







标题:利用门控卷积递归网络学习时空嵌入,以进行翻译起始位点预测
期刊:Pattern Recognition
分区:SCI一区
摘要
从基因组序列中准确预测翻译起始位点(TIS)对于理解基因调控和功能至关重要。TIS预测方法的特征向量没有足够的鉴别性,从而导致不令人满意的预测结果。在本研究中,我们设计了一种具有残差学习功能的高效门控卷积递归网络(GCR-Net),以一种有效的融合策略动态提取原始基因组序列的依赖模式,并成功地提高了TIS预测的性能。GCR-Net主要包括指数门控卷积剩余网络(EGCRN)和双向门控递归单元(Bi-GRU)网络。特别地,我们设计了新的EGCRN来从基因组序列中提取空间维度的多个复杂模式,其中我们设计了一个指数门控线性单元(EGLU)来减少消失梯度问题。此外,我们将EGLU与shortcut connections结合起来,开发了基于卷积的堆叠门控机制,有利于信息跨层传播。然后,我们使用具有identity connections的Bi-GRU从基因组序列中学习时间维度的长期依赖模式。此外,我们在4个TIS数据集上对我们的GCR-Net模型进行了评估,实验表明GCR-Net是一种有效的基于深度学习的TIS预测工具,与基线方法相比获得了优越的性能。
介绍
基因组注释有助于理解基因调控和表达的复杂机制,而翻译起始是调控基因表达的关键过程。翻译过程从带注释的翻译起始位点开始,也可能始于多个备选的翻译起始位点(TIS),其中包括AUG非AUG密码子。从基因组序列中预测TIS是研究其潜在调控机制的一项具有挑战性的任务。翻译起始是许多生物过程中的一个关键活性,包括基因表达和蛋白质合成。独特的蛋氨酰tRNA识别AUG起始密码子并触发下游翻译。启动阶段的失调经常导致癌症和代谢紊乱。代测序技术的发展使序列数据呈指数级增长。然而,翻译起始的潜在机制是非常复杂的,识别TIS是耗时的而且通过生物实验也很昂贵。因此,近年来发展了各种利用计算算法自动检测TIS的方法。
基于机器学习的算法已被广泛应用和成功的提取生物和医学数据模式的方法。然而,手工制作的基因组序列特征需要大量的经验知识来预测TIS,而TIS预测算法的一个热点编码特征往往忽略了序列的共现信息。复杂的手工制作的特性和生物特性并不总是可用的。在基因组序列的数据挖掘和知识发现中,它们有时很难获得,而且它们的预测算法并不能完全提取生物序列隐藏的关键特征。事实上,一些著名的算法(如支持向量机、隐藏马尔可夫模型、贝叶斯网络和神经网络)已经成功地应用于基因组学、蛋白质组学和其他领域的。机器学习算法的性能在很大程度上依赖于原始数据特征表示技术,其中特征通常由具有广泛领域专业知识的复杂特征工程设计。深度神经网络(DNN)作为机器学习的一个重要分支,最近出现了基于大数据、并行和并行的力量分布式计算,并在情绪分析和图像处理方面取得了显著的效果。因此,我们探索了一种上下文特征学习算法,通过提取基因组序列的时空嵌入来进行TIS预测。
为了应对这些挑战,人们努力建立有效的计算模型。然而,考虑时空背景对TIS预测过程的复杂影响仍然是一个挑战。研究人员开发了一些TIS预测方法,现有的方法主要包括扫描模型、传统的机器学习方法和基于DNN的方法。现有方法面临的挑战包括:1)扫描模型除非已知,否则不能直接应用于基因组序列;2)真核基因组包含许多候选TIS,目前的模型需要复杂的手工特征,如核苷酸的组成和统计特性;3)生物学特征并不总是可用,不能完全反映基因组序列的内在模式;4)DNN-based的TIS预测方法在训练过程中容易遇到一些梯度问题。基因组序列数据通常以个体kmer外观的形式携带大量的依赖信息。为了提高TIS预测的性能,有效地提取依赖模式是DNA\RNA序列中一个重要但长期未解决的问题。将各种生物和生物医学数据转化为有价值的知识一直是生物信息学和医学信息学中最关键的挑战之一。
为了弥补TIS预测方法的不足,我们将TIS基因组序列划分为k-mers,然后根据序列间k-mers的共现矩阵进行预训练k-mer嵌入向量。然后,我们设计了一个门控卷积递归网络(GCR-Net),以端到端的方式准确地预测TIS。因此,在大规模TIS序列数据上的大量实验表明,我们的方法优于其他TIS预测方法。我们的GCR-Net主要包括数据初始化、EGCRN模块、Bi-GRU模块和预测器。本文的贡献主要包括:
1)通过集成门控机制和shortcut connections连接,我们设计了一种有效的表示学习模型,称为门控卷积循环网络(GCR-Net)。该模型可以获得基因组序列的时空表示,并能准确地进行TIS预测。
2)我们设计了一个指数门控线性单元(EGLU)来捕获基于卷积和门控机制的多个复杂模式。此外,我们将EGLU与GRU连接集成,设计了指数门控卷积残差单元(EGCRU),这有利于信息在残差块之间的传播。在梯度消失问题的训练过程中得到了很大的缓解,模型的训练过程比网络收敛得更快。
3)我们通过EGCRU设计了指数门控卷积残差网络(EGCRN),以增强基因组序列的多种局部相互作用模式,同时保留了序列数据的非线性表示。此外,将Bi-GRU网络作为非线性转换块插入到残差块中,从基因组序列中学习长期依赖关系。通过身份连接可以缓解梯度退化问题,模型得到了所需的底层映射函数。
本文的其余部分组织如下:在第2节中,我们介绍了关于TIS预测的相关工作。在第3节中,我们将详细介绍我们所提出的模型的细节。第4节试验实验和结果。分析和讨论详见第5节。第6节总结了这个结论。
相关工作
高通量测序技术为研究翻译起始的一般原理提供了大量的数据。由于生物实验成本高,一些计算方法已成功地应用于TIS预测任务,降低了实验成本和生物实验工作量。此外,计算技术在很大程度上依赖于原始数据的信息特征向量,而现有的工作主要关注于利用核苷酸的组成和统计特性来提高TIS预测的性能。
虽然已经获得了令人印象深刻的结果,但特征表示方法倾向于使用局部核苷酸酸模式来生成候选特征。共现信息可能有助于TIS的预测。此外,本研究采用单热编码技术对核苷酸进行编码,对应位置为1,其他位置为零。此外,基于嵌入的应用的显著结果进一步为提高TIS预测的性能提供了独特的研究视角。端到端学习方法是语言建模和图像处理中的一种强大的特征学习工具,特征学习过程主要包括: 1)在低维实值向量空间中嵌入单词等离散输入符号;2)考虑数据结构设计不同的神经网络;3)通过反向传播学习大量的网络参数。
因此,在考虑TIS基因组序列的鉴别表示的同时,基于深度神经模型的TIS预测任务仍有改进的空间。此外,k-mer出现的统计量是基因组序列嵌入表示的主要信息源,k-mer被定义为TIS基因组序列的k个连续核苷酸。在本研究中,我们通过嵌入算法直接从TIS序列中提取全局统计信息,并生成k-mers的上下文信息。
各种基于DNN的建模方法已被应用于许多应用,DNN为TIS预测做出了重大进展。例如,Zhang等人开发了一个混合神经网络框架,通过整合卷积和长短期记忆(LSTM),在全基因组范围内准确预测TIS。Zuallaert等提出了一种深度卷积神经网络框架,利用多层卷积来提高TIS预测的有效性。卡尔卡塔维等人提出了一个全面的神经网络框架,用于识别真核生物DNA序列中的各种基因组信号。Wei等人设计了一个混合依赖网络和深度学习框架,它明确地模拟了编码区和翻译起始位点之间的编码区之间的标签依赖关系。上述工作表明了DNN在准确预测TIS方面的优势。尽管如此,现有的深度模型通过增加模型的深度或宽度,大大提高了性能,这导致了大量的参数,消耗了更多的计算能力和时间。此外,基于DNN的模型难以训练,对输入敏感,由于使用深度、复杂的网络设计,优化工具往往具有挑战性;因此,损失函数的梯度经过许多深层后往往逐渐变得不准确。
此外,基于DNN的正则化技术,包括批归一化(BN)和droput,经常用来快速收敛和避免训练过程中的过拟合问题。然而,鲁棒正则化方法(例如,辍学)会增加学习过程的方差,然后进一步导致差异。此外,在训练过程中,梯度的消失和爆炸也阻碍了网络的收敛。幸运的是,残差神经网络已经被提出,通过shortcut connections来解决退化问题。门控通积网络设计通过训练过程中对梯度的线性路径来减少深度网络的消失梯度问题。因此,我们提出了新的GCR-Net模型,将有用的k-mer共现信息与最近的生物序列数据的神经计算算法结合起来。
方法
方法构建
