







 本文介绍了如何使用Python的BeautifulSoup库解析HTML页面,提取小说内容。首先讲解了BeautifulSoup的基本用法,包括安装、核心思想及查找元素的方法。接着,通过实例展示了如何定位到小说章节的<div id='articlecon'>部分,并遍历内部的<p>标签获取文本内容。最后,给出了完整代码示例,演示如何读取小说URL列表,下载所有章节到TXT文件中。
本文介绍了如何使用Python的BeautifulSoup库解析HTML页面,提取小说内容。首先讲解了BeautifulSoup的基本用法,包括安装、核心思想及查找元素的方法。接着,通过实例展示了如何定位到小说章节的<div id='articlecon'>部分,并遍历内部的<p>标签获取文本内容。最后,给出了完整代码示例,演示如何读取小说URL列表,下载所有章节到TXT文件中。
一、 BeautifulSoup(bs4)简介
1. 安装
要使用bs4,首先需要安装对应的包
pip install beautifulsoup4
2. 核心思想
本质是通过html中的标签、或者标签中的属性定位到其中的内容。这个过程可以重复多次,例如你可以找到一个较大范围的唯一标签,再在其中定位想要的内容。因此,它比正则表达式要容易上手得多,你只需要找对应标签即可。
3. 用法简介
- 导入bs4包
- 将页面源码(参数1)交给bs4处理,得到bs4对象。参数2声明源码格式,以便bs4解析
- 从bs4中查找数据,只有find和find_all两种方法:
- find(标签,属性=值) 找到第一个符合的就停下,返回bs对象
- find_all(标签,属性=值) 找所有符合的,返回列表
- 因为find返回的是bs对象,所以可以继续对其调用find直到找到为止。而find_all返回的是列表,一般只有最后一层才会用到它,然后通过列表取数据。
属性的几种写法:
由于html部分标签属性的关键字跟python关键字是一样的(例如class),直接写这些属性名会报python语法错误,因此bs4的属性有两种写法可以避免这个问题。
