









 本文探讨了机器学习中的降维问题,源于k近邻算法在高维空间计算量大、难以满足密采样的挑战。介绍了多维缩放(MDS)、局部线性嵌入(LLE)以及度量学习等降维方法。同时,通过对比k近邻与决策树在西瓜数据集上的应用,突显了K值选择对分类结果的影响以及边界形状的差异。
本文探讨了机器学习中的降维问题,源于k近邻算法在高维空间计算量大、难以满足密采样的挑战。介绍了多维缩放(MDS)、局部线性嵌入(LLE)以及度量学习等降维方法。同时,通过对比k近邻与决策树在西瓜数据集上的应用,突显了K值选择对分类结果的影响以及边界形状的差异。
一 解决的问题
由k近邻算法引出,k近邻算法需要满足密采样,稀疏数据无法获取特定距离的近邻。
但是现实问题中,数据属性非常多,形成高维空间,然而在高维空间下的计算量大,并且满足不了密采样的要求。
于是,提出降维的方法,希望通过降维在低维空间映射出密采样,也易于学习。
如何降维才能保证仍然保存高维空间数据的特征的呢?
一种方法:希望在高低维空间,样本之间的距离是不变的,称为多维缩放,简称MDS。
第二种方法:希望在高低维空间,邻域样本之间形成的线性组合关系是不变的,属于流行学习中的局部线性嵌入,简称 LLE。
另一种思路是,并不定义以什么度量方法进行问题的解答,而是让模型自己学习一种度量方法,得到度量矩阵,最后使错误率尽可能小。如果度量矩阵是一个低秩矩阵,就可以达到降维的目的。
二 概念总结

三 习题
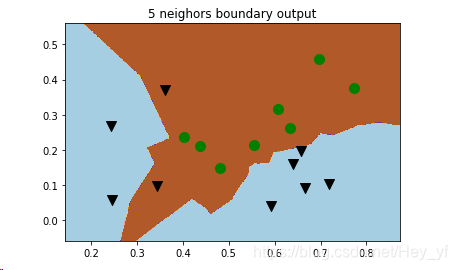
习题10.1 k近邻分类器对西瓜数据集3.0α进行分类,比较边界与决策树的异同。
数据集: 西瓜数据集3.0α
import numpy as np
data = np.loadtxt('./CH3-3watermeleondata.csv',delimiter=',')
X = data[:,0:2]
y = data[:,2]
from sklearn.neighbors import KNeighborsClassifier
neigh = KNeighborsClassifier(2)
neigh.fit(X,y)
import matplotlib.pyplot as plt
h = 0.002
x_max,x_min = max(X[:,0])+0.1 ,min(X[:,0])-0.1
y_max,y_min = max(X[:,1])+0.1, min(X[:,1])-0.1
x_grid , y_grid = np.arange(x_min,x_max,h),np.arange(y_min,y_max,h)
xx,yy = np.meshgrid(x_grid,y_grid)
Xsample = np.c_[xx.ravel(),yy.ravel()]
Z = neigh.predict(Xsample)
Z = Z.reshape(xx.shape)
f1 = plt.figure()
plt.title('2 neighors boundary output')
plt.contourf(xx, yy, Z, cmap=plt.cm.Paired)
# Plot also the training points
plt.scatter(X[y == 0,0], X[y == 0,1], marker = 'v', color = 'k', s=100, label = 'bad')
plt.scatter(X[y == 1,0], X[y == 1,1], marker = 'o', color = 'g', s=100, label = 'good')试了sklearn默认的5个近邻,分类已经出现短路,准确率降低;基于2个近邻的结果好一点;对于K近邻来说,K的值会对结果产生很大影响,这里最明显的是右下角边界处的两个坏瓜与好瓜距离很近,K的值在这里边界影响比较大。
由图可知,K最近的边界可以是曲线,但决策树的边界是线性的。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