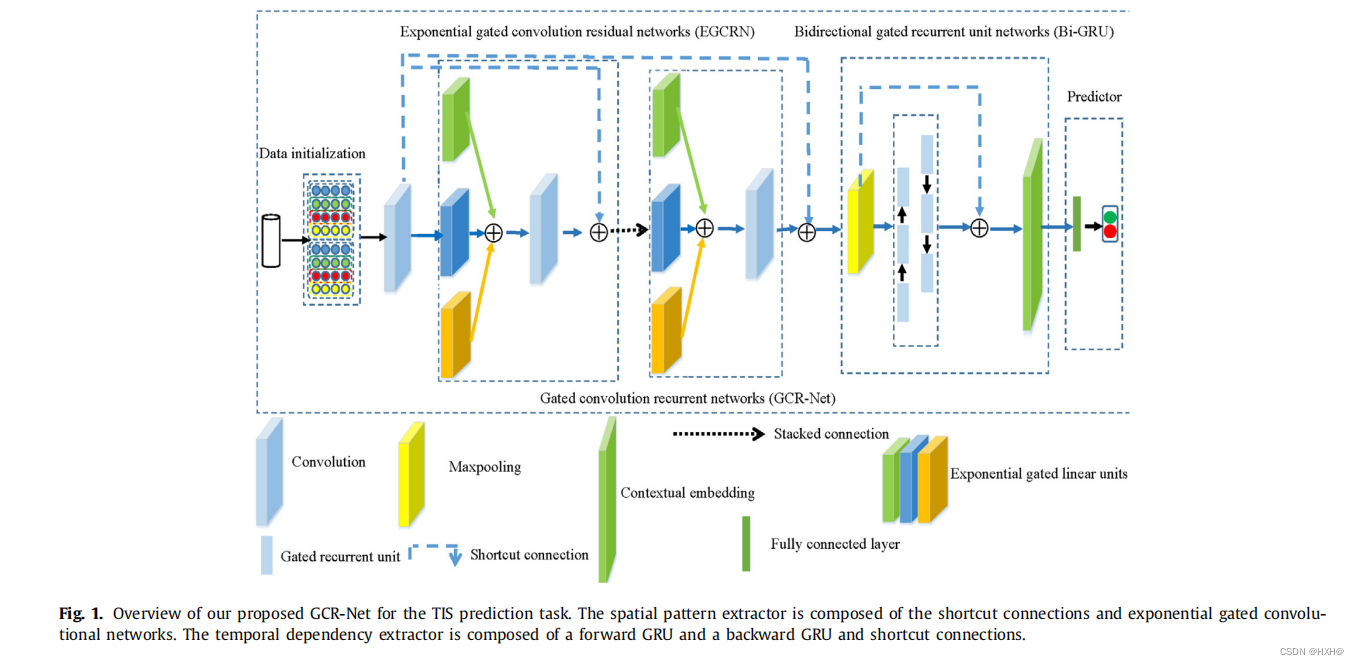
GCR-Net包括数据初始化、堆叠的EGCRN、Bi-GRU和预测器。EGCRN由EGCRU和EGLU组成,如图所示。1和2。图1为GCR-Net的体系结构,图2为EGCRU和EGLU的体系结构。设计了第一个k-mer初始嵌入块,通过嵌入矩阵将k-mer索引的基因组序列转化为密集的特征向量。每个特征都被链接到一个密集的向量上,以实现分布式表示。然后,我们设计了EGCRN来提取基因组序列的多种空间模式,并使用Bi-GRU来建模基因组序列的长期依赖模式。此外,一个全连接(FC)层被用于集成具有长期依赖关系的多个模式。我们的模型使用信息性的基因组序列嵌入来预测TIS的可能性。时空嵌入用我们的GCR-Net表示为H,用我们的GCR-Net的特征学习表示为:

其中,X表示原始输入序列的初始嵌入。是一个元素级的加法操作。fEGCRN()表示我们的EGCRN的建模功能。fBi−GRU()表示Bi-GRU的建模函数。fBi−GRU和fEGCRN的输出是一个序列的特征矩阵,并且输出的维数相等。fFC()表示FC的建模功能。RBi−GRU是长期依赖特征,而REGCRN是多尺度空间格局特征。
门控卷积机制可以减少消失的梯度问题,门控递归单元比简单的递归神经网络可以更好地处理梯度问题。因此,我们设计了指数门控卷积机制,以获得更多的信息在残差块间传播,避免梯度问题。在残差网络的激励下,我们引入了快捷连接来增强GCR-Net内的信息流,以提高TIS计算方法的预测能力,并将这些层重新表示为学习残差函数。这种identity connections既不引入额外的参数,也不会引入计算复杂度。在GCR-Net中,指数门控采用卷积残差网络(EGCRN)作为空间模式提取器,该提取器包括多尺度指数门控卷积和恒等式连接。我们使用带有identity connections的Bi-GRU作为时间依赖提取器来提取时间依赖模式。此外,在EGCRN和Bi-GRU之间还存在一个最大池化层。identity connections有助于不同层间的信息交换,缓解了梯度消失的问题。近年来,具有shortcut connections的深度模型被研究并用于各种任务。这种shortcut 既不引入额外的参数,也不引入计算的复杂性。对于残差块,特征和梯度可以反向传播到GCR-Net的另一层,残差块可以使更多的TIS信息从开始传递到结束。
如图1所示,在空间模式提取器和时间依赖提取器中使用了TIS预测的识别shortcuts。在残差块中,学习了从x到F(x,θj)的映射,而θj是与该块相关的一组权值。残差块的特征计算公式为:

这里的x和R分别是输入和输出的特征映射。F(x,θj)表示残差函数。
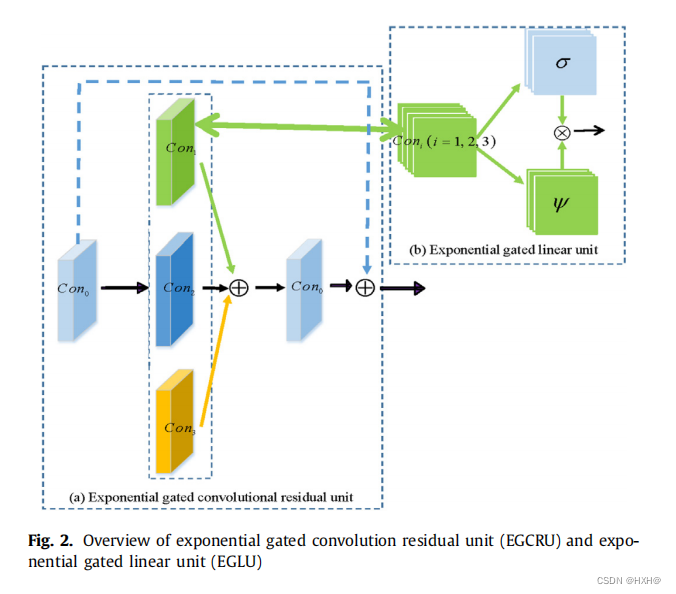
指数门控卷积残差网络
如图1所示,我们设计了EGCRN来提取TIS信号的复杂相互作用。EGCRN主要包括EGCRU、EGLU、shortcut connections,如图2所示。EGCRU包括多尺度门控卷积网络(GCN)和shortcut connections。GCN的输出公式表示为Oi GCN。对于GCN,前一个层的特征映射,通过卷积层实现,被分割为具有相同形状的特征mapXλi 1和Xλi 2。Oλi GCN是GCN与内核大小为λi的GCN的特性输出映射。ψ是一个指数线性激活单元。然后,利用Xi 2得到的非线性sigmoid,将Xλi 1的指数误差线性投影调制如下:
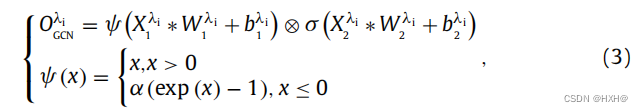
其中,等式的梯度计算(3)存在一个指数线性路径ψ(X)∇X,而没有降低控制单元σ (X)。该机制可以看作是改善模型梯度流的一种乘法连接。
GCN以简单的卷积映射ϑ(w1λi∗X + b1)作为输入。I表示门控卷积类型的数量,J为堆叠EGCRN的数量。ϑ是一个高斯误差线性单位,w1λ和w2 λ表示卷积权值。b1和b2代表偏差。∗表示卷积运算,λi表示第一次门控卷积的核大小。因此,堆叠EGCRN的输出RJ EGCRN表示为:
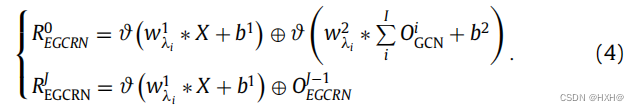
如图2(b)所示,我们的EGLU包含两个组件。第一个ψ()是指数线性激活单元分量,超参数α控制负净输入单元的饱和值。EGLU降低了消失梯度对模型性能的影响。第二个σ()是一个s型非线性激活分量,和输出值在0到1之间。与LSTM类似,门σ()将矩阵ψ()中的每个元素相乘,并控制在层次结构中传递的信息的比例。此外,EGCRU有一个通往底层的捷径,而不降低激活单位的比例。在保留
非线性能力的同时,降低了消失梯度。
双向门控循环单元网络
采用双向门控递归单元网络(Bi-GRU)作为时间依赖性提取器。GRU是LSTM 上的一个轻加权递归神经单元,它也能有效地处理梯度消失和爆炸的问题。因此,我们使用Bi-GRU基于EGCRN的输出嵌入来提取TIS序列的长期特征,如图1所示。为了融合长期特性RBi−GRU和局部特征REGCRN,Bi-GRU中每个k-mer的输出维数等于EGCRN的输出维数。隐藏状态ht在步骤t基于EGCRN输出的当前输入xt计算,前向上下文−−→ht−1和后向上下文←−−ht−1在步骤t的公式:
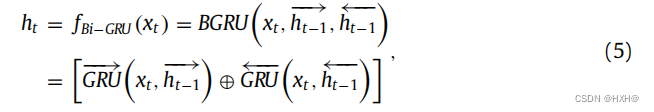
其中,ht−1表示之前的激活状态。时间依赖提取器的输出被表示为TIS信号的特征矩阵RBi−GRU=,h1,h2,…,hT]。
在GRU中,当前状态向量是根据之前的激活−1和候选激活的公式计算出来的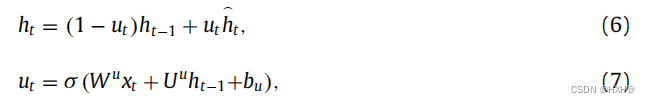
其中ut是更新门,σ是s型函数。候选激活和复位门rt由公式计算: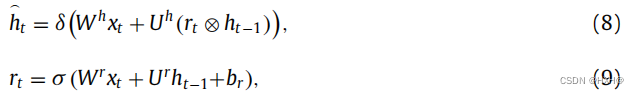
其中,δ()表示tanh激活函数,rt表示复位门。
预测
在GCR-Net中,该预测器由两个堆叠的完全连接层组成,可以提取时空特征之间的更高层次的交互作用。在形式上,该预测器的目的是过滤融合特征,以生成信息表示,并进行TIS的数值预测。将整个过程的嵌入特征输入到一个具有softmax功能的全连通层中。其预测结果如下: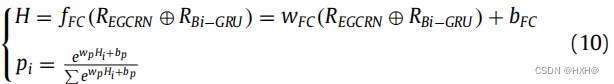
其中,N表示序列的个数,yi为实际的标签。W和b为预测器模块的参数。υ表示softmax函数。对于GCR-Net,损失函数ς为实际标签yi与标签的预测可能性pi之间的最小化如下: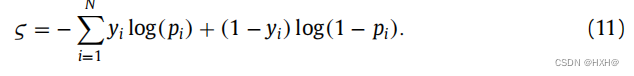
实验和结果
本节介绍数据集表示、实现和评估指标以及实验结果。
数据集和表示
数据集
为了验证该模型的性能,我们在人类、小鼠、牛和果蝇的TIS数据集上评估了所提出的模型。这些数据集是由卡尔卡塔维等人。分别从国家生物技术信息中心、加州大学圣克鲁兹分校的基因组浏览器、哺乳动物基因收集、FlyBase 和集成资源中提取的。利用人和小鼠各自基因组的cDNA数据提取它们的TIS,并从其注释文件中提取牛和果蝇的TIS。假TIS数据的数量等于所确定的信号,并从gc含量平均值与全基因组平均gc含量最接近的染色体中提取。
具体来说,以cDNA数据和注释文件为起点,提取出与蛋白质编码基因相关的TIS。然后,根据基因组定位和比对程序,将起点数据映射回基因组。接下来,利用床工具确定了所考虑的TIS的侧翼序列,其上下游均有300个核苷酸,获得了不同TIS数据集的600个核苷酸序列。最后,分别获得了人类、小鼠、牛和果蝇的28244、25205、17558和30283个具有ATG信号的真实TIS数据
数据表示法
传统的基于k-mer的方法只是简单地计算k-mer频率的向量,而没有计算k-mers的共现关系。在本文中,k-mer嵌入特征是相对于在自然语言处理中广泛使用的“词袋”特征的一个类比。同时,k-mer共现矩阵包含全局统计信息,可以为TIS预测构建更好的特征表示。对于TIS的k-mer嵌入,我们训练了一个无监督的GloVe模型,基于来自不同TIS数据集的k-mers的共现模式,获得了所有k-mers的kmer嵌入向量。简单地说,我们首先生成每个生物体的k-mer语料库,它产生一个k-mer的词汇。然后,我们利用GloVe ,以无监督的方式训练和获得所有k-mers的共现表示矩阵E。k-mer共现计数矩阵表示为X,与GloVe模型一样,代价函数需要最小化为公式:
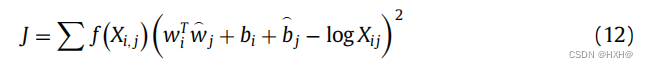
其中,Xij列出了k-mer j在k-mer i的上下文窗口中出现的次数。i和j是两个k-mer索引。w是一个期望的k-mer向量,而w是一个单独的上下文向量。b和b是特征学习的偏差。非递减加权函数f可以简化和参数化为如下公式:

其中,x∗表示初始嵌入学习过程的截止值,而β(β= 0.75)控制分数功率缩放。接下来,每个k-mer通过矩阵向量乘积为xi = m(xi)= E·ei转化为嵌入的xi,ei是词汇表中一个=-mer的索引向量。每个TIS信号序列被转换为特征矩阵X = [x1,x2,…,xN]。嵌入不需要复杂的特征工程,并代表了TIS信号序列的局部和全局交互模式。此外,它还提供了一种直接的方法来理解翻译起始的潜在调控元素。此外,我们将图3中GloVe学习到的每个生物体的k-mer嵌入向量进行了可视化,并展示了kmers的128维嵌入向量。从图3中可以看出,嵌入信息在每个维度上都相对分散,这是在TIS基因组序列上的一个良好的特征表示特性。这进一步表明了k-mer依赖关系的复杂模式和丰富信息的同时出现。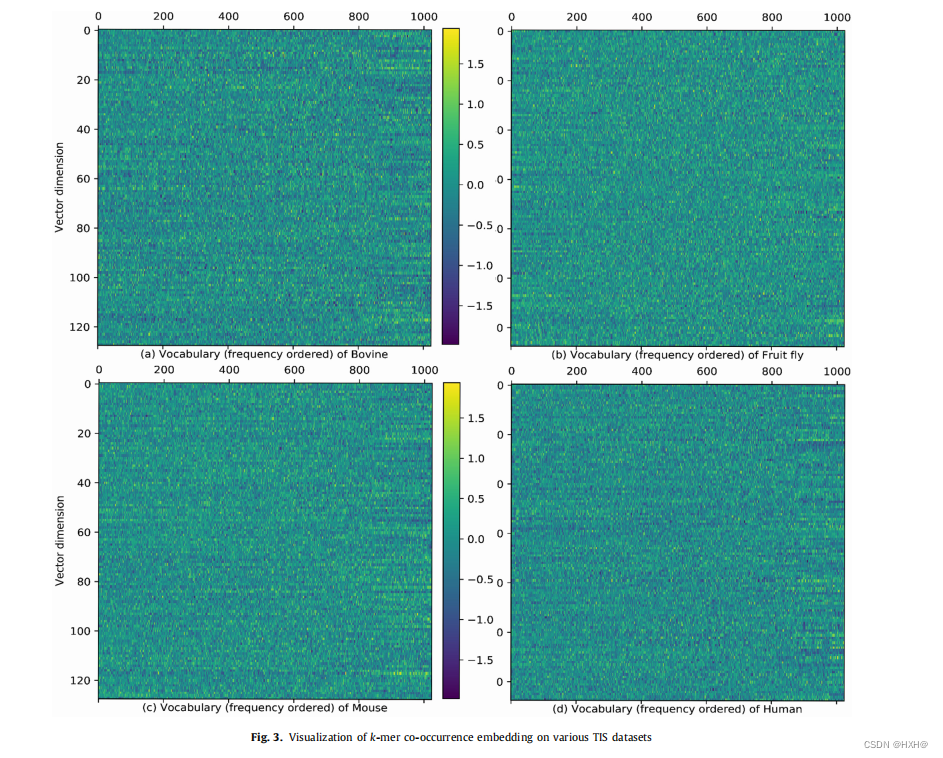
实现和评估指标
本节将介绍模型的实现和评估度量标准。
实现细节
与TIS相对应的基因组序列信号主要由核苷酸[13]的ATG三联体组成,在本研究中,我们将ATG三联体称为TIS基序,然后从基因组序列中进行TIS预测。我们的模型和基线模型是由开源库Keras实现的,它具有张量流的后端。在训练过程中,我们使用单一的GPU来加速学习过程,并受益于并行计算。对于TIS数据集,我们将TIS数据集划分为严格不重叠的训练数据集和测试数据集,比例分别为0.75和0.25。然后,我们随机选择0.20个训练数据集作为验证集。对于梯度下降优化,我们使用学习率为0.00003的Adam 优化器来最小化TIS预测任务的损失函数。对于正则化,我们在不同的块之间引入一个辍学层,并在GCR-Net中使用l2权值衰减进行门控卷积。网络权值由Xavier均匀初始化器进行初始化。如所示,较大的k-mer长度会减少语料库的大小,增加计算复杂度;因此,我们通过将k设置为5和1步幅来生成k-mers的语料库。
对于GCR-Net,我们将GCR-Net的训练期设置为200,TIS数据集的小批量大小设置为64。我们还在训练中使用了早期停止技术,当经过10个训练阶段后,在验证集上的损失停止减少时,训练将停止。在EGCRN和Bi-GRU之间的最大池化层的窗口大小为3。简单的卷积包含64个内核大小为3的滤波器,我们设计的门控卷积机制包括64个内核大小的滤波器(3、9和15)。所有的k-mer向量都表示为由GloVe 在一个大型TIS语料库上预先训练的12个8维向量。GCR-Net使用双向GRU,包括正向GRU和向后GRU。在GRU中,每一步输出空间的维数为64。如图1的标识符所示,它包含了两个完全连接的层。特别是一个完全连接层32隐藏是进行特征融合学习的时空模式信息获得信息嵌入表示基因组序列,和另一个与softmax激活函数用于预测TIS基因组序列的标签概率。
评价指标
在本研究中,我们在所有实验中都使用了平衡的TIS数据。因此,我们通过误差率(Er)和相对误差率来比较TIS预测与基线模型的实验结果(相对)。此外,我们进一步使用敏感性(Se)、特异性(Sp)、受试者工作特征曲线下面积(AUROC)和精确查全率曲线下面积(AUPRC)作为模型分析的附加指标。AUROC和AUPRC是根据真阳性率(TPR)和假阳性率(FPR)计算的。如参考文献[13,16,43]所示,评价指标的表述为: 其中x是特殊任务的方法。x1是一个基线预测器,x2是我们的TIS预测器。TP、TN、FP和FN分别表示真阳性预测、真阴性预测、假阳性预测和假阴性预测的数量
其中x是特殊任务的方法。x1是一个基线预测器,x2是我们的TIS预测器。TP、TN、FP和FN分别表示真阳性预测、真阴性预测、假阳性预测和假阴性预测的数量