- 非关键字写法:table = page.find("table",title="xxxx")
- 关键字写法(加下划线):table = page.find("table",class_="hq_table") 注意如果不是python关键字则不要加下划线,否则是匹配不到的,例如title_="xxxx"不行。
- attrs参数:table = page.find("table",attrs={"class_":"hq_table"})
二、 bs4获取小说内容
前面我们通过正则表达式拿到了一部小说的所有url,这里我们要做的就是读取并循环请求这些url,然后用bs4匹配其中的小说文本内容。
随便打开一章,查看源码,看看文本内容在哪个标签里 我在仙宗当神兽[穿书] 网络小说 - 第 142 章 一个大美人142 - 归德读书网
这里很幸运的是div id="articlecon"这个属性是唯一的,所以我们很方便就可以获取到这块内容。但是注意里面并不全是文本,还有很多<p></p>标签需要处理(后来发现这里p标签都是唯一的,但是这个例子太特殊,我们还是用div的标签学习bs4用法)。
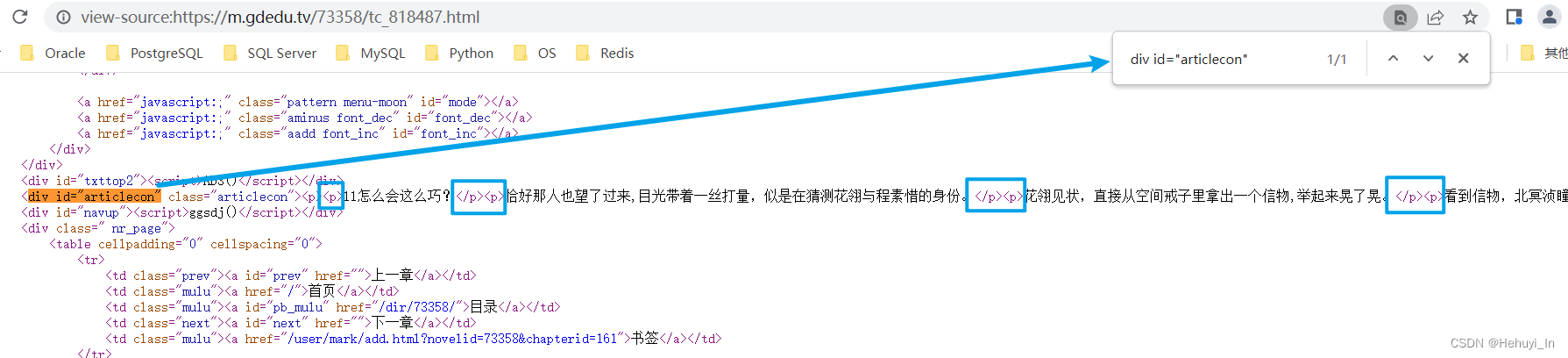
先拿一个链接,试着匹配div id="articlecon"部分内容
接下来的内容全在p标签里,因此要用find_all全部匹配出来。这里注意它有两层p标签,所以还要先find一次p标签。
find_all返回一个列表,里面每个元素是p标签和其中的内容,如果只想要其中的内容,需要再调用getText函数。如果想要标签中的属性,则用 列表.get("href")。
例如 <a href=www.baidu.com>百度</a>
- 如果想要 www.baidu.com,写法是 content.get("href")
- 如果想要 百度 两个字,写法是 content.getText()
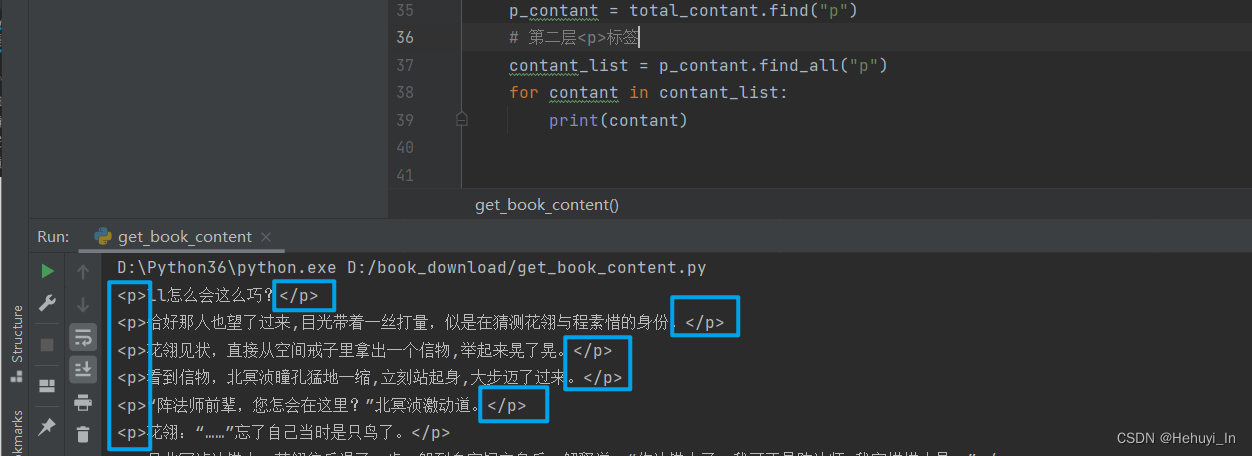
循环取出其中的内容,来看一下区别
直接输出:
使用getText方法
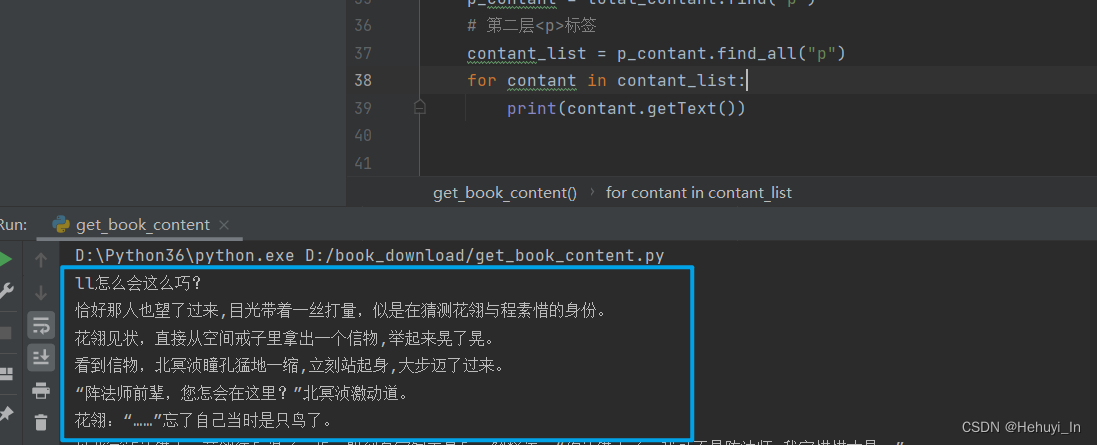
