







一、安装步骤
在自己的新建的虚拟环境中,安装以下包
1. pip install labelme
2. pip install pyqt5
3. pip install pillow==4.0.0
通过以下命令可以查看Package是否安装。

安装完成后在终端输入labelme即可启动:
labelme
二、示例步骤演示
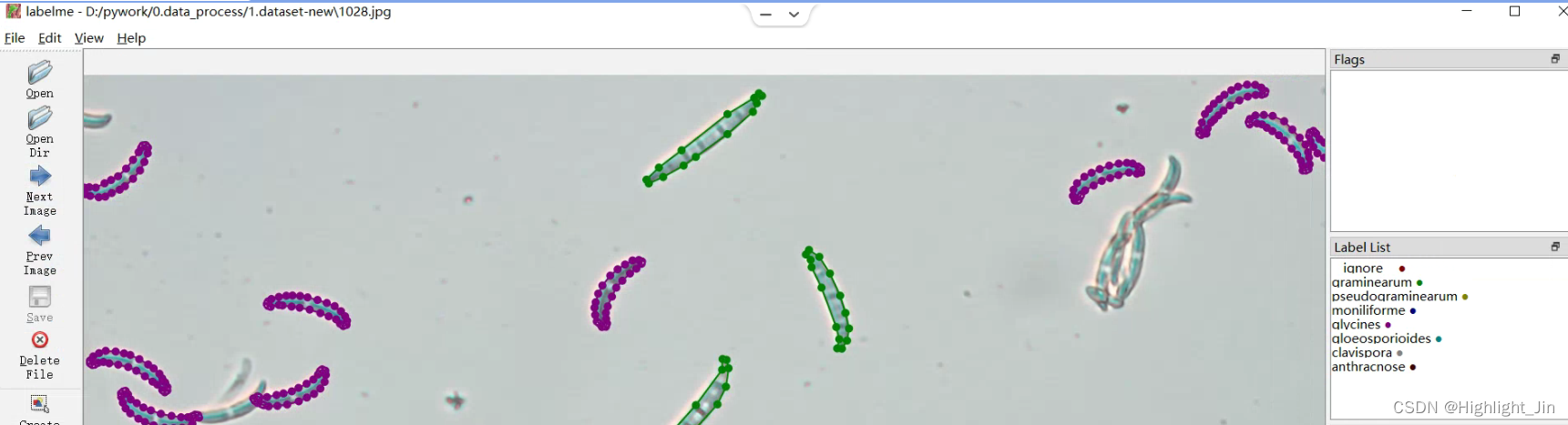
1.启动labelme
在创建好标签后,启动labelme并读取标签文件(注意启动根目录),其中–labels指定了标签文件的路径。
labelme --labels label.txt
如下图所示,在对应的图片文件夹下执行命令

读取标签后,我们在界面右侧能够看到Label List中已经载入了刚刚我们自己创建的标签文件,并且不同类别用不同的颜色表示。
2.点击save,进行保存

三、对labelme的标签结果进行验证
1.opencv-python读取图片和lableme标注的json文件并显示mask
import cv2
import numpy as np
import json
json_path = './1.json' # json文件的路径
img_path = './1.jpg' # 图片的路径
labelme_json = json.load(open(json_path, encoding='utf-8')) # 读取json文件
img = cv2.imread(img_path) # 读取图片
# (2160, 3840, 3) 图片的高为2160, 宽为3840
mask = np.zeros((2160, 3840, 1), dtype=np.uint8)
mask2 = np.zeros((2160, 3840, 3), dtype=np.uint8)
points = labelme_json['shapes'][0]['points'] # 拿出第一个物体的坐标
points = np.array(points) # 转化成ndarray
points = points.reshape(-1, 1, 2) # <class 'tuple'>: (18, 1, 2)
points = points.astype(np.int32) # 把坐标点的类型由float64转化为int32
cv2.fillConvexPoly(mask, points, (255,)) # 单个多边形填充,
cv2.fillConvexPoly(mask2, points, (255, 255, 255))
# 显示mask
cv2.namedWindow("mask", 2) # WINDOW_NORMAL参数可以手动改变窗口的大小
cv2.imshow('mask', mask)
cv2.waitKey(0)
# new_image = cv2.bitwise_and(img, mask)
new_image = cv2.bitwise_and(img, mask2) # 对图像(灰度图像或彩色图像)每个像素值进行二进制“与”操作
# new_image[mask2==255] = 100
# 显示mask区域图像
cv2.namedWindow("new_image", 2)
cv2.imshow('new_image', new_image)
cv2.waitKey(0)
2.画 mask( json文件由 labelme 标注 )
3.将使用labelme标注的json文件可视化,源图像与标签图像叠加,用于查看标注效果(参考这个,这个相当于是用labelme中的命令进行可视化)
使用labelme标注的json文件可视化,源图像与标签图像叠加,用于查看标注效果
# 1.单文件json格式标签转为png格式
'''
直接cmd终端运行:
labelme_json_to_dataset 文件名.json
可得到一个文件夹,有4个文件
img.png,源文件图像
label.png,标签图像
label_names.txt,标签中的各个类别的名称
label_viz.png,源文件与标签融合文件
注:JPG是有损压缩,而PNG是无损压缩,png图像会大于jpg图像。
'''
import os
import shutil
# 2.批量json格式标签转为png格式
# os模块多次调用CMD命令,os.popen() 或 os.system()
# 多次调用labelme_json_to_dataset,为每个json生成一个目录文件(包含4个文件)
def json2png(json_folder, root_folder):
# 获取文件夹内的文件名
FileNameList = os.listdir(json_folder)
print(FileNameList)
# 激活labelme环境
os.system("activate labelme")
for i in range(len(FileNameList)):
# 判断当前文件是否为json文件
x = os.path.splitext(FileNameList[i])
if (x[1] == ".json"):
json_file = os.path.join(json_folder, FileNameList[i])
out_file = os.path.join(root_folder, x[0] + '_json')
# 将该json文件转为png
# 用法:labelme_json_to_dataset [-h] [-o OUT] json_file
os.system("labelme_json_to_dataset " + ' -o ' + out_file + ' ' + json_file)
# 3.将文件批量转化成标准格式(即,所有原图像一个文件夹,所有label一个文件夹,所有可视化图像一个文件夹)
def file_split(folder):