实验结果
本节介绍了基线,并分析了实验结果。
基线方法
为了评估其有效性,我们比较了我们的模型与两种现有方法的性能。
1)经典方法
经典的预测方法通常使用从基因组序列中手工制作的特征,并比较它们的性能。我们选择了两种经典的方法作为基线来评估TIS预测任务的模型。
TISANN :基于本地特征,他们主要描述序列的属性立即候选人钛,Magana-Mora et al. 扩展这组特性与一些核苷酸影响从ATG主题网站150个基点。然后,他们使用遗传算法来寻找最优的特征组合,然后利用反向传播算法训练一个浅层的人工神经网络来进行TIS预测。iTISPseTNC 是一种基于序列的预测因子,利用伪三核苷酸组成序列来识别人类基因中的TIS。iTISPseTNC模型基于支持向量机、伪三核苷酸组成和物理化学性质,预测了TIS。
2)基于深度学习的方法
深度学习的显著优势是它具有强大的自动特征学习能力。我们选择了四种基于深度学习的方法作为基线来评估我们的模型的预测性能。
TITER是一个基于深度学习的框架,基于QTI-seq数据在全基因组范围内准确预测TIS。利用CNN和LSTM结合的混合网络,从TIS预测TIS周围的序列上下文中提取翻译起始的序列特征。
TISRover 是一种多层卷积结构,没有TIS预测知识。它使用多层CNN来学习生物学相关特征,以有效地预测TIS。
DeepGSR 是一种用于基因组信号和区域识别的优化深度学习结构。该架构依赖于适当的数据表示,以及基于堆叠的二维卷积网络的空间相关性的利用。
SAN 是一种基于深度神经网络的计算方法,用于识别人类和小鼠基因组中的Poly (A)信号。使用自注意机制和卷积网络不需要手动制作的序列特征。NeuroTIS 由双向递归神经网络和卷积神经网络组成,利用编码区域和TIS之间的标签依赖关系,可以有效地学习和推断TIS。
上述基于深度学习的方法基于单热方法编码的生物序列特征来识别各种TIS。
结果分析
为了验证GCR-Net的优越性,我们在TIS信号数据集上进行了广泛的实验,并将GCR-Net与具有竞争优势的基于深度学习的方法进行了比较。表1分别报告了在果蝇、小鼠和牛的TIS数据集上的Acc、Se、Sp和每个时期的平均运行时间的结果。星号算法的结果引用了参考文献,我们的实验得到了其他的结果。如表1所示,我们的GCR-Net始终超过基线方法。特别是我们的模型得到的性能为Acc评分4.77%,Se评分6.60%,Sp评分平均比基线高3.06%。此外,我们的GCR-Net的性能最好,Acc为96.14%,Se为96.49%,Sp为95.80%。平均而言,我们的GCRNet在水果数据集上改善最显著,Acc为5.14%,Se为4.41%,Sp为5.85%。

特别是,GCR-Net显示改善Acc得分1.36%,硒得分2.12%,Sp得分高出0.58%,Acc得分为0.31%,Se得分为0.56%,Sp得分比效度高0.04%,Acc得分为21.35%,Se得分为15.51%,Sp得分为27.23%,Acc得分为2.08%,硒得分为2.39%,Sp得分SAN1.75%高于果蝇数据集。
此外,为了获得公平的比较和分析,我们进一步描述了基于深度学习的方法在同一环境下每个时代的平均训练时间,这些方法是通过使用单一GPU(Tesla V100 SXM2 32GB)来实现和加速的。对于复杂性分析,从表1中,我们观察到,我们的TIS预测方法在每个历元的性能和平均运行时间之间获得了更好的权衡。此外,我们还提出了一个基于参数数量的比较分析。已发表的基于深度学习的TIS预测方法有许多参数,需要在训练过程中进行调整和训练。特别是DeepGSR、TISRover、NeuroTIS、滴度和SAN的数量参数分别为∼100M、∼200M、∼2M、∼0.6M和∼0.2M。这凸显了GPU加快特性训练过程的必要性。如表1所示,与显著的DeepGSR相比,我们的GCR-Net减少了训练时间,我们的GCR-Net的GCR-Net参数数量略∼1M。比滴度和SAN参数小,但远小于DeepGSR和TISRover。我们的GCR-Net获得了更显著的预测性能