成功~~ 接下来把循环加上,就能输出所有章节内容了
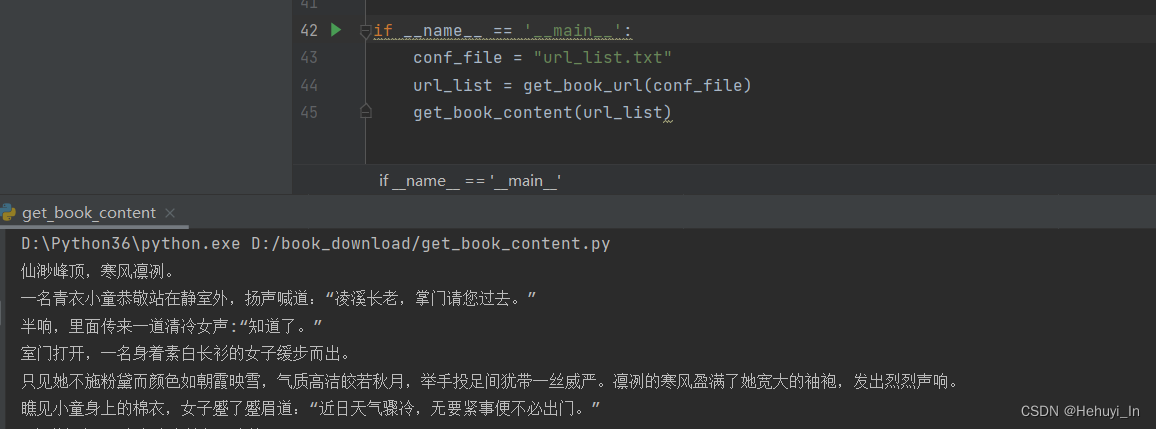
再来我们把输出存到txt文件中,小说下载就大功告成了~
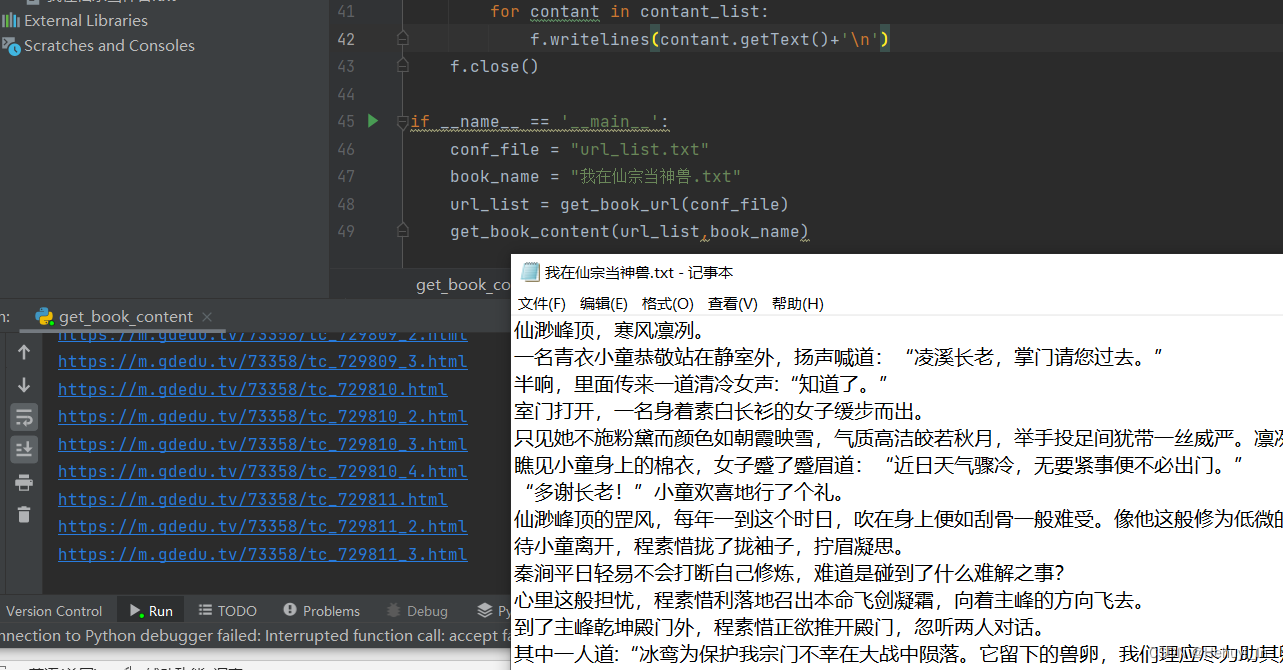
代码如下
#!/usr/bin/env python
# -*- coding:utf-8 -*-
# @Time : 2022-06-13 22:26
# @Author: Hehuyi_In
# @File : get_book_content.py
import requests
from bs4 import BeautifulSoup
def get_book_url(conf_file):
f = open(conf_file)
url_list = f.read().splitlines()
f.close()
return url_list
def get_book_content(url_list,book_name):
