







梯度下降 gradient descent
学习资料来源:https://www.bilibili.com/video/BV1Ht411g7Ef?p=6
深度学习训练算法都是以梯度下降算法及其改进算法为核心的,训练的最终目的是使损失函数最小。沿着梯度下降方向更新变量,找到函数最小值
Set the learning rate η carefully,调的太大就飞出去,太小时间过长没效果

Adaptive learning rates
基本方法:reduce the learning rate by some factor every few epochs
-
At the beginning , we are far from the destination, so we use large learning rate
-
After several epochs, we are close to the destination, se we reduce the learning rate
Learning rate cannot be one-size-fits-all -
giving different parameters different learning rates不同参数不同learning rate
-
vanilla gradient descent
-

w是某一个参数
-
- 通常影响因素learning rate 和gradient(large gradient, large step)
-
- intuitive reason :为了强调反差的效果
-
普遍算法:
the best step is 一次微分绝对值/二次微分
- adagrad算法(自适应学习速率算法)
一次微分绝对值/一次微分平方开根号
出发点:对于神经网络训练中的所有参数,不应该采用同一个学习速率,而是每个参数单独根据自己的更新状态来调整自己的学习速率。(接近收敛,微调。没有被大幅度调整,需要较大的learning rate来增加收敛的速度)
将较大的学习速率分配给更新幅度还很小的参数,算法通过对历史梯度的积累来实现,学习速率也有了新的约束
σt过去所有微分值的root mean square,对每一个参数而言都不一样
Divide the learning rate of each parameter by the root mean square of its previous derivatives
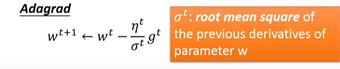


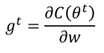
- stochastic gradient descent(随机梯度下降)
- -每次只使用单个样本的优化算法。每次只随机选择一个样本来更新模型参数,因此每次的学习非常快速。
- -优点:可以更好的适应数据的变化,随时根据最新的数据调整下降的方向
- -最大的缺点在于每次更新有时不会按照梯度下降最快的方向进行,因此可能带来扰动。对于局部极小值点,扰动使得梯度下降方向从当前的局部极小值点跳到另一个局部极小值点,最后难以收敛。由于扰动,收敛速度会变慢,神经网络在训练中需要更多的迭代次数才能达到收敛。最终都可达到目的地。但是对于类似盆地的情况,这种随机选取可能会使得优化的方向从当前的局部极小值跳到一个更好的局部极小值点,这样对于非凸函数,可能最终收敛于一个较好的局部极值点,甚至是全局极值点。
Feature scaling(特征缩放)


标准差标准化
梯度下降 Formal derivation
泰勒展开式:



















 496
496











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









