







近年来Transformer不管是在NLP、CV、推荐等领域都有比较大的应用,短短4年左右的时间Attention Is All You Need 文章的引用量接近3万,其实Transformer原先是解决在sequence2sequeence任务中RNN的并行性差、CNN远距离依赖性弱的问题,本文主要从这篇文章出发解读Transformer的原理、作者为什么要这么设计网络结构。
一、网络整体架构
首先认识一下它的网络架构,然后再对它庖丁解牛。如图1所示,它是一个encoder-decoder的架构形式,左边为一个encoder中的一个layer,原文中这样的layer总共有6层,右边为一个decoder中的一个layer,原文中这样的layer总共也有6层,最后通过一个线性层和softmax输出每个类别的概率。
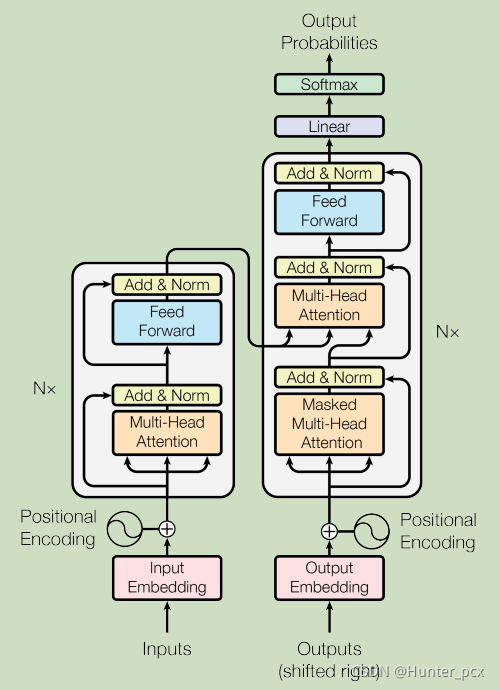
图1 transformer模型架构
二、输入和输出
然后再看架构的两个输入代表什么意思,一个是encoder的收入Inputs,一个是decoder的输入Outputs。这里拿汉译英举例,比如我想要将“我是谁?”翻译成英语"Who am I ?",那么encoder的输入就是整个汉语句子”我是谁?“,由6层layer组成的encoder对整个汉语句子进行编码;那么decoder的输入和输出又是什么呢?如果了解RNN系列机器翻译的童鞋就知道,一般RNN不是一次性的就能翻译好整个句子,而是一个单词一个单词的按照顺序翻译出来,比如这里首先要翻译出”Who“,然后逐次再翻译”am“、”I“、”?“,每次翻译下一个单词的时候decoder需要输入先前翻译出的所有单词然后根据条件概率预测下一个单词,比如此时已经翻译到”Who am“,那么此时decoder输入的就是”Who am“,输出的就是”I“的条件概率。
需要说明的是网络并不是直接输入汉语字符和英文单词,而是先对每个汉语字符、英文单词进行embedding成一系列的向量,然后才输入给网络。
三、Positional Encoding(位置编码)
即对每个汉语字符或者英文单词的位置进行编码,为了便于后续描述,我们将每个汉语字符以及英文单词称为一个token。下面讲讲为什么要对token的位置进行编码,举例来说一些单词它的含义跟它在句子中的位置是有关系的,它放在句子中不同的位置含义是不一样的,而Transformer的编码方式是基于Attention机制,网络根本不知道单词之间的先后顺序以及相对的位置关系,所以才需要显示的将位置信息输入给网络。
你可以用任何方式对token位置进行编码,只不过你这种编码方式能让网络越容易识别就越好。作者选择了用正弦和余弦函数进行编码:
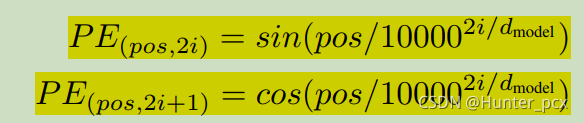
这里pos表示的是token在句子中的位置,PE(pos,2i)和PE(pos,2i+1)分别表示编码向量中第2i和第2i+1个分量,dmodel表示编码向量的维度。 作者这么设计说是因为如果固定k,PE(pos+k)是PE(pos)的线性函数,这样网络更容易识别。
四、Encoder layer
