







怎么选特征?
选什么特征?
A Partition Filter Network for Joint Entity and Relation Extraction
就是,实体识别一个表,关系识别一个表
但是特征选的好呀!
A Partition Filter Network for Joint Entity and Relation Extraction
总括:
这篇文章是认为联合编码和单独编码的效果其实都不是最好的,单独编码就得不到两个任务之间的关联,但是联合编码又会使得向量不能很好的用于每个任务,存在冲突问题。因为,作者提出了一种新的编码机制,虽然还是成为联合编码,但是,针对每一个neuron分给了两个部分,一是用于NER,二是用于RE,具体的是这个图,可以形成三个部分,两个任务单独的和共用的部分
我觉得这篇文章很好,也是更好了抽取了每个任务的特征!!
这篇文章对于李丹琪他们认为的单独编码中,提出的关系特征对于实体预测无帮助提出了质疑,认为是有帮助的!--------------在做分析时,分析了三元组之内的实体和三元组之外的实体的抽取效果

背景:
作者在描述编码策略时,分为了两种, 一是**序列式编码,任务相关的特征按顺序产生,先前的特征不会被后来的特征所影响。二是并行式特征,**特定任务的特征是使用共享输入独立生成的,因此,不需要考虑编码顺序。但是,NER和RE的交互都没有很好地表现出来。
文章思路:
joint encode :分区过滤编码器:
采用的RNN编码器,利用了其时间序列的特性,在每一个时间点的神经元,根据每个任务对神经元分区( NER gate、RE gate),得到每个任务相关的特征,在找到shared 特征。-----尽可能是任务内的信息适应于自己的任务,远离相反的任务,减轻任务之间的负迁移问题。
具体操作:分区:对于一个神经元而言,t时刻的神经元的状态为:
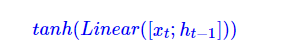
LATEX:\begin{equation}tanh(Linear([x_{t};h_{t-1}]))\end{equation}
NER和RE gate的计算,是采用cummax计算,binary gate[0,0,0,…1,1]这种,表示留谁舍谁。
论文中是这样解释的,但是,你要在确认下!
两个门:
整个神经元被分为了三个部分,一是实体部分,二是关系部分,三是共享的部分,每个部分的表示为:
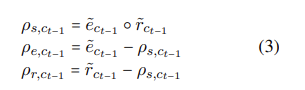
三个部分的表示为:

得到三个部分表示后,过滤。
过滤是分为三个块完成的,NER、RE、共享块。分别表示为:
µe = ρe + ρs; µr = ρr + ρs; µs = ρs
做tanh激活,得到每个块的特征表示,
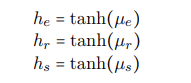
三个块的特征表示,用来形成t时刻RNN的hidden state,
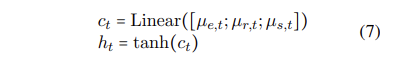
以上就是一个神经元的状态更新过程。
一个句子的实体表示和关系表示为:全局表示

任务模块
实体识别和关系识别,都是在一种类型下的表填充问题,即针对每一种实体(关系),识别实体的span(实体对的关系类型)
**实体识别:**采用word level 的表示和sent level的表示特征,预测每种类型实体跨度是否为实体

关系识别:实体对是都表达了该关系。

loss 函数
采用BCE

A Novel Global Feature-Oriented Relational Triple Extraction Model based on Table Filling
这篇文章,我暂时(暂时哈)还没有感觉到特出彩的地方,不过,也确实是统一了 表示,但global特征的学习上,我目前觉得,没啥特大依据,就是矩阵的运算!
总括:
一是新的表示方式,二还是特征的获取,怎么得到关系和实体对的更细粒度的特征表示
表填充问题:表用来指明实体对之间是否传达了某种关系,但多依赖于实体对本身的特征,忽视了实体对全局特征和关系全局特征--------这是出发点!
大体流程是:是对初始的表的特征分为某关系下的sub和某关系的obj的特征,对这两个表格特征微调,然后作为最终抽取三元组的表特征。
具体细节为:
**(1)表填充的形式:**a table table R (the size is n × n)
the label set as L = {“N/A”, “MMH”,“MMT”, “MSH”, “MST”, “SMH”, “SMT”, “SS”}.
第一个M表示subject是multi words,第二个M表示object是multi words,第三个表示是head还是tail
比如,MMH," means wi is the head token of a multi-token subject and wj is the head token of a multi-token object
**(2)整个模型分为四个模块,**一是encode,二是TFG----tabel feature generation,三是GFM,global feature mine,四是TG,triple generation。
- 在TFG中,生成每一种关系的表特征表示,采用哈达玛积,

