







近年来,TTS(Text-to-Speech,文本转语音)模型经历了从拼接式语音合成到统计参数合成,再到神经网络 TTS(Neural TTS)的迭代,在技术层面呈现出端到端、模块融合的趋势,在应用层面呈现出多语言、高自然度、丰富情感变化的效果升级。
随着 TTS 模型在虚拟语音助手、数字人、 AI 配音、智能客服等领域广泛应用,业界对其实时性反馈的需求也逐渐提高,随之而来的是推理速度与模型参数之间的平衡,后者在某种程度上限制了 TTS 模型的部署成本及应用场景。
针对于此,Fish Audio 推出了全新的开源 TTS 模型 OpenAudio S1,其包含 OpenAudio-S1 和 OpenAudio-S1-mini 两个版本。据官方文档介绍,OpenAudio S1 在超过 200 万小时音频的大规模数据集上进行训练,团队将模型参数扩展至 40 亿,并引入自研的奖励建模机制(reward modeling),同时还应用了基于人类反馈的强化学习(RLHF,采用 GRPO 方法)训练。
基于此,OpenAudio S1 成功消除了其他大多数模型采用仅语义模型时,因信息丢失而产生的伪影和错误词汇,从而在音频质量、情感表达和说话人相似度方面远超以往模型,仅输入 10 到 30 秒的语音样本就能够生成高质量的 TTS 输出。其目前已经登顶 HuggingFace 的 TTS-Arena-V2 人类主观评估排行榜。在 Seed-TTS Eval 上实现约 0.4% 的低 CER(字符错误率)和约 0.8% 的 WER(词错误率)。
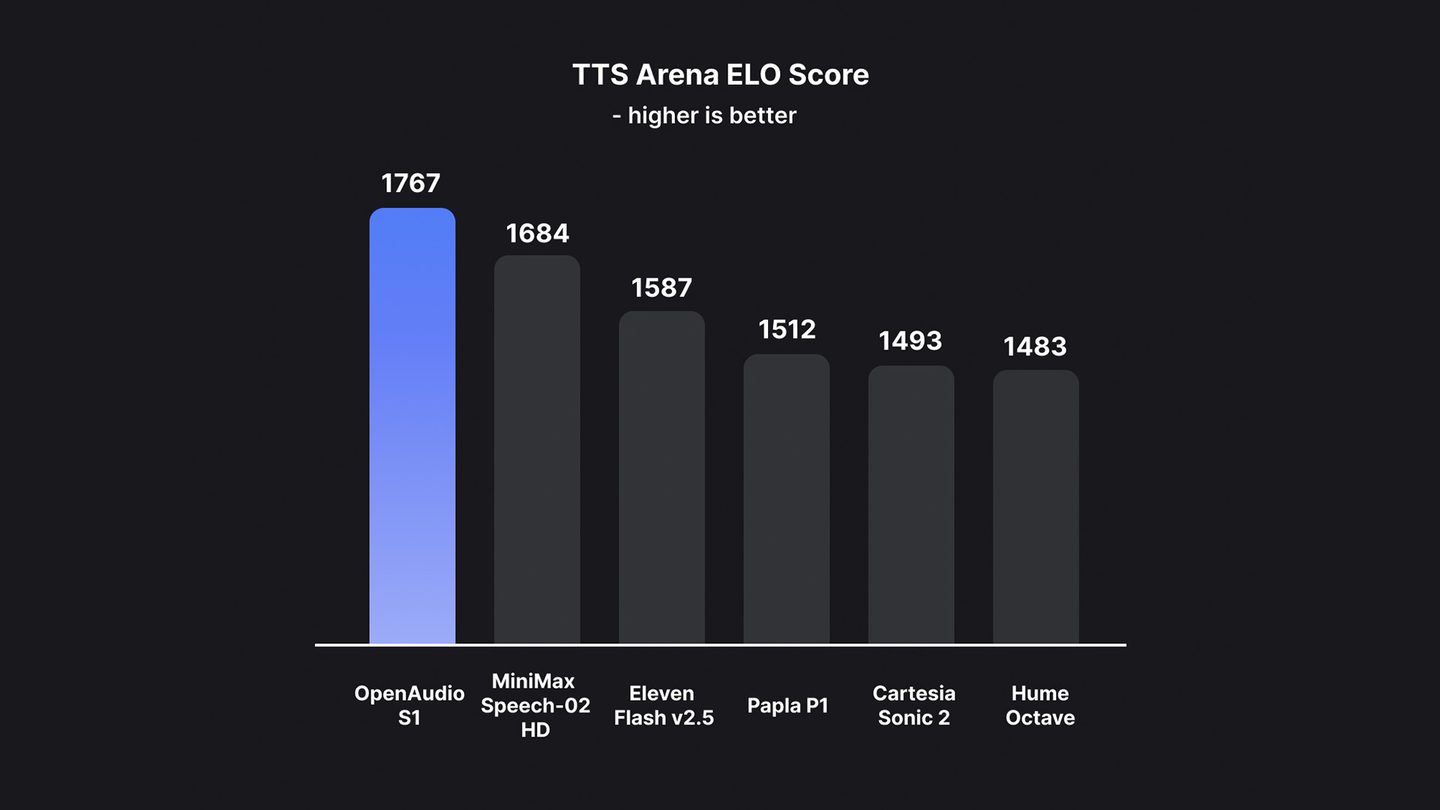
模型在 HuggingFace TTS-Arena-V2 ELO 的得分(截至 2025 年 6 月 3 日)
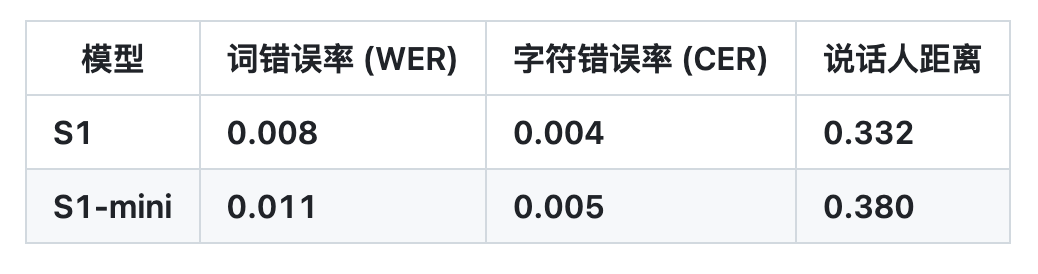