root_folder, Paste_PNG_folder, Paste_label_folder, Paste_label_viz_folder = folder[0], folder[1], folder[2], folder[
3]
# 获取文件夹内的文件名
PathNameList = os.listdir(root_folder)
print(PathNameList)
NewFileName = 1
for i in range(len(PathNameList)):
# 判断当前文件是否为json文件
x_folder = os.path.splitext(PathNameList[i])[0]
print(x_folder)
img_file = os.path.join(root_folder, x_folder)
print(img_file)
FileNameList = os.listdir(img_file)
# print(FileNameList)
# 复制img.png文件
PNG_file = os.path.join(img_file, "img.png")
new_PNG_file = Paste_PNG_folder + "\\" + str(NewFileName) + ".png"
shutil.copyfile(PNG_file, new_PNG_file)
# 复制label.png文件
label_file = os.path.join(img_file, "label.png")
new_label_file = Paste_label_folder + "\\" + str(NewFileName) + ".png"
shutil.copyfile(label_file, new_label_file)
# 复制label_viz.png文件
label_viz_file = os.path.join(img_file, "label_viz.png")
new_label_viz_file = Paste_label_viz_folder + "\\" + str(NewFileName) + ".png"
shutil.copyfile(label_viz_file, new_label_viz_file)
# 文件序列名+1
NewFileName = NewFileName + 1
if __name__ == '__main__':
json_folder = "./"
# 保存中间生成文件的文件夹, 每个子目录下有4个文件:img.png,label.png,label_names.txt,label_viz.png
root_folder = "./spore"
# 保存最终生成文件的文件夹,原图像、label、label_viz
Paste_PNG_folder = "./img1"
Paste_label_folder = "./label1"
Paste_label_viz_folder = "./label_viz"
folder = [root_folder, Paste_PNG_folder, Paste_label_folder, Paste_label_viz_folder]
for folder_x in folder:
if not os.path.exists(folder_x):
os.makedirs(folder_x)
# 用json生成png
json2png(json_folder, root_folder)
# 文件分开
file_split(folder)
4.自己想实现的功能,直接从打标签生成的json文件中,读取坐标点的信息,然后根据坐标点的信息,进行多边形的绘制。
自己实现的代码:
import json
import cv2
from matplotlib import pyplot as plt
from matplotlib.cbook import pts_to_midstep
import numpy as np
print(cv2.__version__)
label_json = json.load(open('1.json', encoding='utf-8'))
value = label_json['shapes']
length = len(value)
img = cv2.imread(r'1.jpg')
fig = img.copy()
all = []
for i in range(length):
points = value[i]['points']
pts = np.array(points, dtype=np.int)
# print(type(new_points))
# pts = pts.reshape((-1, 1, 2))
# print(pts)
all.append(pts)
# print(fig.shape)
# print(sum(fig - img))
# print(sum(fig - img).shape)
# print(sum(sum(fig - img)))
# cv2.polylines(fig, [pts], isClosed=True, color=(255, 125, 125), thickness=5)
# print(sum(sum(fig - img)))
cv2.polylines(fig, all, isClosed=True, color=(255, 125, 125), thickness=5)
cv2.namedWindow('image', 2)
cv2.imshow('image', fig)
cv2.waitKey(0)
要注意dtype的类型要转化成np.int,cv2.polylines()第二个参数的形式[pts]。
import json
import cv2
import numpy as np
