






多类分类任务
有两种分类:
- 1对其他
- 多项分布
一对其他(One-vs-Rest, OvR)
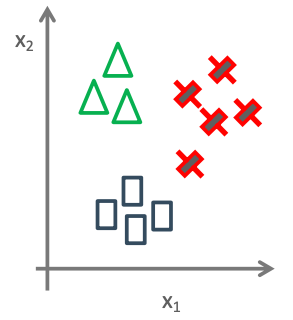
三个分类器:
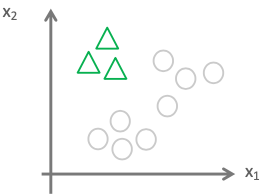
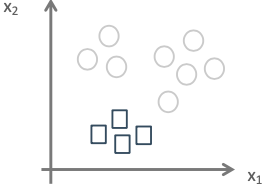
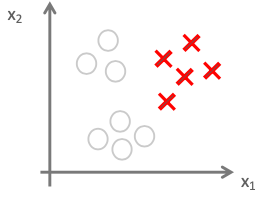
上述通过三个分类器分别是C1,C2,C3。每类的模型都有自己正则参数和权重参数。每个分类器是单独训练得到的。
OvR如何对新样本进行分类?
对于一个需要预测的样本,通过每个分类器模型对该样本做预测,每个分类器都会返回该样本的概率。然后选择概率最大的类别作为该样本的类别。即:
y
^
=
a
r
g
m
a
x
c
f
w
c
(
x
)
\hat{y} = \underset{c}{argmax}f_w^c(x)
y^=cargmaxfwc(x)
多项式分布
在logistic中,伯努利分布的输出只有两种取值。而Multinoulli分布,称为范畴分布,输出有K种取值。
所以,我们就可以用Multinoulli分布描述多分类的概率分布,其参数为向量
θ
=
(
θ
1
,
θ
2
,
⋯
,
θ
C
)
\theta=(\theta_1, \theta_2,\cdots,\theta_C)
θ=(θ1,θ2,⋯,θC),其中
∑
c
=
1
C
θ
c
=
1
\sum_{c=1}^C\theta_c = 1
c=1∑Cθc=1
其中,每一个分量
θ
c
\theta_c
θc表示第
c
c
c个状态的概率,我们用符号
C
a
t
(
y
;
θ
)
Cat(y;\theta)
Cat(y;θ)表示。
- Multinoulli分布的概率密度函数为:
C
a
t
(
y
;
θ
)
=
Π
c
=
1
C
θ
c
y
c
Cat(y;\theta)=\Pi _{c=1}^C \ \theta_c^{y_c}
Cat(y;θ)=Πc=1C θcyc
标量形式记为: C a t ( y ; θ ) = Π c = 1 C θ c I ( y = c ) Cat(y;\theta)=\Pi_{c=1}^C\ \theta_c^{I(y=c)} Cat(y;θ)=Πc=1C θcI(y=c)
其中, I I I为指示函数,当括号中条件满足时,函数值为1,否则为0。
softmax分类器
类似两类分类模型推导,假设输出
y
=
k
y=k
y=k的概率可以由x的线性组合再经过sigmoid函数变换得到。
对于K个标量
x
1
,
x
2
,
⋯
,
x
k
x_1,x_2,\cdots,x_k
x1,x2,⋯,xk,softmax函数:
z
k
=
s
o
f
t
m
a
x
(
x
k
)
=
e
x
k
∑
i
=
1
K
e
x
i
z_k=softmax(x_k)=\frac{e^{x_k}}{\sum_{i=1}^K\ e^{x_i}}
zk=softmax(xk)=∑i=1K exiexk
其中,
z
k
∈
[
0
,
1
]
,
∑
i
=
1
K
z
k
=
1
z_k \in [0, 1], \sum_{i=1}^Kz_k=1
zk∈[0,1],∑i=1Kzk=1
若
x
k
=
w
T
x
x_k = w^Tx
xk=wTx,将式子代入可得:
p
(
y
=
c
∣
x
,
w
)
=
e
w
T
x
∑
k
′
=
1
K
e
w
k
′
T
x
p(y=c|x, w)=\frac{e^{w^Tx}}{\sum_{{k}'=1}^K e^{w_{k'}^T x}}
p(y=c∣x,w)=∑k′=1Kewk′TxewTx
此式子为模型,得到的分类器被称为Softmax分类器。
Softmax分类模型的log似然函数
μ
k
=
p
(
y
=
k
∣
x
,
w
)
=
e
w
T
x
∑
k
′
=
1
K
e
w
k
′
T
x
\mu_k=p(y=k|x, w)=\frac{e^{w^Tx}}{\sum_{{k}'=1}^K e^{w_{k'}^T x}}
μk=p(y=k∣x,w)=∑k′=1Kewk′TxewTx
使用交叉熵损失,即负log损失:
£
(
M
)
=
−
1
N
∑
i
=
1
N
l
o
g
(
Π
k
=
1
K
μ
i
k
y
i
k
)
=
−
1
N
∑
i
=
1
N
∑
k
=
1
K
y
i
k
l
o
g
(
μ
i
k
)
\pounds(M)=-\frac{1}{N}\sum_{i=1}^Nlog(\Pi_{k=1}^K\ \mu_{ik}^{y_{ik}})=-\frac{1}{N}\sum_{i=1}^N\sum_{k=1}^Ky_{ik}log(\mu_{ik})
£(M)=−N1i=1∑Nlog(Πk=1K μikyik)=−N1i=1∑Nk=1∑Kyiklog(μik)
其中
y
i
k
y_{ik}
yik是第
i
i
i个标签one-hot向量表示的第k个维度的元素值。
以上就是Softmax损失。
- 优化方法和两分类一致,使用梯度下降法,如下:
∂ £ ( W ) ∂ W = − 1 N ∑ i = 1 N X i ^ ( y i − y i ^ ) T \frac{\partial \pounds(W)}{\partial W}=-\frac{1}{N}\sum_{i=1}^N \hat{X_i}(y_i-\hat{y_i})^T ∂W∂£(W)=−N1i=1∑NXi^(yi−yi^)T
采用梯度下降法,初始化W=0,进行迭代
W t + 1 ← W t + α ( 1 N ∑ i = 1 N X i ^ ( y i − y i ^ W t ) T ) W_{t+1} \leftarrow W_t + \alpha(\frac{1}{N}\sum_{i=1}^N \hat{X_i}(y_i-\hat{y_i}^{W_t})^T) Wt+1←Wt+α(N1i=1∑NXi^(yi−yi^Wt)T)
其中, α \alpha α是学习率, y i ^ W t \hat{y_i}^{W_t} yi^Wt是当参数 W t W_t Wt时模型的输出。
Scikit-Learn中实现多分类
- 参数multi_class:
- ‘ovr’:1对其他
- ‘multinomial’:Softmax回归分类,对多项分布概率整体进行训练
注意:multi_class选择会影响优化算法solver参数的选择,OvR:可用所有的slover;Multinomial:只能选择newton-cg,lbfgs和sag/saga(不支持liblinear)















 632
632











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