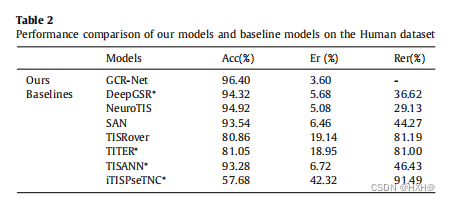
接下来,我们对人类TIS数据进行了案例研究,以进一步验证我们提出的GCRNet的鲁棒性和泛化性。表2显示了我们在卡尔卡塔维等人中使用的模型,模型和基线的性能。GCR-Net的性能最佳,Acc为96.40%,Se为96.70%,Sp为96.11%。我们的GCR-Net比其他预测模型获得了最好的性能。从结果比较中,我们观察到,我们的GCR-Net将人类数据集上的TIS预测的分类错误率降低了高达91.49%。与经典方法相比,GCR-Net的性能有所提高,Rer平均降低了68.96%。与深度学习方法[2,5,15,16,44]相比,我们的GCR-Net的性能提高,Rer平均降低了54.44%。iTISPseTNC和TISANN的表现比我们的GCR-Net要差,这表明基于深度学习的方法可以自动学习更多的关键特征模式。基于深度学习的TIS模型比我们的GCR-Net表现更差,这表明我们的GCR-Net是一种有效的表示学习工具。
简单地说,通过综合实验,我们发现GCR-Net在评价指标和效率方面表现出了优势,然后得到了以下基本的观察结果模型在准确性、灵敏度和特异性方面比最先进的方法获得了更好的性能。也就是说,我们的模型不仅能正确地检测到TIS信号的关键模式信息,而且还能很好地捕获其结构和时间信息,这对提高TIS预测的性能至关重要。2)我们提出的门控机制是一种有效的TIS预测任务策略。虽然在我们的模型中没有使用其他手工制作的特征,如核苷酸序列的组成和统计特性,但与已发表的方法相比,GCR-Net仍然取得了显著的结果。
分析和讨论
在本节中,我们将进行实证研究来分析不同区块的重要性。
嵌入信息的有效性
在GCR-Net中,我们采用共现嵌入的方法来提取TIS信号序列的全局统计信息。在本节中,我们进一步进行了实验,以展示了嵌入特征对三种场景的贡献,1)嵌入,2)不嵌入(使用rand向量)和3)对TIS预测的贡献。表3报告了在四个TIS数据集上的Acc、Se和Sp的实验结果
从表3可知,带嵌入的GCR-Net在Acc、Se、Sp、AUROC和AUPRC方面比其他表示更能获得更好的结果。特别是,我们的嵌入方法在4个TIS数据集上的性能始终优于独热编码方法,Acc高2.33%,Se高2.69%,Sp高1.98%,AUROC高2.33%,AUPRC高3.36%。我们的嵌入方法在4个TIS数据集上的嵌入方法总是优于rand向量方法,Acc得分高1.93%,Se得分高2.49%,Sp得分高1.38%,AUROC得分高1.93%,平均AUPRC得分高2.87%。以上的观察结果告诉我们,单热和兰德向量编码方法可能不是TIS序列特征表示的最优策略。相比之下,k-mer嵌入表示集成了序列的上下文信息,从而提高了预测性能。
模型分析
在本节中,我们将进行了消融研究,以显示每个模块的影响。
每个模块的影响
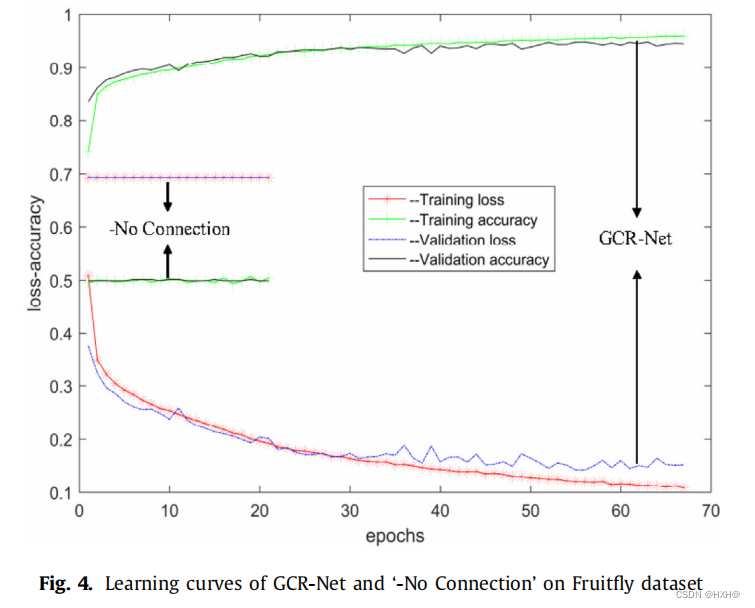
我们进行了广泛的TIS预测实验,并分析了GCR-Net的每个模块的有效性。特别是我们的设计通过删除每个模块,GCR-Net的三种变体模型,包括1)“-无Bi-GRU”删除GCR-Net的门控循环单元网络,2)“-无EGCRN”删除GCR-Net的指数门控卷积剩余网络,3)“-无连接”删除GCR-Net的身份映射连接。表4报告了变异模型在四个TIS信号数据集上的Acc、AUROC和AUPRC上的性能。去除EGCRN模块后,GCR-Net在4个TIS数据集上的Acc、AUROC和AUPRC的性能分别平均下降了3.04%、3.06%和4.80%。去除Bi-GRU模块后,GCR-Net在4个TIS数据集上的Acc、AUROC和AUPRC的性能平均分别降低了1.22%、1.22%和1.94%。去除身份连接后,GCR-Net在Acc、AUROC和AUPRC上的性能平均分别下降了45.42%、45.59%和43.57%。因此,我们可以观察到,身份连接对于我们提出的模型是最重要的,而快捷连接有利于信息在GCR-Net层之间的传播。