








词云介绍
词云,又称文字云,是文本数据的视觉表示,由词汇组成类似云的彩色图形,用于展示大量文本数据。每个词的重要性以字体大小或颜色显示
词云(Word Cloud)主要用来做文本内容关键词出现的频率分析,适合文本内容挖掘的可视化。词云中出现频率较高的词会以较大的形式呈现出来,出现频率较低的词会以较小的形式呈现
词云的本质是点图,是在相应坐标点绘制具有特定样式的文字的结果
功能:对比文字的重要程度,快速感知最突出的文字
适合的数据条数:超过30条数据
练习案例:使用Power BI制作词云图
数据源(部分截图)

制图要点:引入自定义视觉对象Word Cloud,设置类别(Category)和数值(Values)两个参数
具体操作步骤如下所示
步骤1:将上述数据导入进Power BI进行数据清洗以及数据建模后,单击"可视化"窗格中的"..."

选择"获取更多视觉对象",输入"Word Cloud",引入词云


选择相应字段,然后调整可视化图表的格式,结果如下图所示
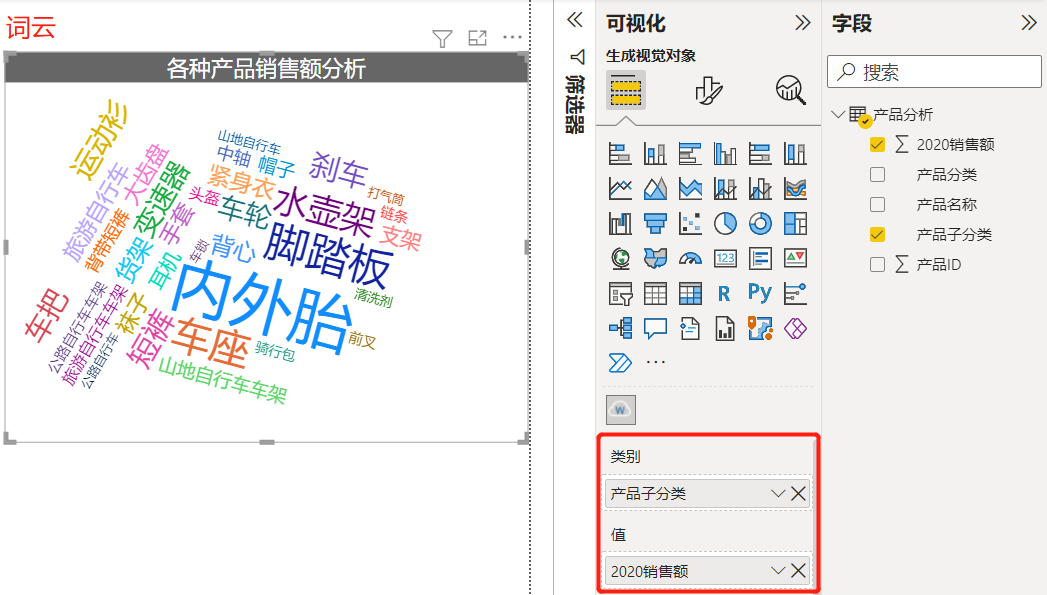
从词云展示的结果可以看出内外胎、脚踏板等销量最高
注意
1.当数据的区分度不大时使用词云起不到突出的效果
2.当数据太少时很难布局出好看的词云,推荐使用柱状图
词云适合大量数据,柱状图适合少量数据
词云展示文字更为直观,柱状图需要借助坐标轴和刻度表示文字的分类和数据

















 4万+
4万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









