







目录
FiNER: Financial Numeric Entity Recognition for XBRL Tagging
建立了新的任务,提出了新的预训练模型和数据集。
将 xbrl 标记作为金融领域的新实体提取任务,并发布 finer-139,这是一个包含 110 万个带有金色 xbrl 标记的句子的数据集。XBRL是针对金融数据集中的数字等实体进行标注,实体类型种类较多,在FiNer中,涵盖了139个type。
论文中提到的贡献有:
- 我们引入了 xbrl 标记(在金融领域常用的标记),这是一项针对现实世界需求的新金融 nlp 任务,并且我们发布了第一个 xbrl 标记数据集 finer-139。(为什么选择139个标签?——>由于 xbrl 标签会定期更改,因此我们选择了 139 个(在 6,008 个中)最常见的 xbrl 标签,在 Finer-139 中出现至少 1,000 次。)
- 我们提供了使用 bil stms 和 bert 以及通用或 in-领域预训练,为更好的 139 的未来工作建立强大的基线结果。
- 我们表明,用反映标记形状和大小的伪标记替换数字标记可以显着提高基于 bert 的模型在此任务中的性能。 (Bert预训练范式)_Bert+[num]->我们使用正则表达式检测数字,并将每个数字替换为单个 [num] 伪令牌,该伪令牌无法拆分。伪token被添加到bert词汇表中;bert + [shape]:我们将数字替换为无法拆分的伪标记,并表示数字的形状,比如,‘53.2’变成‘[XX.X]’,‘40,200.5’变成‘[XX,XXX.X]’。
4.我们发布了一个新的bert模型家族(sec-bert, sec-bert-num, sec-bert shape),在200k财务文件上进行了预训练,在finer-139.3,4,5上获得了最好的结果
基线模型
SPACY
BILSTM
BERT
CRFs
应用场景
一个实际用例是使用 xbrl 标记器作为推荐引擎,为用户选择的特定令牌提出 k 个最可能的 xbrl 标记
错误分析
- 专业术语:在这类错误中,模型能够理解一般的金融语义,但不能完全理解高度技术性的细节。例如,经营租赁费用金额有时被错误地分类为租赁和租金费用
- 财务日期,很多情况下,财务日期无法被识别出来。
- 注释不一致,注释的标准可能不太统一。
Boundary Smoothing for Named Entity Recognition
four English NER datasets (CoNLL2003, OntoNotes 5, ACE 2004 and ACE 2005)
two Chinese datasets (Weibo NER and Resume NER)
two Chinese datasets (OntoNotes 4 and MSRA)
核心思想
不在考虑使用硬边界(确定性实体边界,非0即1),二是软边界(边界周围也可能是实体所在,不确定性更强)。
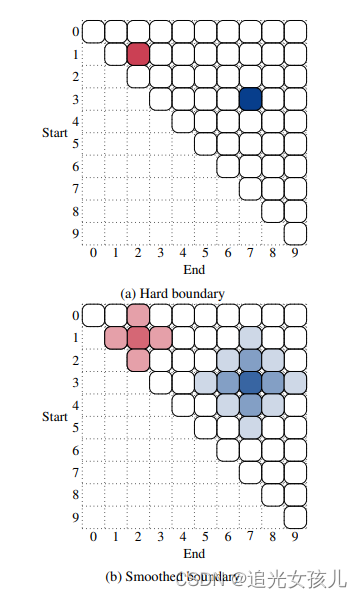
红色表示的smooth size=1,蓝色表示的smooth size==2.
hard boundary
在hard boundary中,x被feedforward映射得到两个表示hs和he,即span的start和end表示。
在识别type=c的实体时,还有一个wj-i向量,需要学习,可能表示的span长度信息。
一个span是否为实体的打分值为:

之后,通过softmax layer,得到分类。
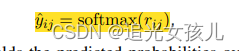
loss函数计算为:cross_entropy
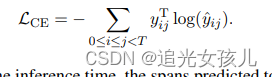
soft boundary
具体来说,给定一个被注释的实体,一部分概率被分配给其周围的跨度,而剩余的概率1-被分配给最初被注释的跨度。
周围跨度被分配的概率值为:
ϵ
/
D
\epsilon /D
ϵ/D,D为跨度距离最初被注释跨度的距离。
实验中,研究了在 ϵ \epsilon ϵ 取不同值的情况下,模型的效果。
Enhancing Entity Boundary Detection for Better Chinese Named Entity Recognition
这篇文章是提出了一种新方法,但为啥只限制于中文领域?方法不应该是通用性吗?
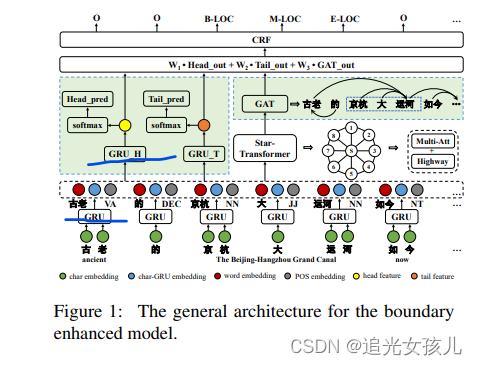
文章给出的解释是,中文不类似于英文以空格来分词,中文没有明显的分词标志,所以提出了一种用于中文NER的方法。(与英语相比,由于缺乏明确的词边界和时态信息,中文命名实体识别(NER)更具挑战性。在本文中,我们提出了一种边界增强方法来获得更好的中文 NER。特别是,我们的方法从两个角度增强了边界信息。一方面,我们通过额外的图注意网络(GAT)层增强了短语内部依赖的表示。另一方面,以实体头尾预测(即边界)为辅助任务,我们提出了一个统一的框架(然后将明确的头尾边界信息和基于Dependency GAT的隐性边界信息结合起来,以提高中文的误码率。)来学习边界信息并联合识别NE。)
我还是觉得文中给的理由,不能让人信服。
模型结构
3个part:
GRU-based head and tail representation(头、尾表示)
Star-transformer based contextual embedding layer
GAT-based dependency embedding layer(图依赖路径)
模型整体结构:
词嵌入层——GRU得到(looking up the pre-trained word embeddings1 (Li et al., 2018). The sequence of character embeddings contained in a word will be fed to a bi-direction GRU layer)
Star-transformer based contextual embedding layer——简化了transformer的结构。
GAT-based dependency embedding layer——利用词之间的依赖关系来构建图神经网络
GRU-based head and tail representation layer——两个单独的 GRU 层用于对实体进行头部和尾部预测,其隐藏特征与 GAT 层的输出相加:
最终的Hidden state 表示为:

模型的损失函数:
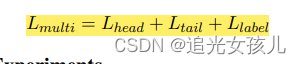
Nested Named Entity Recognition as Latent Lexicalized Constituency
这篇文章没看完,涉及到语义解析的部分。需要用到句法树。


















 1367
1367

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











