







大的国家
题目:
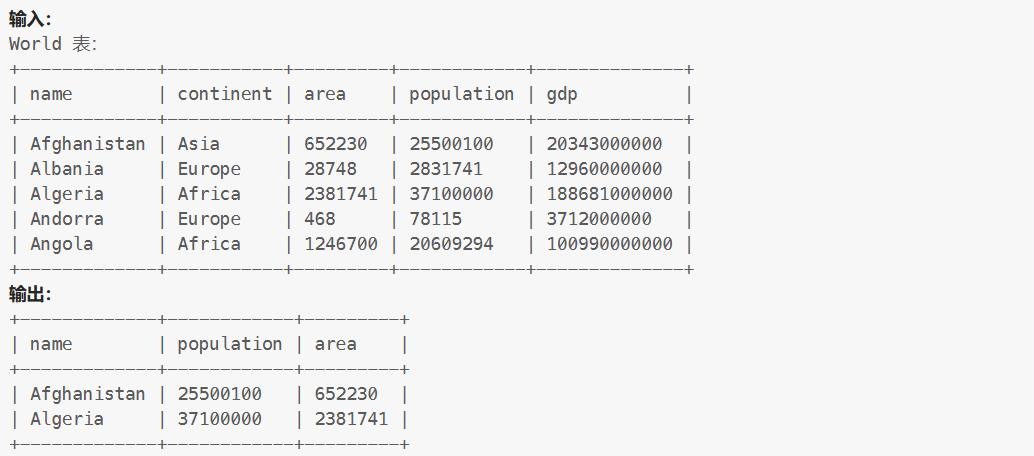
World表:
如果一个国家满足下述两个条件之一,则认为该国是 大国 :
- 面积至少为 300 万平方公里(即,
3000000 km2),或者- 人口至少为 2500 万(即
25000000)查询并报告 大国 的国家名称、人口和面积。
按 任意顺序 返回结果表。
示例:

题解:
使用行过滤方法来过滤到不满足条件的国家行,返回剩下表格的指定列即可。
import pandas as pd
def big_countries(world: pd.DataFrame) -> pd.DataFrame:
df = world[(world['area'] >= 3000000) | (world['population'] >= 25000000)]
return df[['name', 'population', 'area']]
可回收且低脂的产品
题目来源:1757. 可回收且低脂的产品 - 力扣(LeetCode)
题目:
Products表:
查找既是低脂又是可回收的产品编号。
返回结果 无顺序要求 。
查询结果格式如下例所示:
示例:


题解:
参考:1757. 可回收且低脂的产品 - 力扣(LeetCode)
在Pandas中,通过布尔索引我们可以使用布尔数组或条件来过滤DataFrame,因此可以通过判断dataframe中的每一行满足条件与否来选择性地提取出满足条件的行。
在这道题里就是通过'low_fats'=='Y'和'recyclable'=='Y'这两个条件来进行行过滤。
import pandas as pd
def recyclable_and_low_fat_products(products: pd.DataFrame) -> pd.DataFrame:
df = products[(products['low_fats'] == 'Y') & (products['recyclable'] == 'Y')]
df = df[['product_id']]
return df
从不订购的客户
题目来源:183. 从不订购的客户 - 力扣(LeetCode)
题目:
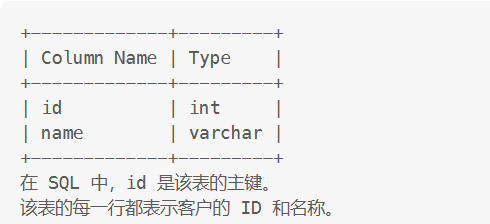
Customers表:
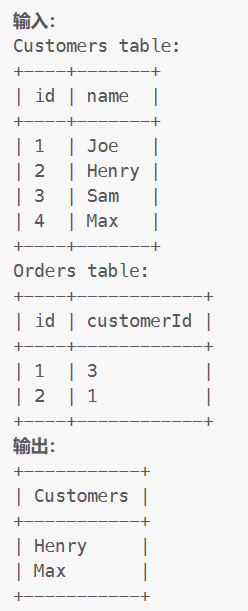
Orders表:
找出所有从不点任何东西的顾客。
以 任意顺序 返回结果表。
结果格式如下所示。
示例:

题解:
参考:183. 从不订购的客户 - 力扣(LeetCode)
方法一:
如果Customers表中的id不曾在Orders表中出现过,则意味着这个客户不曾下过订单。
在Pandas中,isin(values)用于基于其值是否在给定集合values中来过滤和选择行
import pandas as pd
def find_customers(customers: pd.DataFrame, orders: pd.DataFrame) -> pd.DataFrame:
df = customers[~customers['id'].isin(orders['customerId'])]
df = df[['name']].rename(columns = {'name': 'Customers'}) #将列名进行重命名
return df
方法二:
基于Customers表中的id和Orders表中的customerId进行左连接,然后寻找Orders表内容为空的行。
import pandas as pd
def find_customers(customers: pd.DataFrame, orders: pd.DataFrame) -> pd.DataFrame:
df = customers.merge(orders, left_on = 'id', right_on = 'customerId', how = 'left')
df = df[df['customerId'].isna()]
df = df[['name']].rename(columns = {'name':'Customers'})
return df
文章浏览(1)
题目来源:1148. 文章浏览 I - 力扣(LeetCode)
题目:
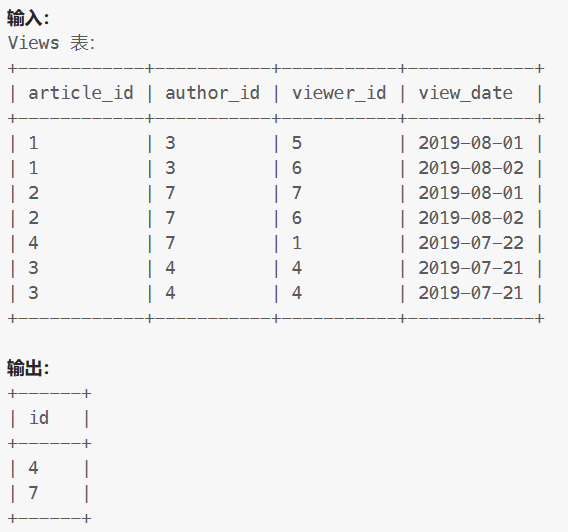
Views表:
请查询出所有浏览过自己文章的作者
结果按照
id升序排列。查询结果的格式如下所示:
示例:

题解:
参考:1148. 文章浏览 I - 力扣(LeetCode)
首先筛选出author_id=viewer_id的行,因为作者可能会查看他的文章多次,所以要将author_id重复的项进行删除,可以使用drop_duplicates函数,里面有两项参数可以设置
- subset:它指定应该考虑哪些列来查找重复项,如果未指定,则考虑所有列
- inplace:这是一个布尔值,用于确定是否应该对原始DataFrame进行就地修改,还是返回一个新的DataFrame,设置为true则是就地修改
在去除重复项后,按author_id进行升序排序即可。
import pandas as pd
def article_views(views: pd.DataFrame) -> pd.DataFrame:
df = views[views['author_id'] == views['viewer_id']]
df.drop_duplicates(subset=['author_id'], inplace = True)
df.sort_values(by = ['author_id'], inplace = True)
df.rename(columns = {'author_id' : 'id'}, inplace=True)
df = df[['id']]
return df















 3090
3090











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









