







Continual Few-shot Relation Learning via Embedding Space Regularization and Data Augmentation
看上去似乎有些难,这篇文章做的工作不少,工作量感觉不小。
任务范式:
few shot 下的continual relation extraction
核心:
- 提出了数据增强的方法
- 提出了几种新的loss函数
但是不管如何,CRE的核心问题在于灾难性遗忘,因此,这是研究的出发点。
前人回顾
现有的解决catastrophic firgetting问题的方法,大致可以分为三种:
- 基于正则化的方法(不太熟悉)
- 基于模型结构的方法(在模型结构上做修改)
- 基于记忆的方法(比如,把所有的训练数据都存储起来,用在下一个任务中)
作者给出的共同点是这些任务都使用了丰富的有标记数据作为训练样本,但这与实际情形并不相符,不能快速迁移到新的场景下。
文章核心
任务定义
文章给出的是CFRL(continual few shot relation learning),给定义一序列的任务,T=[T1,T2,…Tn],然后,对于T1是假设有较多的训练数据,对于之后的任务都假设是在小样本场景下进行的。
在评估时,是在k个任务之前的所有的test dataset上做评估,不是只对当前任务k做评估。
为了应对遗忘问题,提出数据增强策略,但只对每个relation type选择最相关的一个sample。
过程
- 编码
编码的关系和句子----LSTM、BERT
- 学习新数据
在每个任务中,在expand data上做微调,损失函数是L-ce=cross entropy loss。之后,提到为了让label 和input sentence的label接近,提出了两个新的损失函数。
margin-base loss和multi-margin loss:

所以,学习新任务的总损失函数:
L-new=L-ce+L-mm+L-pm,三个损失的权重,在文章附录中给出了说明。
- 选择sample存放在memory中
具体是先将每个label为r的句子计算一个平均表示向量,然后,选择距离这个向量最近的句子作为存放在记忆中的sample。
- 为了避免遗忘,提出了负例的构建方法
将positive sample的头实体或者尾实体进行替换,对应的损失函数L-constrastive=Lcon,如下,目的是让模型区别有效的关系还是无效的关系。
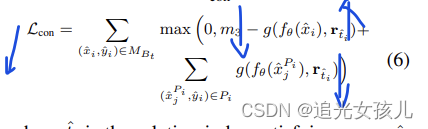
所以,总的loss-memory=L-ce+L-mm+L-pm+L-con
- 推理阶段
在推理阶段,选择具有高相似度的分值
- 小样本数据增强策略
1.实体匹配,对于维基中的数据,选择实体对相同的句子,之后计算句子相似度分值,给定一个阈 值,高于该阈值,则句子被选中。
2.相似度查询,选择最相似的前k个句子
3.相似性模型,构建正负例样本,正例,实体对相同,负例,单个实体相同,然后,损失函数如下:
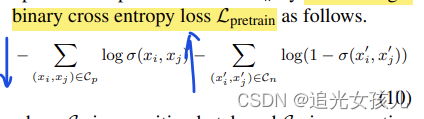
目标是:实体对相同的句子的相似性大于单个实体相同的句子的相似性。
总结
看他们的论文,baseline这一点,要不加上,
整个感觉有料,但感觉有点绕。
Improving Relation Extraction through Syntax-induced Pre-training with Dependency Masking
核心
句法依赖关系不是显式给出的,而是让模型去学习。
在encoder部分,训练模型去学习句子的依赖关系,从而,使句子获得这种能力。具体来说,语法诱导编码器是通过在第一、第二和第三或 ders 中恢复掩蔽的依赖连接和类型来训练的,这与现有的通过预测上下文词来训练语言模型或词嵌入的研究有很大不同沿着依赖路径。
模型图
1order 表示一步就可以实现;
2order表示两步才可以实现;
3order表示三步才可以建立关系。
con masking 表示connect masking
type masking 表示type

所以,根据上图,可以观察到,不管几order ,建模形式都是三元组的形式,即(xi,xj,type)。

流程
是先训练encoder具有依存句法解析的能力,然后,再用预训练好的模型,去做RE任务。
- 注意,文章的parser结构,使用现有的tool做的,Berkeley Neural parser.
- 方法通过掩蔽依赖预测将其引入预训练过程来利用依赖信息,其目的是预测掩蔽依赖,而不是通过附加模块直接将其作为额外的固定输入与输入句子一起使用
















 439
439











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