print(cv2.__version__)
label_json = json.load(open('1.json', encoding='utf-8'))
# print(label_json)
# print(label_json.keys())
value = label_json['shapes']
# print(value)
# print(len(value))
length = len(value)
# print(length)
for i in range(length):
points = value[i]['points']
# print(points)
# print(type(points))
pts = np.array(points, dtype=np.int)
# print(type(new_points))
# pts = pts.reshape((-1, 1, 2))
# print(pts)
img = cv2.imread(r'1.jpg')
fig = img.copy()
# print(fig.shape)
print(sum(fig - img))
print(sum(fig - img).shape)
print(sum(sum(fig-img)))
cv2.polylines(fig, [pts], isClosed=True, color=(255, 125, 125), thickness=5)
print(sum(sum(fig-img)))
cv2.namedWindow('image', 2)
cv2.imshow('image', fig)
cv2.waitKey(0)
break
# 此处只画了一个目标
# cv2.fillPoly()的使用注意事项同cv2.polylines
import json
import cv2
from matplotlib import pyplot as plt
import numpy as np
label_json = json.load(open('./1.json', encoding='utf-8'))
value = label_json['shapes']
length = len(value)
for i in range(length):
points = value[i]['points']
new_points = np.array(points, dtype=np.int)
# print(type(new_points))
# print(new_points)
img = cv2.imread('./1.jpg')
cv2.fillPoly(img, [new_points], (2, 255, 255))
cv2.namedWindow("draw_0", 2)
cv2.imshow("draw_0", img) # 显示画过矩形框的图片
cv2.waitKey(0)
cv2.destroyWindow("draw_0")
break
5.[详细教程]新版labelme标注后的json文件,提取不同的标签后批量注入到新的背景中作为人工数据集
四、Labelme分割标注软件使用
python labelme2coco.py data_annotated data_dataset_coco --labels label.txt
data_annotated是标注保存的json标签文件夹,data_dataset_coco是生成MS COCO数据类型的目录。
labelme的官方链接,提供了转换为各个任务的脚本。
使用这个转换之后,在项目中指定num_classes=真实类别数+1(背景)
2.自己对labelme2coco.py的脚本进行修改,使得,num_classes=真实类别数,并且id从1开始。修改的内容见文中注释的部分。
#!/usr/bin/env python
# python labelme2coco.py data_yy data_dataset_yy --labels labels_yy.txt
import argparse
import collections
import datetime
import glob
import json
import os
import os.path as osp
import sys
import uuid
import imgviz
import numpy as np
import labelme
try:
import pycocotools.mask
except ImportError:
print("Please install pycocotools:\n\n pip install pycocotools\n")
sys.exit(1)
def main():
parser = argparse.ArgumentParser(
formatter_class=argparse.ArgumentDefaultsHelpFormatter
)
parser.add_argument("input_dir", help="input annotated directory")
parser.add_argument("output_dir", help="output dataset directory")
parser.add_argument("--labels", help="labels file", required=True)
parser.add_argument(
"--noviz", help="no visualization", action="store_true"
)
args = parser.parse_args()
if osp.exists(args.output_dir):
print("Output directory already exists:", args.output_dir)
sys.exit(1)