然后我们再看组成encoder的每一层,既然是一个encoder,按道理来说你无论用CNN、RNN还是MLP等架构都是可以work的,作者既然这么设计那肯定说明它还是有比这些layer优势的地方。encoder layer主要由两个子部件组成:Multi-Head Attention、Fead Forward,为了构建比较深的网络每个子部件采用残差的连接方式,为了训练起来更加稳定每个子部件后面接了一个归一化操作。Multi-Head Attention的结构我们后面再说,这里我们只要知道这个部件里面是没有网络的可学习参数的,它只是对上一layer输出的tensor进行一些运算而已;Fead Forward是一个线性层后接ReLu的激活函数,然后再接一个线性层:
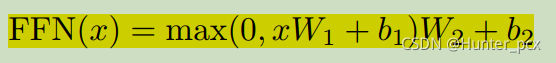
这里W1和W2都是网络中的可学习参数。至于Multi-Head Attention后面接一个Fead Forward的原因估计很多人现在看出来了吧,因为Multi-Head Attention里面没有网络的可学习参数啊,所以后面要接一个网络了。
由于这里的Multi-Head Attention的三个输入都是来自于Encoder的上一layer的同一个输出,所以这里的注意力机制其实是一个Self-Attention。至于为什么要选择这样一个结构而不用RNN、CNN这样的layer,大家看下如下表就知道了,只要知道从下表的三个指标综合来看Self-Attention是优于RNN和CNN的就行了,具体的分析可以去看看作者原文。

五、Decoder layer
然后我们再来看看Decoder的layer,它主要是由三个子部件组成:Masked Multi-Head Attention、Multi-Head Attention、Fead Forward。
Masked Multi-Head Attention的输入是上一layer的输出,所以它是一个Self-Attention,它的结构其实就是在Multi-Head Attention的基础上添加了mask屏蔽机制,至于为什么要加这个mask屏蔽机制以及怎么加上去的这个我们后面会再讲。至于都是Self-Attention,那么这里不选择RNN和CNN等layer的原因其实跟encoder layer里面的原因就一样了。
Multi-Head Attention这里的输入一部分是来自于encoder的输出,另一部分是来自于上一decoder layer的输出。它的作用是让decoder的输出能注意到encoder输出的所有位置,还是拿汉译英举个不恰当的例子,比如汉语是“小明是小强的朋友,他喜欢和小强待在一起。”,decoder已经翻译到“XiaoMing is XiaoQiang's friend,he”,那么此时这个“he”到底指代谁呢?通过Multi-Head Attention可以让decoder注意到整个汉语句子,并分析出“he”是指代“小明”。
Fead Forward的作用跟encoder layer里面的类似,输入网络中可学习的参数。
六、Multi-Head Attention
下面我们开始认识一下Transforer的核心模块Multi-Head Attention,这个模块其实是由很多称为Scaled Dot-Product Attention组成的,如图2所示,因此我们首先从Scaled Dot-Product Attention讲起。
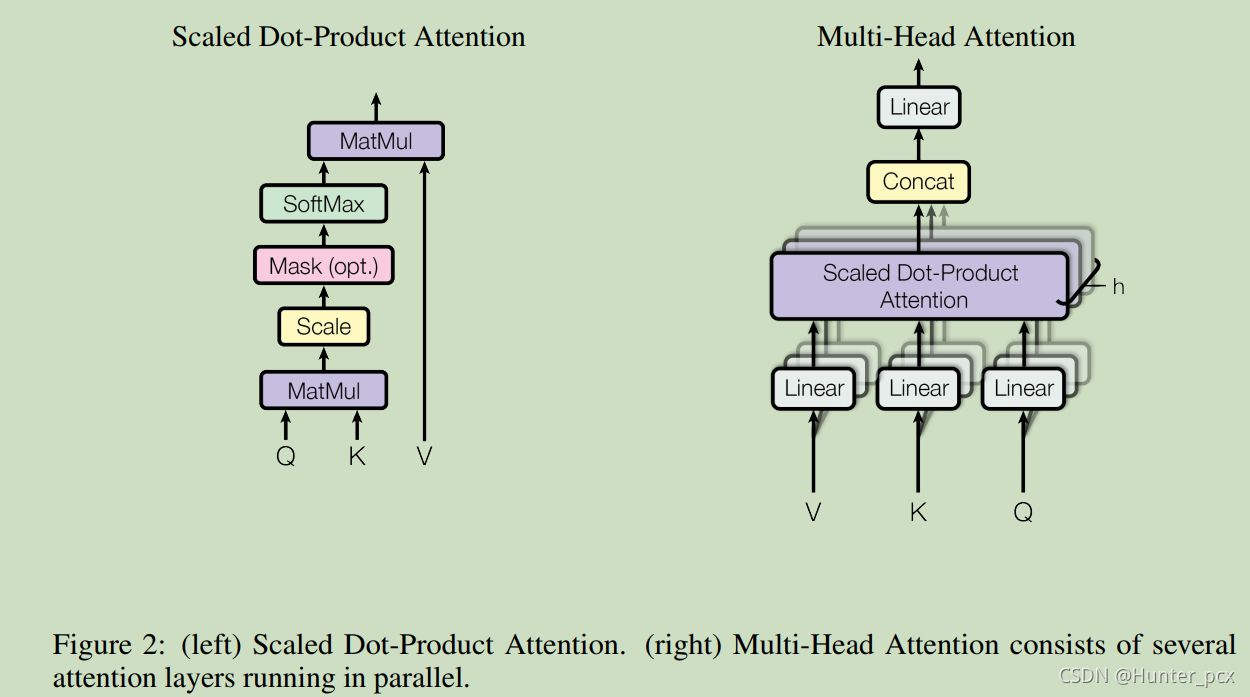
