







本文我们主要致力于解决以下几个问题:
- 本文的motivation/contribution是什么?
- 实验细节以及实验效果如何?
- 具体的应用场景?
- 本文存在什么不足?
在本文的最后,我将针对以上问题简单谈谈自己的拙见,欢迎大家一起在评论区留言谈论。
言归正传,带着上面四个问题,让我们一起探寻《Self-Attentive Sequential Recommendation》,SASRec背后的秘密!
谈谈序列推荐
由于自己是第一次给大家分享序列推荐的文章,所以本着对我自己的读者负责的态度,还是要花点篇幅给大家简单介绍下序列推荐的任务和相关方法。(当然,本人对该领域的paper阅读也有限,肯定不能像大牛那样说的那么全,一点拙见,希望大家补充讨论!)
说起序列推荐Sequential Recommendation应该已经是当下一个比较热门的话题,是很多大厂比较关注的task。它主要是致力于捕捉和解决用户随时间变化的、动态的偏好。
传统的CF方法,大部分是基于对用户交互矩阵、或者对用户交互过的item的集合进行建模,在通过某种相似性度量方法,比如点积、余弦相似度、欧几里得距离等等,获得评分进行推荐。但是一个很明显的缺点就是,协同过滤CF的方法没有考虑用户对item的交互顺序,或者说是时间戳,所以在捕捉用户动态偏好方面存在明显的不足。
为了解决上述问题,序列推荐聚焦于,根据用户到 t t t时刻的交互序列, S t = { x 1 , x 2 , … , x t } S_t = \{x_1,x_2,\dots,x_t\} St={x1,x2,…,xt}进行建模,预测或推荐用户第 t + 1 t+1 t+1时刻的交互 x t + 1 x_{t+1} xt+1。
早期,解决序列推荐比较成熟的方法是基于马尔科夫链(MC-based),它只基于用户最新的一个或者某几个交互进行建模推荐。如:
《Factorizing personalized Markov chains for next-basket recommendation.》WWW’10
当然,近年来深度学习发展迅猛,在序列推荐中也有不少成功的应用。
首先是一篇开创性的论文,《Session-based recommendations with recurrent neural networks,》ICLR‘16,他将RNN成功的应用到session-based的序列推荐之中。
于是,由于RNN本身在建模序列方面的优势,又不断涌现出一批RNN-based的优秀方法,举几个例子:
- 《Recurrent neural networks with top-k gains for session-based recommendations》
- 《Neural Attentive Session-based Recommendation》CIKM’17
- 《Recurrent Convolutional Neural Network for Sequential Recommendation》WWW’19
除了RNN-based方法,受文本分类的启发,CNN网络也被引入到序列推荐中来,其基本思想就是将用户交互的item embedding按顺序concat为矩阵,然后再将其看成"image",利用CNN提取局部特征。比如:
《Personalized Top-N Sequential Recommendation via Convolutional Sequence Embedding.》WSDM’18
最后,另一个成功的应用,便是本文了,它是对类似Transformer结构在序列推荐中的一次探索。
SASRec
transformer在nlp领域是一个相当成熟和经典的方法了,SASRec细细品味,就是基于Transformer的Encoder部分,稍作改进便应用到Seq Rec中了。如果对Transformer不了解的读者,可以看我之前的Blog,Attention Is All You Need论文详解与理解。
看完Transformer原理,我们先来看看SASRec的框图,感受下:
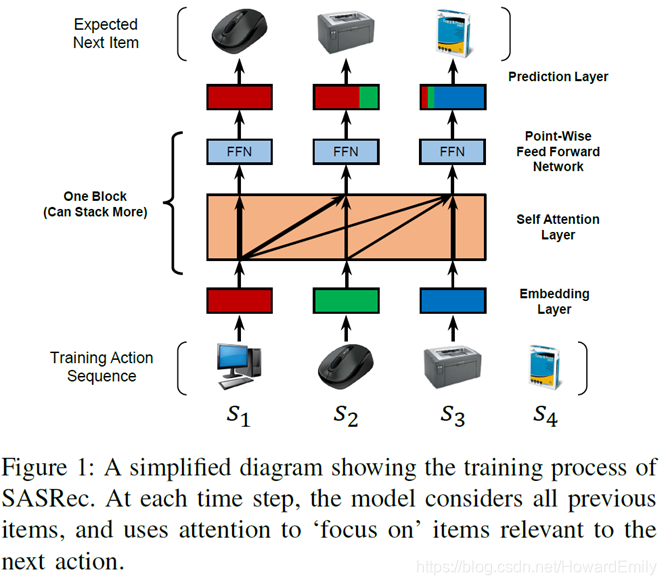
这个结构是不是非常熟悉呢?没错,其实它就是Transformer中的Encoder部分,每个block包括Self-Attention和FFN等。

