







 本文介绍了受限玻尔兹曼机(RBM)的基本结构和核心概念,包括其作为能量模型和神经网络的角色。RBM相较于玻尔兹曼机,仅允许两层之间的神经元连接,用于抽取可见层的重要特征。通过能量函数和条件概率,RBM旨在拟合可见层的真实概率分布,训练过程涉及权重和隐藏层值的调整。
本文介绍了受限玻尔兹曼机(RBM)的基本结构和核心概念,包括其作为能量模型和神经网络的角色。RBM相较于玻尔兹曼机,仅允许两层之间的神经元连接,用于抽取可见层的重要特征。通过能量函数和条件概率,RBM旨在拟合可见层的真实概率分布,训练过程涉及权重和隐藏层值的调整。
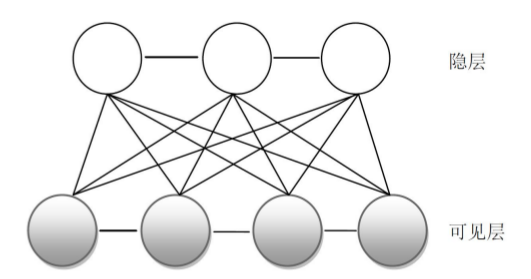
首先玻尔兹曼机(BM)是是一个能量模型,也是一个随机概率模型,也是一个神经网络模型,分为输入层和输出层两层。层与层之间相互连接,同一层的神经元之间也相互连接,具体结构如下:
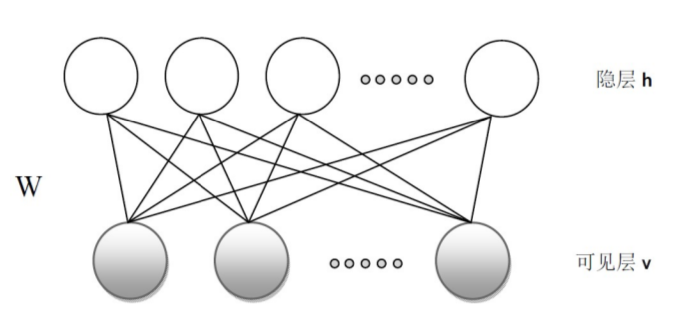
玻尔兹曼机很强大,然而训练这个模型的计算量过大,从而产生了受限玻尔兹曼机(restricted Boltzmann machine),也就是我们所要讲的RBM,相较于BM,受限玻尔兹曼机只让两个层之间的神经元有连接,既 没一层之间的各个神经元相互独立。结构图如下:底部为可见层(visible),上方为隐藏层(hidden),对可见层我们用字母v表示,对隐藏层我们用字母h表示,可见层和隐藏层之间的连接权重我们用W表示:
上面讲的都是RBM模型的结构,接着我们要引入一些RBM的内核部分了,这是最重要的部分:
首先是能量函数E(v,h):
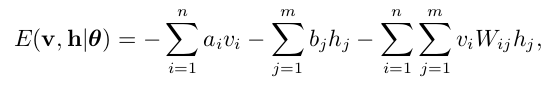
很多人首次接触的时候对这个函数都会感觉不知所云,这个时候大家不要方,可以搜一搜伊辛模型来看看,然后就会有些感悟了,总的来说,系统的能量越底,系统越稳定,具体到RBM中,之所以引入能量函数,其目的是为了让隐藏层尽量的可以抽取出可见层重要的特征,类似于PCA。
接着我们要用E(v,h | θ)来表示v和h在条件θ下的联合概率了:

这里的Z(θ)是一个归一化因子。由上式可知,当E(v,h | θ)越小的时候,P(v,h | θ)越大,表示此时v,h在条件θ下,越有可能出现。
再接着,是要求v的边缘分布了
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1389
1389

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









