







端到端的神经网络模型:
将原始数据作为输入,即词嵌入向量作为神经网络的输入,经过神经网络模型得到输出,输出与实际结果对比,得到误差,通过反向传播,调整模型参数,直至模型收敛,在输入与输出之间,整个神经网络是一体的(当做黑盒子来看待),即为端到端的模型。整个过程不再需要词性标注、句法分析、语义分析等多个子任务,每个子任务的结果会影响到模型的输出结果,就是非端到端的。
序列到序列的模型:
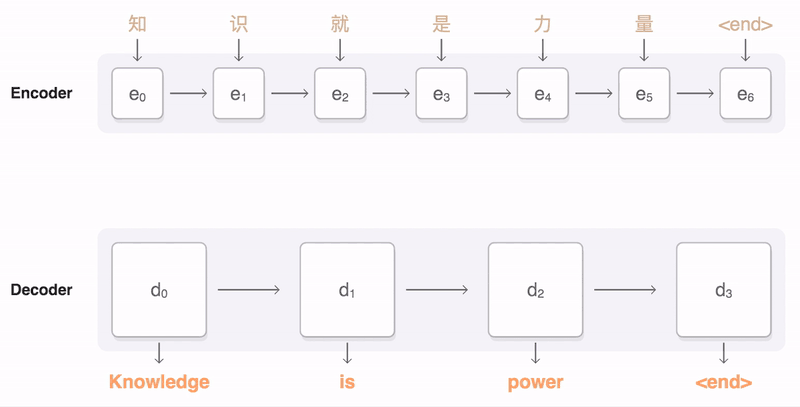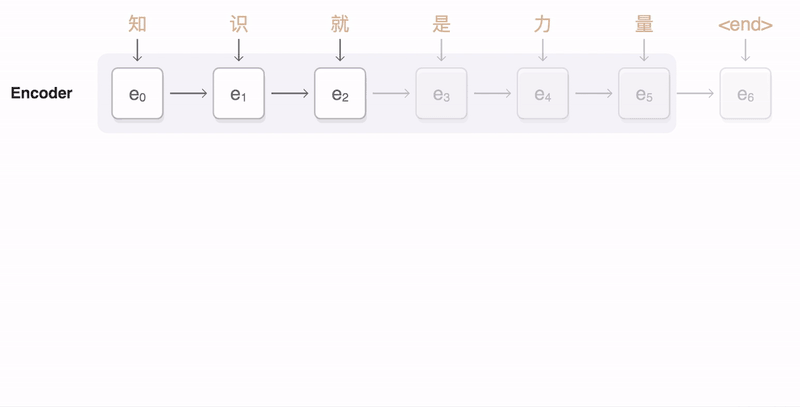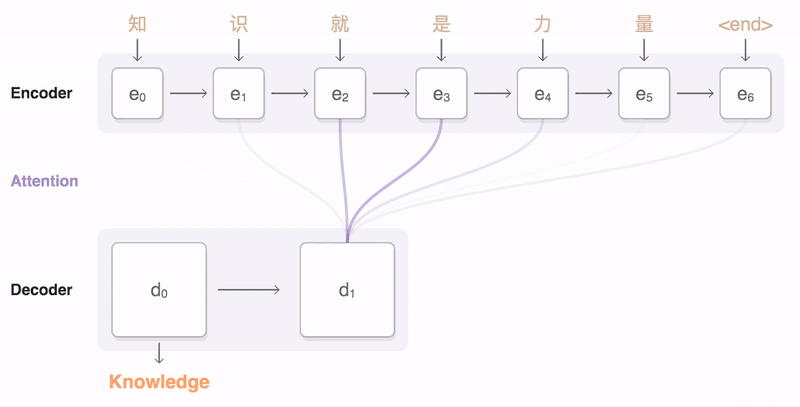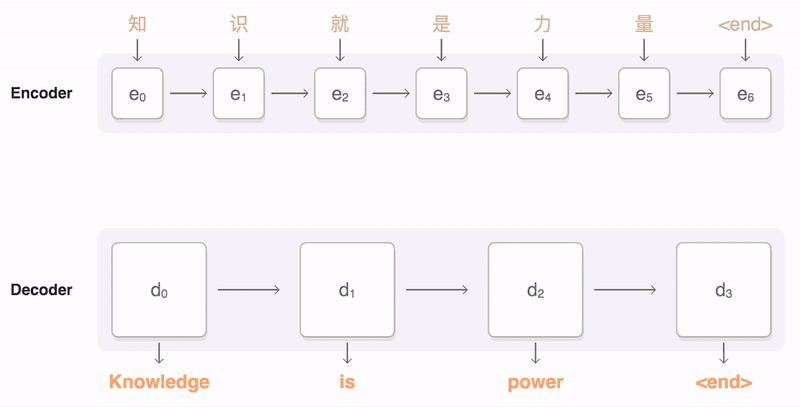
词嵌入得到词向量,在通过encoder(编码器)得到上下位张量,将context输入到解码器,产生输出。(就是两个RNN模型,一个RNN作为解码器,将词向量输入得到上下文张量作为编码器的输入,编码器则是另一个RNN)针对seq2seq,谷歌已经在TensorFlow中发布了tf-seq2seq框架。

















 711
711











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