PS:这里在处理时,实验部分SASRec将用户序列转化为固定的长度
n
n
n,如果长度小于n就在左侧补0,如果本身长度大于
n
n
n,便按照用户最新的交互序列截取
n
n
n个。
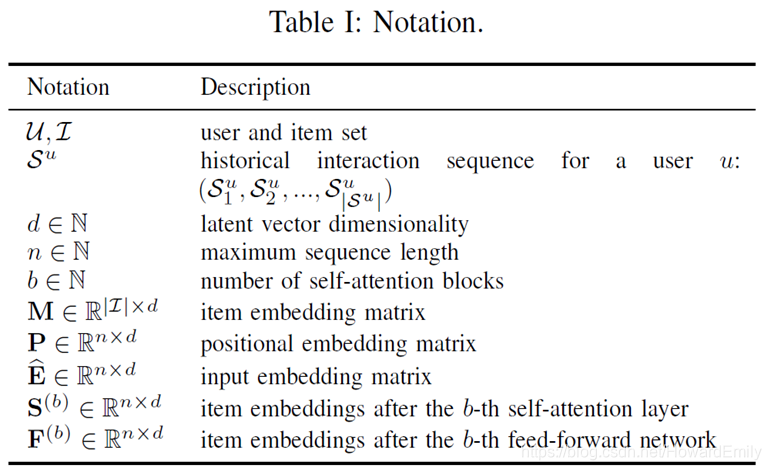
Embedding层
前面提到的
E
^
\hat E
E^只是简单的根据用户交互顺序将item embedding 拼接为一个矩阵,因为self-attention并不包含RNN或CNN模块,因此它不能感知到之前item的位置。所以必须和Transformer一样引入额外的positional embedding。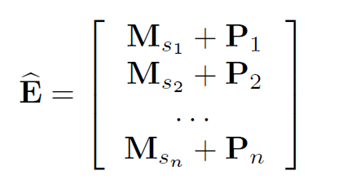
与Transformer不同的就是,这里的P矩阵是跟随模型一起训练得到的,并不是手动设计了。(作者说尝试了那种方式,效果不太好)。
那这显然就引入了SASRec的一个弊端,这种跟随模型学到的矩阵P,并不能处理长序列,可扩展性不强,在实际系统中基本无法确定
n
n
n的长度。
Self-Attention
self-attention是个老生常谈的技术了,就不介绍了。。。
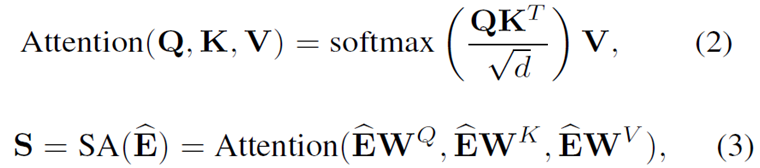
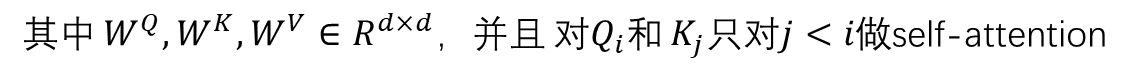
Point-Wise Feed-Forward Network
尽管self-attention能够用自适应权重聚集之前所有item的embedding,最终它仍然是个线性模型。为了增加非线性同时考虑不同隐式维度之间的交互,用了一个两层的point-wise前馈网络:
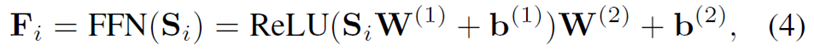
Stacking Self-Attention Blocks
到此,
F
i
F_i
Fi已经整合了之前的item embedding,提取了特征,但是这可能不够,学习更复杂的表示可能对我们有帮助,于是需要和Transformer一样进行self-attention的stack
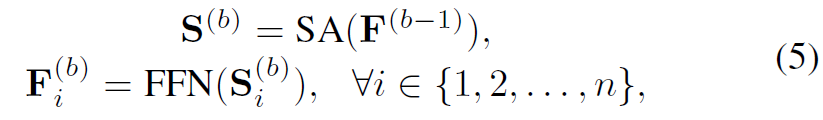
然而随着网络的加深也出现几个问题:
- 模型容量的增加导致过拟合
- 由于梯度消失训练过程变得不稳定
- 更多的参数需要更长的训练时间
于是也使用了LayerNorm,Dropout,残差连接:
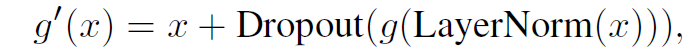
LayerNorm公式如下:
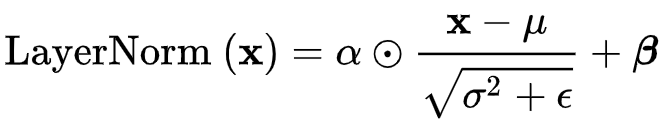
Prediction
Shared Item Embedding
采用MF的思想,使用每一时间步
t
t
t,模型的输出
F
t
(
b
)
F_t^{(b)}
Ft(b)和item embedding
M
i
M_i
Mi进行点积,计算得分。