os.makedirs(args.output_dir)
os.makedirs(osp.join(args.output_dir, "JPEGImages"))
if not args.noviz:
os.makedirs(osp.join(args.output_dir, "Visualization"))
print("Creating dataset:", args.output_dir)
now = datetime.datetime.now()
data = dict(
info=dict(
description=None,
url=None,
version=None,
year=now.year,
contributor=None,
date_created=now.strftime("%Y-%m-%d %H:%M:%S.%f"),
),
licenses=[dict(url=None, id=0, name=None,)],
images=[
# license, url, file_name, height, width, date_captured, id
],
type="instances",
annotations=[
# segmentation, area, iscrowd, image_id, bbox, category_id, id
],
categories=[
# supercategory, id, name
],
)
class_name_to_id = {}
# 应该是在这里进行修改,把类别的id从 1 开始,并且没有_background_, 自己尝试进行修改一下
for i, line in enumerate(open(args.labels).readlines()):
class_id = i # starts with 1
class_name = line.strip()
if class_name == "__ignore__":
continue
# if class_id == -1:
# assert class_name == "__ignore__"
# continue
class_name_to_id[class_name] = class_id
data["categories"].append(
dict(supercategory=None, id=class_id, name=class_name,)
)
out_ann_file = osp.join(args.output_dir, "annotations.json")
label_files = glob.glob(osp.join(args.input_dir, "*.json"))
for image_id, filename in enumerate(label_files):
print("Generating dataset from:", filename)
label_file = labelme.LabelFile(filename=filename)
base = osp.splitext(osp.basename(filename))[0]
out_img_file = osp.join(args.output_dir, "JPEGImages", base + ".jpg")
img = labelme.utils.img_data_to_arr(label_file.imageData)
imgviz.io.imsave(out_img_file, img)
data["images"].append(
dict(
license=0,
url=None,
file_name=osp.relpath(out_img_file, osp.dirname(out_ann_file)),
height=img.shape[0],
width=img.shape[1],
date_captured=None,
id=image_id,
)
)
masks = {} # for area
segmentations = collections.defaultdict(list) # for segmentation
for shape in label_file.shapes:
points = shape["points"]
label = shape["label"]
group_id = shape.get("group_id")
shape_type = shape.get("shape_type", "polygon")
mask = labelme.utils.shape_to_mask(
img.shape[:2], points, shape_type
)
if group_id is None:
group_id = uuid.uuid1()
instance = (label, group_id)
if instance in masks:
masks[instance] = masks[instance] | mask
else:
masks[instance] = mask
if shape_type == "rectangle":
(x1, y1), (x2, y2) = points
x1, x2 = sorted([x1, x2])
y1, y2 = sorted([y1, y2])
points = [x1, y1, x2, y1, x2, y2, x1, y2]
if shape_type == "circle":
(x1, y1), (x2, y2) = points
r = np.linalg.norm([x2 - x1, y2 - y1])
# r(1-cos(a/2))<x, a=2*pi/N => N>pi/arccos(1-x/r)
# x: tolerance of the gap between the arc and the line segment
n_points_circle = max(int(np.pi / np.arccos(1 - 1 / r)), 12)