f = open(book_name, 'a', encoding='utf-8')
for url in url_list:
print(url)
resp = requests.get(url)
# ① 将页面源码(参数1)交给bs4处理,得到bs4对象;参数2说明传入的是html,使用html.parser解析
bs4 = BeautifulSoup(resp.text,"html.parser")
# ② 定位 <div id="articlecon" 部分,标签(参数1)是div,属性(参数2)是id="articlecon"
# 如之前所说,属性可以有多种写法:
# 非关键字写法:
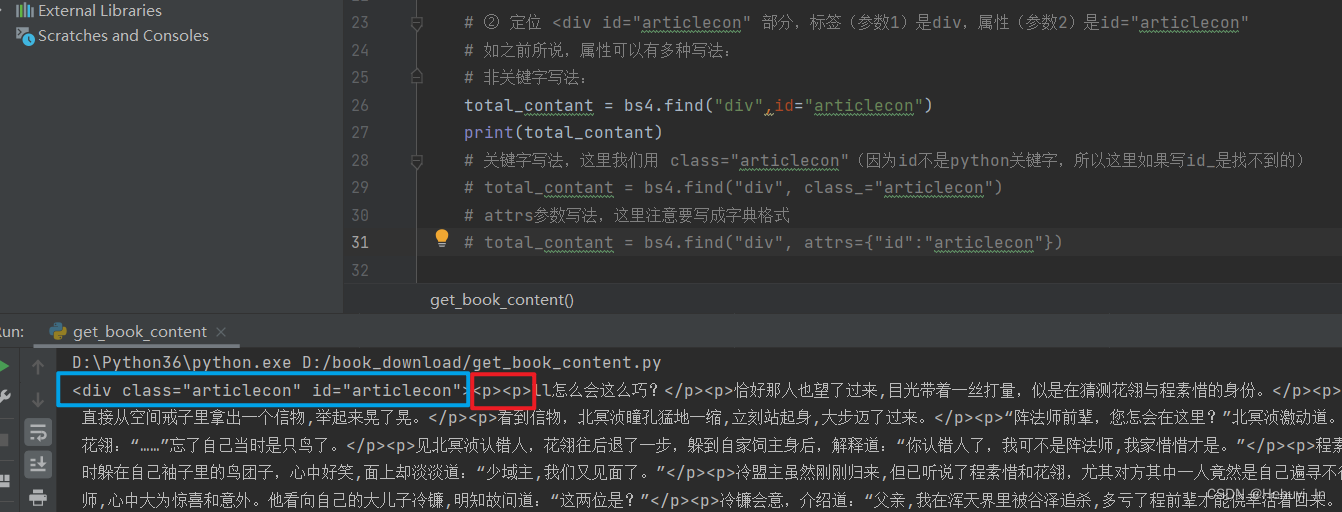
total_contant = bs4.find("div",id="articlecon")
# print(total_contant)
# 关键字写法,这里我们用 class="articlecon"(因为id不是python关键字,所以这里如果写id_是找不到的)