对sub和obj的向量表示做多层感知机。
- 在GFM中,分别得到sub和obj的表表示特征,采用两个独立的感知机。TF_t
之后采用多头注意力机制,对TF_t做处理,作为t时刻的sub和obj的表表示特征,
然后,结合句子表示特征,得到t+1时刻的H表示,

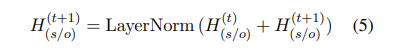
OK,这里又可以作为TFG的输入,去迭代,做feature的微调了!重复几步。
- 最后就是TG模块,解码生成三元组的。解码算法是对于multi的分为从头和从尾开始两步,single的一步,最后做的并集。
loss函数的设计
是采用-log p.
Joint Entity and Relation Extraction with Set Prediction Networks
这篇文章最主要的就是考虑了三元组的抽取顺序的弊端,对于顺序敏感的交叉熵损失函数是不适合计算set和set之间的损失的,提出了二分配损失函数
总括:
在使用交叉熵计算损失时,会受到顺序的影响,不同顺序下的loss不同,因此,提出非自回归编码器的策略,设计了二分配损失,计算预测集合和真实集合之间的loss
作者的出发点是认为在当下三元组的预测,多是转为序列的形式完成的,比如seq2seq,是有顺序的生成三元组,但实际上,三元组是无序的,是一个集合,另外,cross entropy loss 他们认为利用了顺序小的变化,不适用计算set和set之间的损失。(交叉熵是一个对置换敏感的损失函数,其中每预测出一个位置的三元组都会产生一个惩罚。cross-entropy is a permutationsensitive loss function, where a penalty is incurred for every triple that is predicted out of the position)
背景:
先说明一下:自回归编码器是从左到右的预测,类似于人写句子的顺序,非自回归则同时产生,没有顺序,并行。
他们认为在联合任务中,可主要分为三个流派,一是端到端的表填充问题,二是序列标注问题,三是序列到序列的model。
这篇文章的大致流程是:sentence编码,然后非自回归编码器产生三元组集合,最后二分配损失,计算predict set和TRUE set之间的损失。
具体流程:
sent encode:bert model
非自回归编码器:是采用多个transformer垒起来的,query是初始化的,query的个数是初始设定的,表示triple的最大个数,然后,通过四个前向网络,输出预测的三元组。
整个架构为:

每个三元组预测:
关系预测:\begin{equation}p^r=softmax(W_{r}h_{d})\end{equation}
实体预测:\begin{equation}p^(s-start)=
softmax(v_{2}^Ttanh(W_{1}h_{d}+W_{2}H_{e})\end{equation}
h_{d}表示非自回归的结果,H_{e}表示bert的结果
二分配损失:
分为两个step,一是最优匹配(伯努利算法——男女配对问题),二是计算loss(log(p))。
实验:回答问题:
(1)SPN的总体效果如何?
(2)SPN对于不同overlap的三元组的效果如何?
(3)SPN在不同数量的三元组的句子上,预测效果如何?
两种loss的对比:

Knowing False Negatives: An Adversarial Training Method for Distantly Supervised Relation Extraction
总括:这篇文章是远程监督领域的,主要是对FN问题,首先,利用神经网络记忆的特征过滤出positive的FN实例,认为他们是无label的,之后采用对抗训练的方式,尽量让所有数据的分布趋近相同。
整体流程:
一是挖掘:过滤掉FN的实例中的positive FN sample,认为他们是无标签的。
二分类问题,一是T,二是F

二是匹配:将第一步的无标签数据和train data中已对抗训练的方式匹配数据特征的空间分布
loss是多个任务的loss之和。
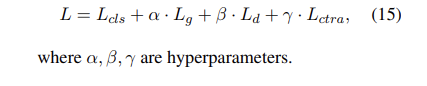
L_{CLS}表示bag的关系分类损失
L_{g}表示对抗训练中generator损失
L_{d}表示discriminatory 损失
L_{ctra}表示实例相似度损失,(
given two instances, their similarity
score should be high if they belong to the same relation and low otherwise. We use the contrastive loss
(Neculoiu et al., 2016) for this objective
)

















 3068
3068











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