i = np.arange(n_points_circle)
x = x1 + r * np.sin(2 * np.pi / n_points_circle * i)
y = y1 + r * np.cos(2 * np.pi / n_points_circle * i)
points = np.stack((x, y), axis=1).flatten().tolist()
else:
points = np.asarray(points).flatten().tolist()
segmentations[instance].append(points)
segmentations = dict(segmentations)
for instance, mask in masks.items():
cls_name, group_id = instance
if cls_name not in class_name_to_id:
continue
cls_id = class_name_to_id[cls_name]
mask = np.asfortranarray(mask.astype(np.uint8))
mask = pycocotools.mask.encode(mask)
area = float(pycocotools.mask.area(mask))
bbox = pycocotools.mask.toBbox(mask).flatten().tolist()
data["annotations"].append(
dict(
id=len(data["annotations"]),
image_id=image_id,
category_id=cls_id,
segmentation=segmentations[instance],
area=area,
bbox=bbox,
iscrowd=0,
)
)
if not args.noviz:
viz = img
if masks:
labels, captions, masks = zip(
*[
(class_name_to_id[cnm], cnm, msk)
for (cnm, gid), msk in masks.items()
if cnm in class_name_to_id
]
)
viz = imgviz.instances2rgb(
image=img,
labels=labels,
masks=masks,
captions=captions,
font_size=15,
line_width=2,
)
out_viz_file = osp.join(
args.output_dir, "Visualization", base + ".jpg"
)
imgviz.io.imsave(out_viz_file, viz)
with open(out_ann_file, "w") as f:
json.dump(data, f)
if __name__ == "__main__":
main()
注意:
COCO数据集一般是不包含背景的,coco的类别id是从1开始的(默认0留给背景),如果自己生成的json文件里有id为0的数据(多余的),看能不能把它给删掉。或者你自己改yolox读取数据的代码,忽略掉id为0的标签。
1.使用labelme生成COCO格式的数据集,并进行训练集、验证集的划分。
参考链接:labelme转coco数据集
#!/usr/bin/env python
# 之后都使用这个脚本. 本脚本已经进行过修改,并进行数据集的划分. 本脚本运用的是labels_spilt_train_valild.txt标签文件
# python labelme2coco_spilt_train_valid.py D:\pywork\0.data_process\1.dataset-new COCO --labels labels_spilt_train_valild.txt
import argparse
import collections
import datetime
import glob
import json
import os
import os.path as osp
import sys
import uuid
import imgviz
import numpy as np
import labelme
from sklearn.model_selection import train_test_split # 划分数据集
try:
import pycocotools.mask
except ImportError:
print("Please install pycocotools:\n\n pip install pycocotools\n")
sys.exit(1)
def to_coco(args, label_files, train):
# 创建 总标签data
now = datetime.datetime.now()
data = dict(
info=dict(
description=None,
url=None,
version=None,
year=now.year,
contributor=None,
date_created=now.strftime("%Y-%m-%d %H:%M:%S.%f"),
),
licenses=[dict(url=None, id=0, name=None, )],
images=[
# license, url, file_name, height, width, date_captured, id
],
type="instances",
annotations=[
# segmentation, area, iscrowd, image_id, bbox, category_id, id
],