# total_contant = bs4.find("div", class_="articlecon")
# attrs参数写法,这里注意要写成字典格式
# total_contant = bs4.find("div", attrs={"id":"articlecon"})
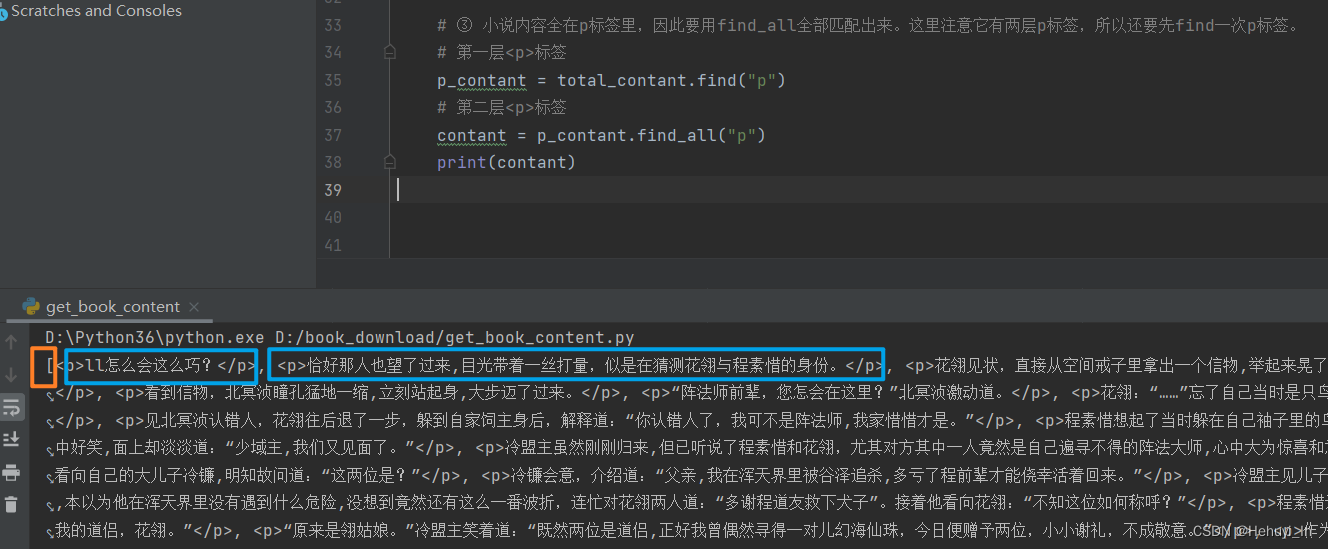
# ③ 小说内容全在p标签里,因此要用find_all全部匹配出来。这里注意它有两层p标签,所以还要先find一次p标签。
# 第一层<p>标签
p_contant = total_contant.find("p")
# 第二层<p>标签
contant_list = p_contant.find_all("p")
for contant in contant_list:
f.writelines(contant.getText()+'\n')
f.close()
if __name__ == '__main__':
conf_file = "url_list.txt"
