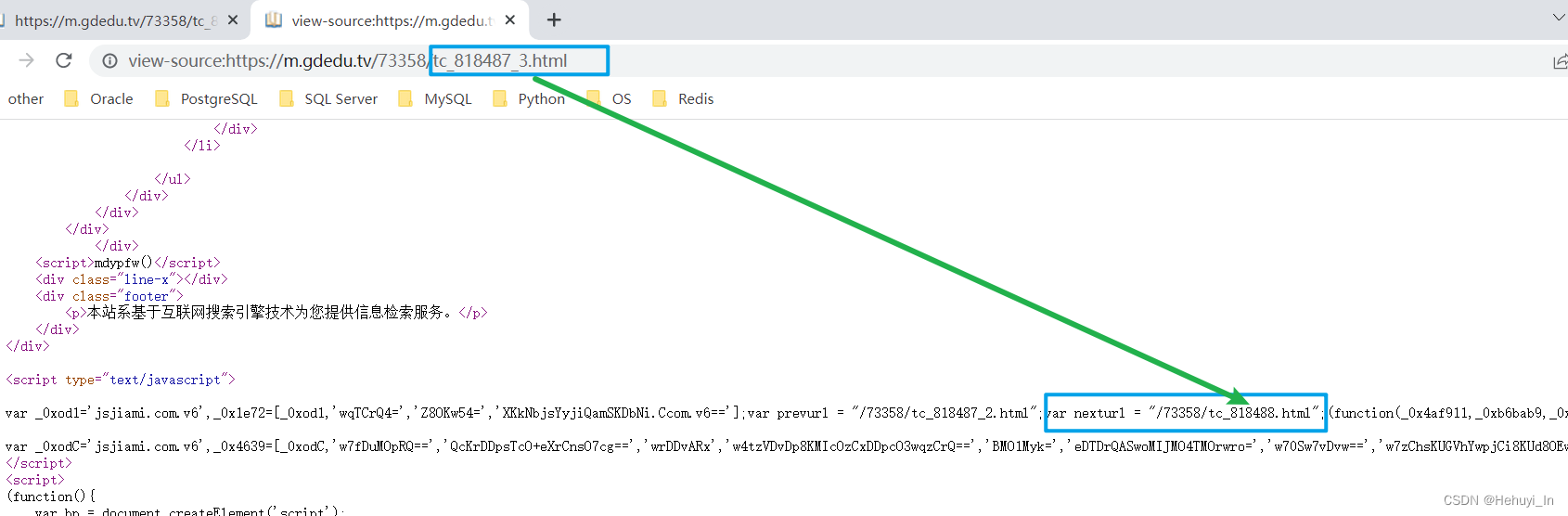
最大的区别在于下一章的时候tc_后面的数字会+1,而不再是xxx_3,xxx_4 这种子页面。
所以我们可以把当前链接的818487截取出来,再转成int类型
# 例如 tc_818487.html 截出来是 818487
cur_id = int(chapter_url["link"].split("_")[1].split(".")[0])
然后还要截一个下一页id
next_id = int(next_url.split("_")[1].split(".")[0])
代码如下:
if __name__ == '__main__':
chapter_url_list = get_chapter_url()
cnt = 0
for chapter_url in chapter_url_list:
f = open("url_list.txt", 'a', encoding='utf-8')
if cnt == 0:
# print(chapter_url["link"])
f.write(chapter_url["link"]+'\n')
cnt = cnt+1
# 例如 tc_818487.html 截出来是 818487
cur_id = int(chapter_url["link"].split("_")[1].split(".")[0])
next_url = chapter_url["link"]
# 由于不知道每章子页面一共有多少,这里来个死循环
while True:
# 获取下页链接
next_url = get_next_url(next_url, headers=headers,)
#print(next_url)
f.write(next_url+'\n')
# 如果next_id已经是下一章id(cur_id+1),说明这已经是本章最后一页,此时跳出while循环
next_id = int(next_url.split("_")[1].split(".")[0])
if next_id == cur_id+1:
break;
f.close()
这里加个计数器(绿色部分)是为了打印第一章第一页的信息,如果不加的话每章第一页会重复打印出来,去掉这行输出的话又会少一章。
4. 将链接写入文件
主要原因是这个匹配量太大了,每次重新匹配效率会很低,所以直接保存起来。上面代码蓝色部分就是,这里不重复写了。
三、 完整代码及运行结果
运行结果如下:
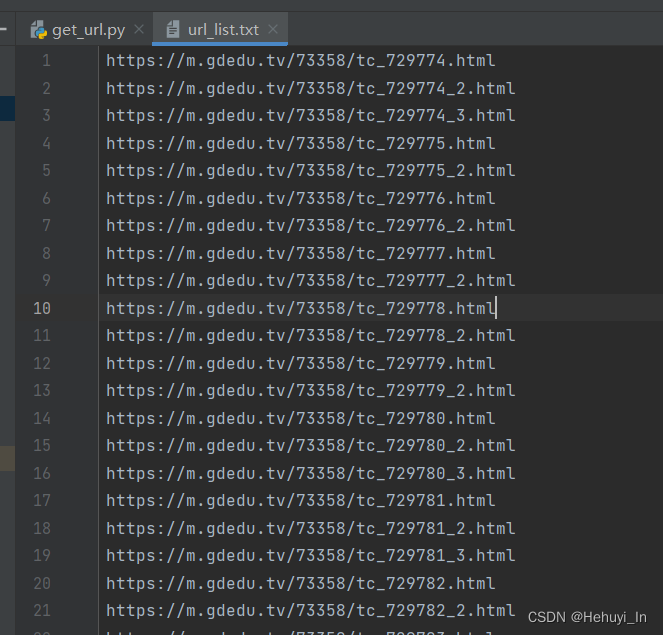
每一个章节和子页面的目录拿到手之后,下一节就可以获取小说内容了。
完整代码如下
#!/usr/bin/env python
# -*- coding:utf-8 -*-
# @Time : 2022-06-12 15:17
# @Author: Hehuyi_In
# @File : get_url.py
import requests
import re
# 网站首页url,用来拼章节链接
root_page = "https://m.gdedu.tv"
url= "https://m.gdedu.tv/dir/73358/"
headers = {"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/102.0.5005.63 Safari/537.36"}
# 传入每章链接,获取本章的子链接
def get_next_url(chapter_url,headers):
# chapter_url = "https://m.gdedu.tv/73358/tc_818487.html"
resp = requests.get(url=chapter_url, headers=headers)