categories=[
# supercategory, id, name
],
)
# 创建一个 {类名 : id} 的字典,并保存到 总标签data 字典中。
class_name_to_id = {}
# 应该是在这里进行修改,把类别的id从 1 开始,并且没有_background_, 自己尝试进行修改一下
for i, line in enumerate(open(args.labels).readlines()):
class_id = i # starts with 1
class_name = line.strip() # strip() 方法用于移除字符串头尾指定的字符(默认为空格或换行符)或字符序列。
if class_name == "__ignore__":
continue
# if class_id == -1:
# assert class_name == "__ignore__"
# continue
class_name_to_id[class_name] = class_id
data["categories"].append(
dict(supercategory=None, id=class_id, name=class_name, )
)
# 判断是是训练集,还是验证集
if train:
out_ann_file = osp.join(args.output_dir, "annotations", "instances_train2017.json")
else:
out_ann_file = osp.join(args.output_dir, "annotations", "instances_val2017.json")
# out_ann_file = osp.join(args.output_dir, "annotations.json")
# label_files = glob.glob(osp.join(args.input_dir, "*.json"))
for image_id, filename in enumerate(label_files):
print("Generating dataset from:", filename)
label_file = labelme.LabelFile(filename=filename)
base = osp.splitext(osp.basename(filename))[0] # 文件名不带后缀
# out_img_file = osp.join(args.output_dir, "JPEGImages", base + ".jpg")
if train:
out_img_file = osp.join(args.output_dir, "train2017", 'JPEGImages' , base + ".jpg")
else:
out_img_file = osp.join(args.output_dir, "val2017", 'JPEGImages', base + ".jpg")
# ************************** 对图片的处理开始 *******************************************
# 将标签文件对应的图片进行保存到对应的 文件夹。train保存到 train2017/ test保存到 val2017/
img = labelme.utils.img_data_to_arr(label_file.imageData) # .json文件中包含图像,用函数提出来
imgviz.io.imsave(out_img_file, img) # 将图像保存到输出路径
# ************************** 对图片的处理结束 *******************************************
# ************************** 对标签的处理开始 *******************************************
data["images"].append(
dict(
license=0,
url=None,
file_name=osp.relpath(out_img_file, osp.dirname(out_ann_file)),
height=img.shape[0],
width=img.shape[1],
date_captured=None,
id=image_id,
)
)
masks = {} # for area
segmentations = collections.defaultdict(list) # for segmentation
for shape in label_file.shapes:
points = shape["points"]
label = shape["label"]
group_id = shape.get("group_id")
shape_type = shape.get("shape_type", "polygon")
mask = labelme.utils.shape_to_mask(
img.shape[:2], points, shape_type
)
if group_id is None:
group_id = uuid.uuid1()
instance = (label, group_id)
if instance in masks:
masks[instance] = masks[instance] | mask
else:
masks[instance] = mask
if shape_type == "rectangle":
(x1, y1), (x2, y2) = points
x1, x2 = sorted([x1, x2])