book_name = "我在仙宗当神兽.txt"
url_list = get_book_url(conf_file)
get_book_content(url_list,book_name)补两个视频中的截图,暂时还没测这两个例子。一个抓表格数据,一个抓图片。
笔记-抓取表格数据
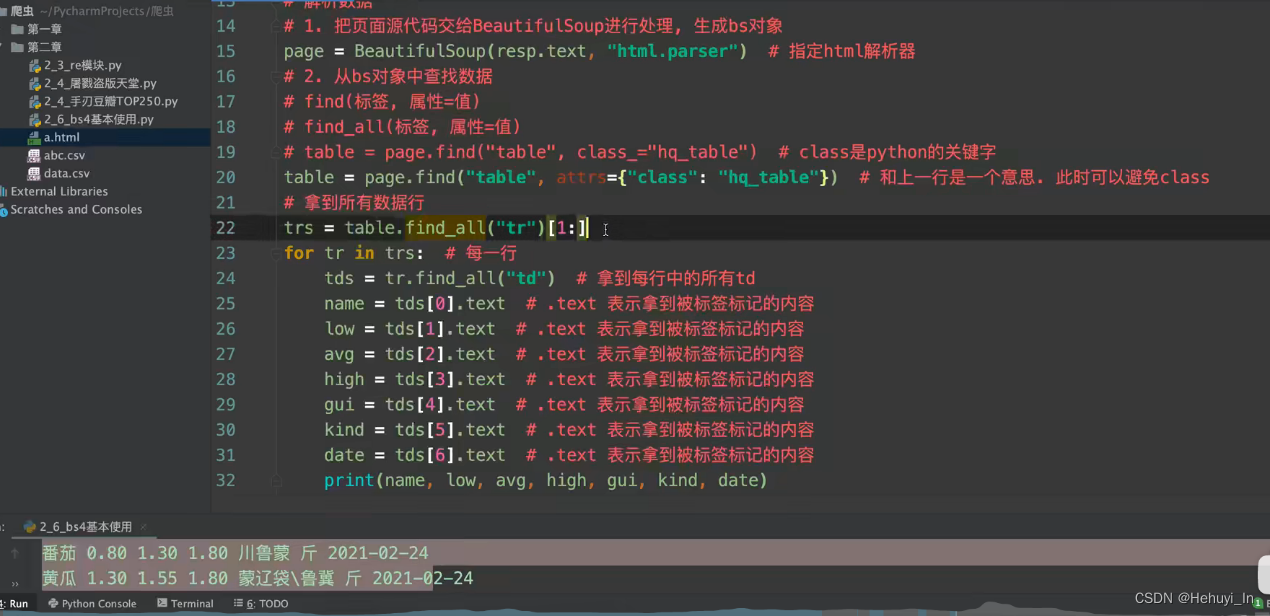
图片抓取:进主页,抓子页面高清图片
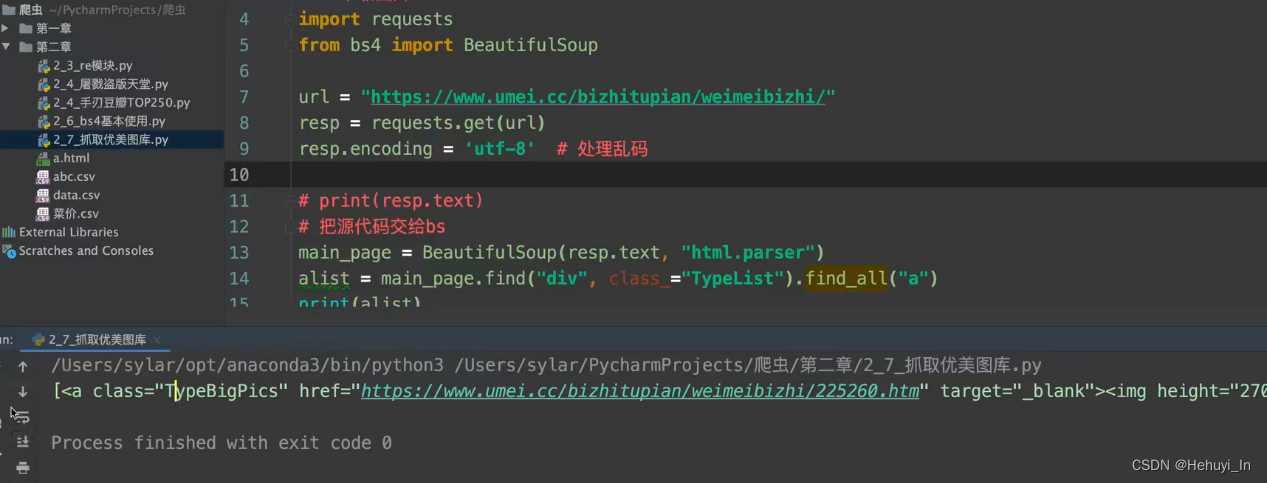
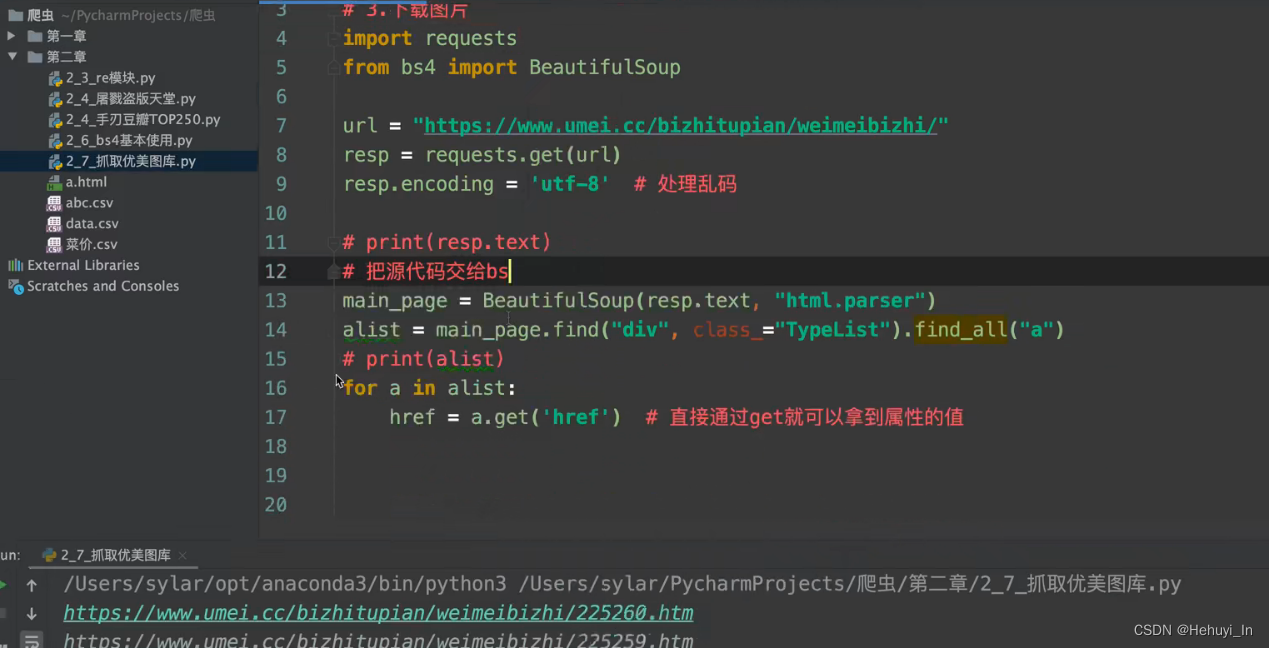
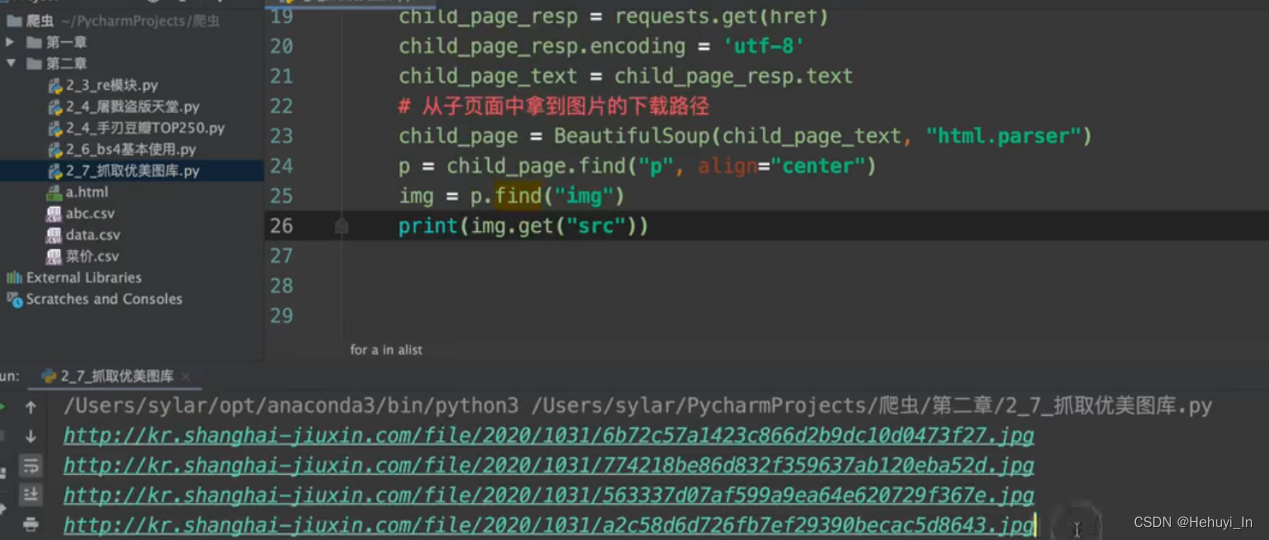
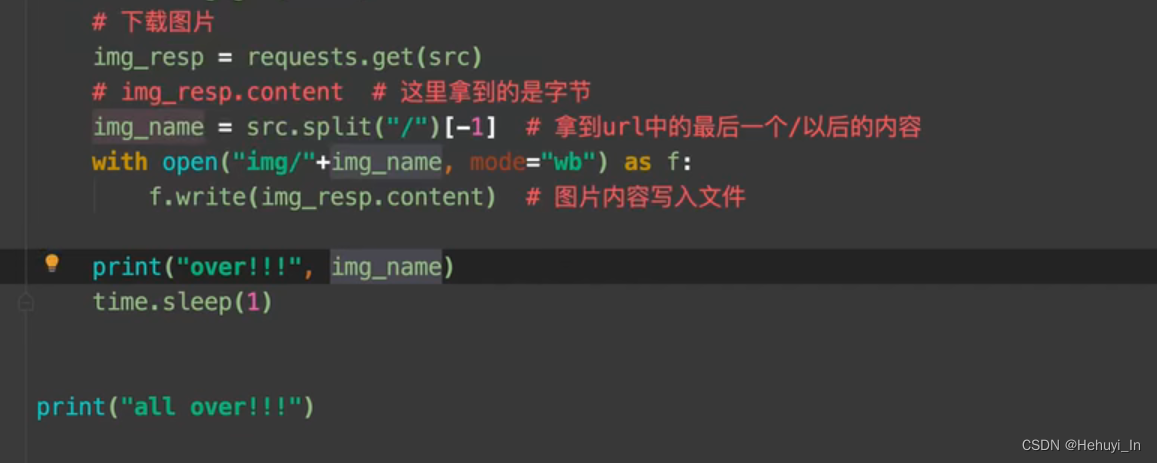
参考:B站视频 P28-P32


















 5万+
5万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