# 获取各章源码
html = resp.text
# 匹配下一页链接
obj = re.compile(r'var nexturl = "(?P<nexturl>.*?)"', re.S) # re.S 使.也能匹配换行符
# 因为只会有一个nexturl,这里用search就可以
s = obj.search(html)
# 拼好的下一页链接
full_nexturl = root_page+s.group("nexturl")
return full_nexturl
def get_chapter_url():
chapter_url_list=[]
for page in range(1,5):
params = {
"page": page,
"sort": "asc"
}
resp = requests.get(url=url,headers=headers,params=params)
# 网页源码
html = resp.text
# 匹配各章节链接
obj = re.compile(r'<a href="(?P<link>.*?)">(?P<title>.*?)<',re.S) # re.S 使.也能匹配换行符
it = obj.finditer(html)
for i in it:
if ("章节目录" in i.group("title")) or ("Sitemap" in i.group("title")) or ("page" in i.group("link")):
pass
else:
dic={}
dic["title"]=i.group("title")
dic["link"] = root_page+i.group("link")
chapter_url_list.append(dic)
resp.close()
return chapter_url_list
if __name__ == '__main__':
chapter_url_list = get_chapter_url()
cnt = 0
for chapter_url in chapter_url_list:
f = open("url_list.txt", 'a', encoding='utf-8')
if cnt == 0:
# print(chapter_url["link"])
f.write(chapter_url["link"]+'\n')
cnt = cnt+1
# 例如 tc_818487.html 截出来是 818487
cur_id = int(chapter_url["link"].split("_")[1].split(".")[0])
next_url = chapter_url["link"]
# 由于不知道每章子页面一共有多少,这里来个死循环
while True:
# 获取下页链接
next_url = get_next_url(next_url, headers=headers,)
#print(next_url)
f.write(next_url+'\n')
# 找到章节最后一页,看有什么特点:var nexturl = "/73358/tc_818488.html"; (下一章链接)
# 如果next_id已经是下一章id(cur_id+1),说明这已经是本章最后一页,此时跳出while循环
next_id = int(next_url.split("_")[1].split(".")[0])
if next_id == cur_id+1:
break;
f.close()参考:B站视频 P23-P27
















 3117
3117











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