y1, y2 = sorted([y1, y2])
points = [x1, y1, x2, y1, x2, y2, x1, y2]
if shape_type == "circle":
(x1, y1), (x2, y2) = points
r = np.linalg.norm([x2 - x1, y2 - y1])
# r(1-cos(a/2))<x, a=2*pi/N => N>pi/arccos(1-x/r)
# x: tolerance of the gap between the arc and the line segment
n_points_circle = max(int(np.pi / np.arccos(1 - 1 / r)), 12)
i = np.arange(n_points_circle)
x = x1 + r * np.sin(2 * np.pi / n_points_circle * i)
y = y1 + r * np.cos(2 * np.pi / n_points_circle * i)
points = np.stack((x, y), axis=1).flatten().tolist()
else:
points = np.asarray(points).flatten().tolist()
segmentations[instance].append(points)
segmentations = dict(segmentations)
for instance, mask in masks.items():
cls_name, group_id = instance
if cls_name not in class_name_to_id:
continue
cls_id = class_name_to_id[cls_name]
mask = np.asfortranarray(mask.astype(np.uint8))
mask = pycocotools.mask.encode(mask)
area = float(pycocotools.mask.area(mask))
bbox = pycocotools.mask.toBbox(mask).flatten().tolist()
data["annotations"].append(
dict(
id=len(data["annotations"]),
image_id=image_id,
category_id=cls_id,
segmentation=segmentations[instance],
area=area,
bbox=bbox,
iscrowd=0,
)
)
# ************************** 对标签的处理结束 *******************************************
# ************************** 可视化的处理开始 *******************************************
if not args.noviz:
viz = img
if masks:
labels, captions, masks = zip(
*[
(class_name_to_id[cnm], cnm, msk)
for (cnm, gid), msk in masks.items()
if cnm in class_name_to_id
]
)
viz = imgviz.instances2rgb(
image=img,
labels=labels,
masks=masks,
captions=captions,
font_size=15,
line_width=2,
)
out_viz_file = osp.join(
args.output_dir, "Visualization", base + ".jpg"
)
imgviz.io.imsave(out_viz_file, viz)
# ************************** 可视化的处理结束 *******************************************
with open(out_ann_file, "w") as f: # 将每个标签文件汇总成data后,保存总标签data文件
json.dump(data, f)
def main():
parser = argparse.ArgumentParser(
formatter_class=argparse.ArgumentDefaultsHelpFormatter
)
parser.add_argument("input_dir", help="input annotated directory")
parser.add_argument("output_dir", help="output dataset directory")
parser.add_argument("--labels", help="labels file", required=True)
parser.add_argument(
"--noviz", help="no visualization", action="store_true"
)
args = parser.parse_args()
if osp.exists(args.output_dir):
print("Output directory already exists:", args.output_dir)
sys.exit(1)
os.makedirs(args.output_dir) #
# os.makedirs(osp.join(args.output_dir, "JPEGImages")) # 本脚本要进行训练集和验证集的划分,所以下面对目录进行指定修改
# 创建保存的文件夹
if not os.path.exists(osp.join(args.output_dir, "annotations")):