在既不添加额外的参数,也不添加计算复杂度的情况下,这些连接可以提高下层和高层之间的集成行为,以提高模型对TIS预测的鲁棒性。正如在第3.2节中所介绍的,我们使用不同层之间的快捷连接来解决GCRNet的收敛问题。如图4所示,我们根据训练\验证损失和训练-来可视化模型的收敛过程提高\验证精度,以进一步验证模型在果蝇数据集上的有效性和鲁棒性。我们可以发现,我们的具有快捷连接的GCR-Net易于优化,并表现出较低的训练和验证误差。因此,我们的GCR-Net可以很容易地从连接策略中获得精度,并产生比以前的模型更好的实验结果。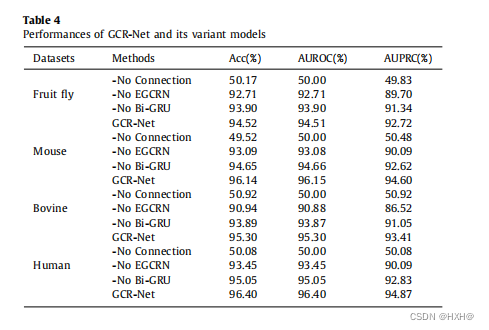
指数门控线性单位的影响
如第3.2节所述,我们采用了新的指数门控线性单元来缓解深度网络在训练过程中的收敛性问题。我们的门控单元还可以通过为梯度提供一条路径,同时保留序列数据的非线性表示能力。为了验证其有效性,我们进行了与GCR-Net两种不同模型的收敛速度和识别性能的实验比较。变异模型的门控单元分别使用简单线性单元和整流线性单元,模型分别表示为GCRNet线性单元和GCR-Net relu。表5报告了GCR-Net及其变体模型在各种TIS数据集上的综合实验结果。
表5报告了来自基因组序列的TIS预测性能。GCR-Net比其他变量模型,包括GCR-Net线性和GCR-Net relu,取得了更好的结果。特别是GCR-Net在牛数据集上始终优于GCR-Net线性和GCR-Netrelu,Acc高0.49%,Se高0.16%,Sp高0.82%,AUROC高0.48%,AUPRC高0.54%。GCR-Net在小鼠数据集上始终优于GCRNet线性和GCR-Net relu,Acc得分高0.12%,Se得分高0.35%,Sp得分低0.10%,AUROC得分高0.13%,AUPRC得分高0.28%。GCR-Net有一个指数线性单位路径,可以使梯度快速通过活动单元。GCR-Net线性和GCR-Net relu都没有线性关系,因此存在梯度消失问题。由于将我们的指数门控机制引入神经网络,GCR-Net不仅从基因组序列中学习精确的特征映射,而且产生了更显著的结果。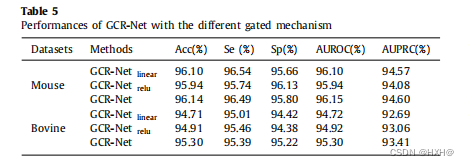
讨论
与已发表的TIS预测模型相比,我们的模型试图基于先进的神经机制,同时充分利用时空模式特征来识别TIS。现有的深度学习方法往往忽略了TIS信号序列的详细的局部模式信息,并没有充分利用网络底层的低级空间知识。为了获得更好的学习能力,我们提出了指数门控机制,使信息在获得非线性学习能力的同时间传播。此外,我们使用身份连接来控制层的信息流。该机制和连接有利于信息的多层传播以及特征融合和梯度传播。实验结果表明,残差连接成功地解决了优化问题,促进了下层和高层之间的信息交换。
特别是,我们的模型主要包括三个步骤:数据表示、特征学习和预测。然后,我们结合上述三个步骤,设计了一个不需要手动功能的自动化模型。与已发表的方法相比,该模型能够产生具有高识别能力的特征,从而提高TIS预测任务的性能。进一步的研究包括将所有组件集成到我们的模型中,以评估识别和表示能力,结果证实了具有有效训练机制的门控卷积网络可以用于解决复杂的TIS预测问题。
结论
本文提出了一种有效的TIS预测模型,以联合表示和建模来自基因组数据的时空依赖模式。特别地,我们使用一个层次结构来分别模拟k-mers在空间维度上的相互作用和k-mers在时间维度上的相互作用。接下来,我们使用一个全连接层来融合空间和时间维度之间的上下文交互作用,并获得用于TIS预测的判别嵌入表示。在各种TIS数据集上的实验结果证明了我们的模型的有效性,并为TIS调控机制提供了生物学上的见解。此外,指数门控线性单元可以缓解TIS预测训练过程中的梯度问题,提高收敛速度,嵌入信息有助于提高TIS预测的性能。在我们未来的工作中,我们将开发一个基于变压器的双向编码器表示的轻量级TIS预测模型,我们将探索基于量子理论的TIS预测模型的可解释性。














 2万+
2万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