Explicit User Modeling
为了提供个性化推荐,当前主要有两种方法:
学习显式的用户embedding表示用户偏好(MF,FPMC,Caser)
考虑用户之前的行为,通过访问过的item的embedding推测隐式的用户embedding
本文采用第二种方式,同时额外在最后一层插入显式用户embedding,例如通过加法实现:
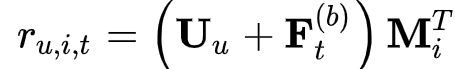
但是通过实验发现增加显式用户embedding并没有提升效果。。(这不扯淡么。。。没效果你写上去凑字数啊。。。)
Training

用二元交叉熵损失作为目标函数:
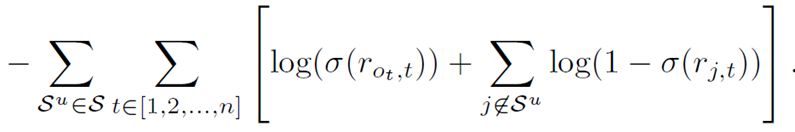
复杂度分析
文章中还介绍了SASRec的复杂度,以及和现有模型的一些简单讨论和理论分析,这里不介绍了,感兴趣的同学去看论文吧。
实验部分
实验设计是为了回答下面4个问题:
- SASRec是否超过了当前包括基于CNN/RNN模型的方法,达到了SOTA
- SASRec架构中各种组件的影响是什么
- 训练效率和扩展性如何
Attention权重是否能学到有意义的模式,关于位置或item属性
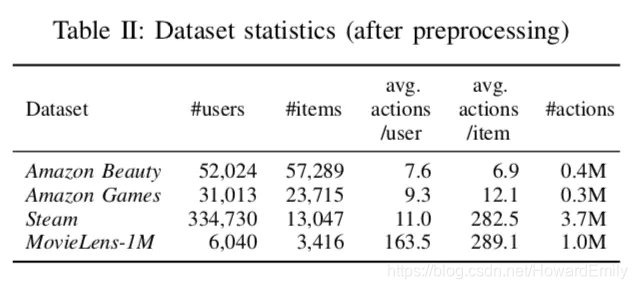
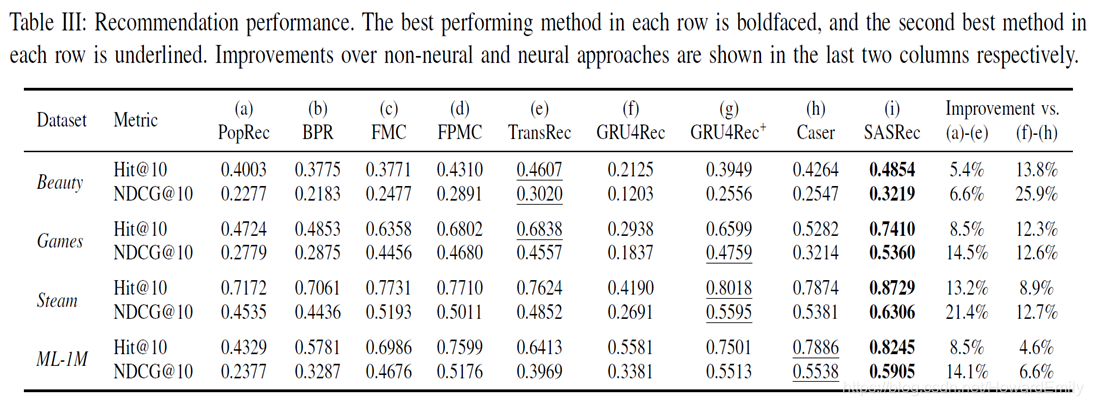
在下面三个数据集上进行了实验:
讨论
-
本文的motivation/contribution是什么?
SASRec主要是通过引入Self-attention机制解决Seq Rec问题,表面上其就是引入了Transformer的Encoder结构,直接应用到Seq Rec问题,并进行微小的改进,比如positional embedding。但是整体的角度还是比较新颖,且方法有效,而且在model 速度方面确实提升很大! -
实验细节以及实验效果如何?
仔细研读论文可以发现,SASRec尽管在效果方面有不错的提升,但是其本质上是一个基于协同排序,Collaborative Ranking的评估方法,这种方法其实并不算公平。而且其每次只是采样100个负样本(如果没记错的话)。 -
具体的应用场景?
上面说到,实验部分是进行采样的,这是一个比较成熟和广泛应用的技术,所以SASRec的效果在推荐系统的排序方面应该会适合。 -
本文存在什么不足?
现有的Seq Rec方法都是基于Seq2item的方法的,也就是给定用户的t时刻之前的交互序列,并用其下一时刻 x t + 1 x_{t+1} xt+1作为label对模型进行训练。
上面的基于Seq2item的方法可能会给模型带偏,比如"skirt skirt skirt skirt trousers"这种序列就会使得模型在点击skirt更多的推荐skirt,所以今年有paper提出了Seq2Seq方法:
《Disentangled Self-Supervision in Sequential Recommenders》WWW‘20
个人认为,这会是将来Seq Rec 比较热门的topic!















 900
900











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