os.makedirs(osp.join(args.output_dir, "annotations"))
if not os.path.exists(osp.join(args.output_dir, "train2017", "JPEGImages")):
os.makedirs(osp.join(args.output_dir, "train2017", "JPEGImages"))
if not os.path.exists(osp.join(args.output_dir, "val2017", "JPEGImages")):
os.makedirs(osp.join(args.output_dir, "val2017", "JPEGImages"))
if not args.noviz:
os.makedirs(osp.join(args.output_dir, "Visualization"))
print("Creating dataset:", args.output_dir)
# 获取目录下所有的.jpg文件列表
feature_files = glob.glob(osp.join(args.input_dir, "*.jpg"))
print('| Image number: ', len(feature_files)) # 统计图片的数目
# 获取目录下所有的joson文件列表
label_files = glob.glob(osp.join(args.input_dir, "*.json"))
print('| Json number: ', len(label_files)) # 统计标签的数目
# feature_files:待划分的样本特征集合 label_files:待划分的样本标签集合 test_size:测试集所占比例
# x_train:划分出的训练集特征 x_test:划分出的测试集特征 y_train:划分出的训练集标签 y_test:划分出的测试集标签
x_train, x_test, y_train, y_test = train_test_split(feature_files, label_files, test_size=0.2) # random_state:随机种子(这个东西是会根据你填的数字多少它对最终的数据结果是有影响的,如果你每次都填1,其他参数一样的情况下你得到的随机数组是一样的。但填0或不填,每次都会不一样。)
print("| Train number:", len(y_train), '\t Value number:', len(y_test))
# 把训练集标签转化为COCO的格式,并将标签对应的图片保存到目录 /train2017/JPEGImages/
print("—" * 50)
print("| Train images:")
to_coco(args, y_train, train=True)
# 把测试集标签转化为COCO的格式,并将标签对应的图片保存到目录 /val2017/JPEGImages/
print("—" * 50)
print("| Test images:")
to_coco(args, y_test, train=False)
if __name__ == "__main__":
print("—" * 50)
main()
print("—"*50)
2.生成coco数据集以及规范化数据集的代码:https://github.com/MrSupW/datasetapi
配套的讲解:使用labelme标注数据集
对数据集的规范化:labelme数据集生成coco数据集(非常好)
为什么需要整理呢?因为不同的人进行标注,标注的进度不一样,最后要将所有的数据整理到一起。
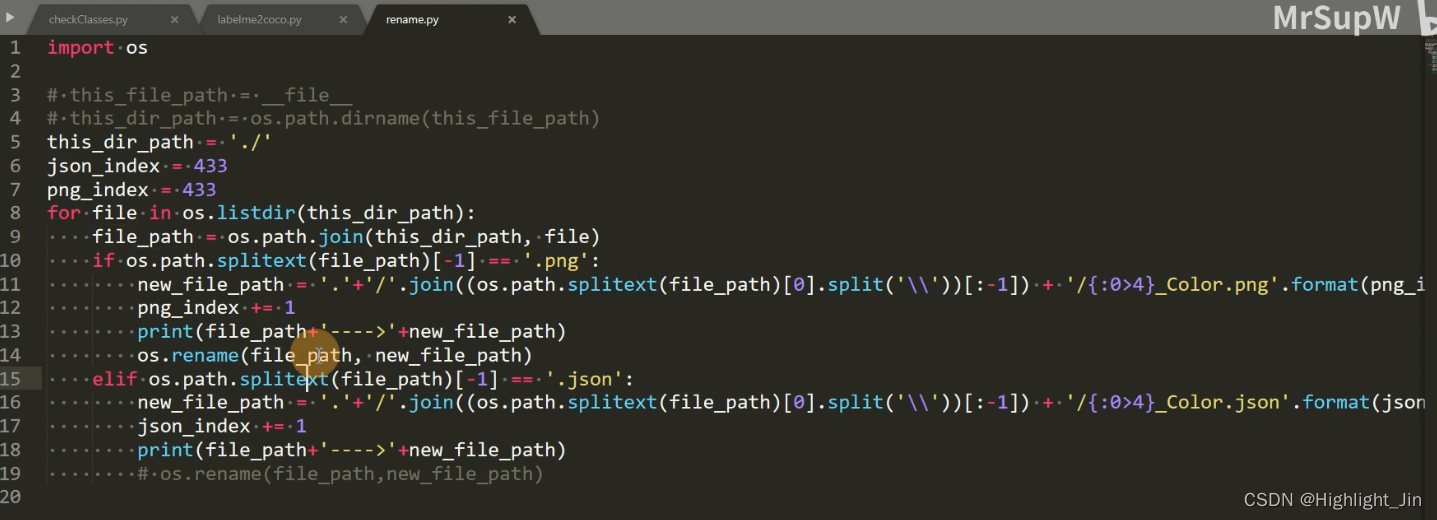
- rename.py
用于对数据集中图片以及json文件的重命名 - format.py
用于替换json中不合法的imagePath - checkClasses
用于检测当前一共标注了多少class 并对检测结果进行输出 - labelme2coco.py
用于生成coco形式的数据集
(1)首先通过rename.py进行重命名
(2)format.py
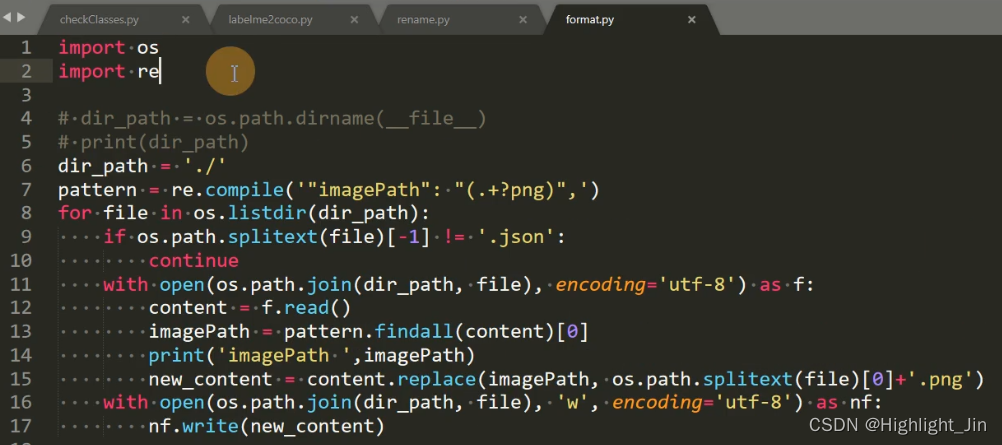
这个脚本的作用是对不同人标注数据集时,将生成的json文件保存在非图片的这个文件夹下(如下面的imagePath,imagePath中是图片的位置),就可能生成下面的结果。所以,一般情况下,不同的人标注数据集时,直接将json文件生成在当前图片所在的文件夹下面。所以需要将../test删掉只保留后面的图片。
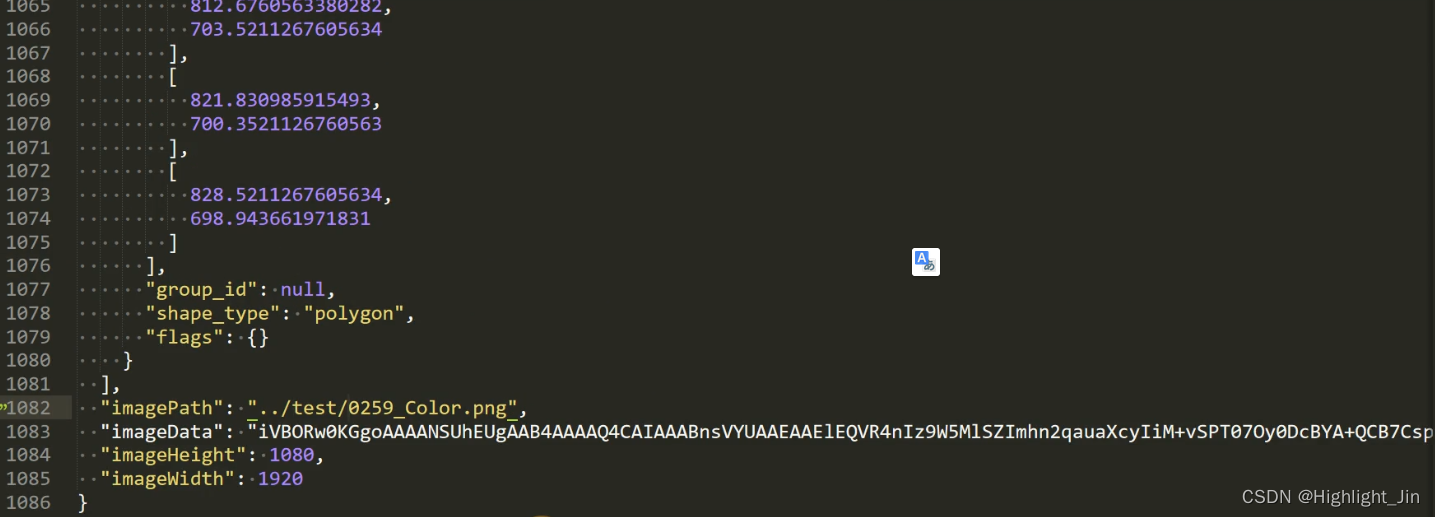

此处正则表达式的含义:.表示任意字符,+表示匹配1个或多个在它前面的字符,?表示非贪婪模式,表示可有可无。()表示优先匹配的作用
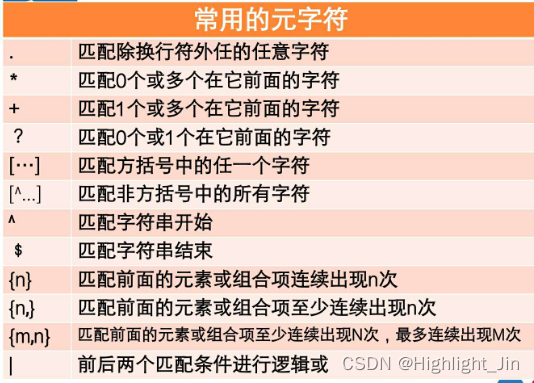
os.path.splitext(path) 分离文件名与扩展名,返回(f_path,f_name) 元组
Python 正则表达re模块之findall()详解
(3)checkClass.py
此处可以参照对自己的类别做后续的映射。(不符合自己的要求,自己重新新写了一个)

本脚本中正则化,匹配的是这个内容
(4)第四步按照之前用labelme的官方脚本,自己修改后,添加数据集中训练集、验证集的划分,以及对类别的id标注。
参考链接:
COCO数据集格式、mask两种存储格式、官方包API详解(非常好,学习)
COCO API的安装,COCO数据集介绍以及读取接口代码解读(PyTorch接口)

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