这个注意力运算公式如下所示,它其实是一个键值查询过程,可以理解为我们有一个字典,字典里面有很多key-value这样的数据对,然后在这个字典里面查询一条记录q(它的维度和key的维度一样)对应的value是多少,这样就可以很简单的先求出q与每个key的相似度,最后相似度最高的key对应的value就是记录q的value了,只不过这里相似度是通过两个向量的点积计算得到的,并且q的value是字典中所有value的加权和。
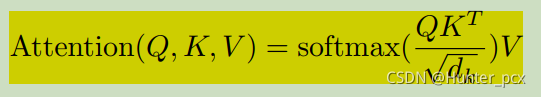
类似的,如果字典中有N个key-value数据对,每个key是维度为dk的向量,每个value是维度为dv的向量,并且需要查询q条记录,那么张量Q的维度为qxdk,K的维度为Nxdk,V的维度为Nxdv,最后Q的查询值就可以通过上式计算得到的维度为qxdv。这里要除以根号d_k是为了防止Q和K矩阵乘法后数值太大,导致softmax函数的梯度接近0。
比较常用的注意力实现方式有两种:additive attention、dot-product(multiplicative) attention,至于这里为什么要选择这种乘性的注意力实现方式,作者给出的理由是这两者的计算复杂度相当,但是dot-product attention在实践中往往要更快速、具有更高效的存储。
然后再看看Multi-Head Attention,它的结构如图2右所示,它的计算方法如下式:

它其实是将输入的张量先投影到一些子空间中,这些子空间的维度是小于输入张量的维度的,然后在将这些子空间中的投影张量分别应用Scale Dot-Product Attention得到head_i,最后再将这些输出concat起来并投影到原先的维度上。这里Wi_Q、Wi_K、Wi_V、WO都表示可学习的投影矩阵。比如文章中输入张量的维度为512维,然后投影到8个子空间中,每个子空间的维度是64维,然后每个子空间采用不同的Scale Dot-Product Attention输出head_i,然后将所有的head拼接起来并投影回512维的空间。
这么拆分之后计算量跟没拆的计算量其实是相当的,好处就是可以提升网络表现效果,Multi-Head Attention可以综合考虑来自各个子空间表示的注意力信息,而single-head attention相当于把这些子空间表示的注意力信息平均了。
七、Masked Multi-Head Attention
现在我们来讲一下最后一个模块,上面提到decoder翻译的时候是按照顺序一个单词一个单词吐出来的,吐出下一个单词的时候是需要根据前面已经吐出来的单词做条件概率预测。比如还是拿前面提到的汉译英举例,encoder输入“我是谁?”,decoder此时假设已经吐出了“Who am”,预测第三个单词“I”的时候decoder输入的是"Who am",此时decoder不可能看到第三个单词之后的内容(比如这里是“?”),所以decoder吐出的每个单词只跟它前面的单词有关,所以为了让attention只注意到前面的单词只有对后面部分的单词屏蔽掉。而这里屏蔽的方法就是将相似度矩阵的相应位置元素置为负无穷大,然后经过softmax之后权重就变为0了。
说明:鄙人只是NLP领域的小白,解读Transformer这篇文章是根据原文加自己的理解,如果有错误的地方还请各路大佬斧正。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