Seed TTS 评估结果
据该团队介绍,OpenAudio S1 真正与众不同之处在于其对人类情感和语音细节的深刻理解与表现能力,支持丰富的标记集,可精确控制合成语音。而为了训练 TTS 模型遵循指令的能力,团队还构建了一个语音转文字模型(即将发布),能够为音频生成包含情感、语调、说话人信息等内容的字幕。随机基于该模型标注了超 10 万小时的音频来训练 OpenAudio S1 。
正因如此,OpenAudio S1 支持多种情感、语调和特殊标记来增强语音合成,除了基础的生气、惊讶、高兴等情感外,还支持鄙视、讽刺、犹豫等高级情感,在语调方面支持耳语、尖叫、抽泣等等。在语言方面,目前已经支持了英语、中文和日语。
更加值得一提的是,在性能与部署成本的平衡问题上,该团队称这是首个每百万字节仅需 15 美元($15/million bytes,约 0.8 美元/小时)的 SOTA 模型。
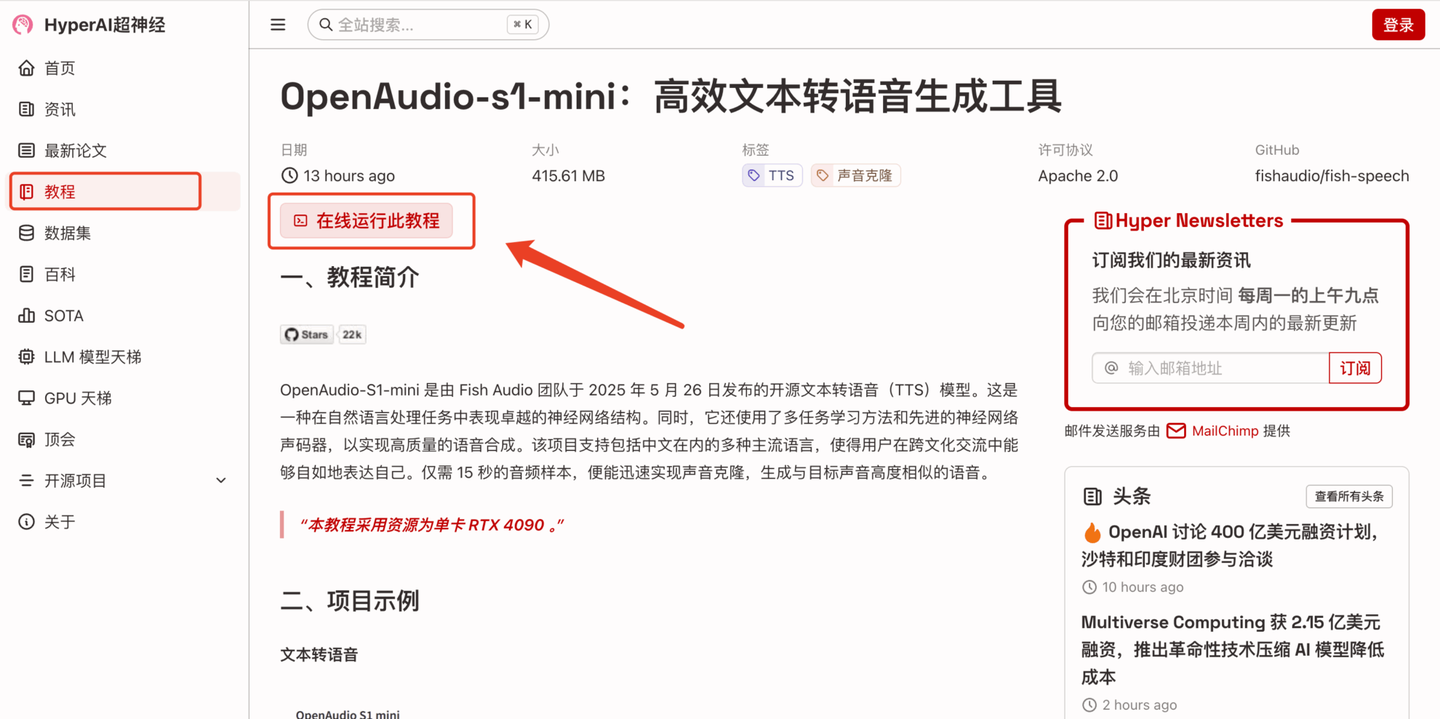
为了让大家更快地体验到 OpenAudio S1 的强大性能,HyperAI 超神经官网(hyper.ai)的教程板块现已上线了「OpenAudio-s1-mini:高效文本转语音生成工具」。
教程链接:OpenAudio-s1-mini:高效文本转语音生成工具 | 教程 | HyperAI超神经
我们还为新注册用户准备了 RTX 4090 资源免费使用福利,使用下方邀请码注册有机会零成本体验高质量 TTS 模型。
HyperAI 超神经专属邀请链接(直接复制到浏览器打开):
Demo 运行
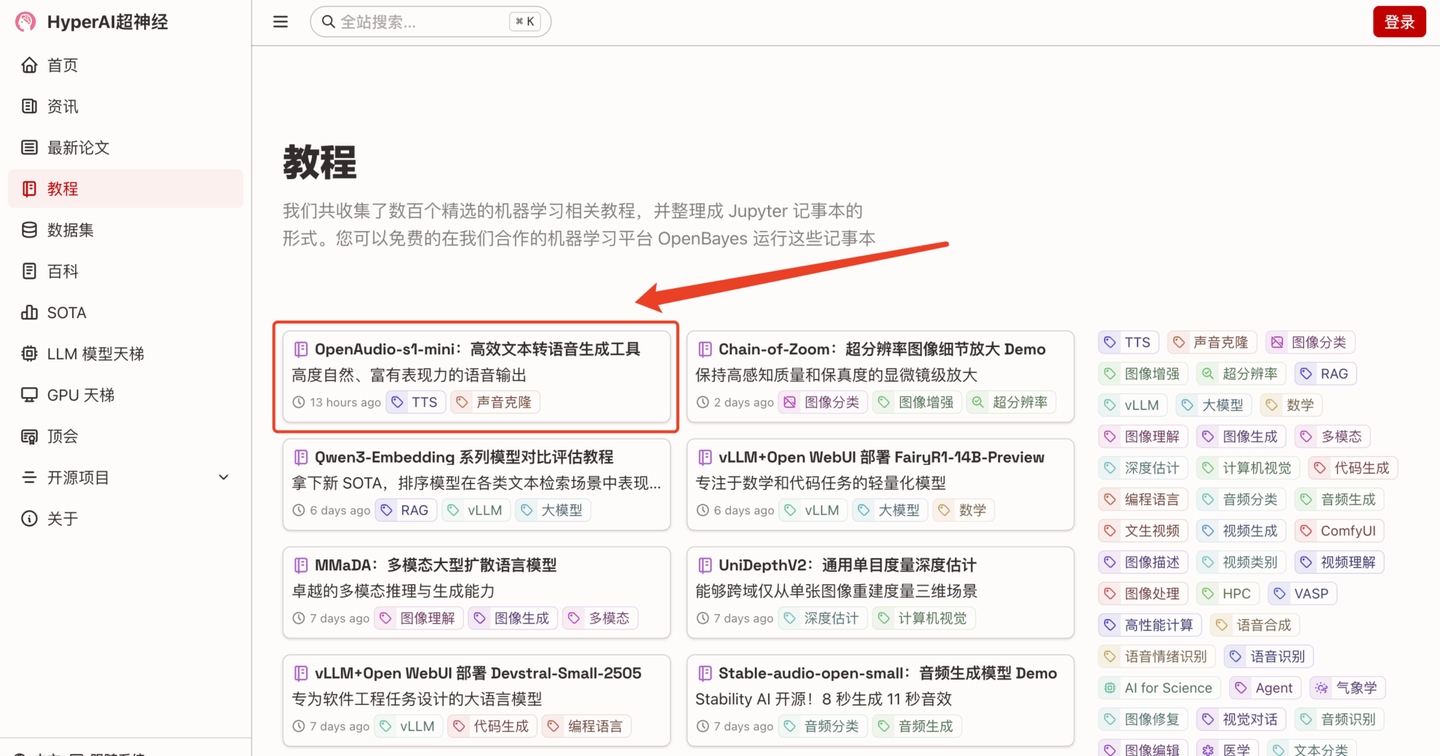
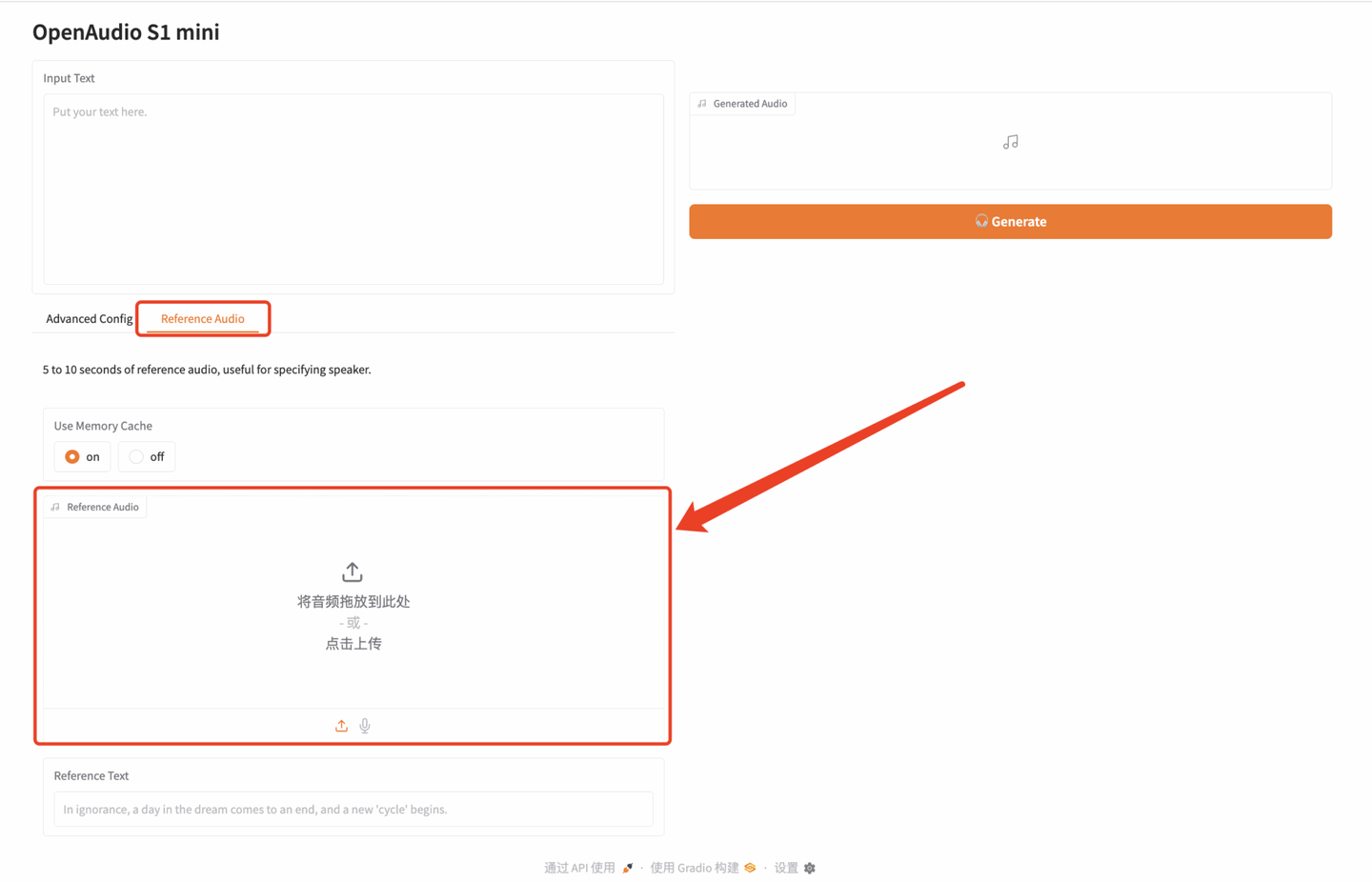
1. 进入 hyper.ai 首页后,选择「教程」页面,并选择「OpenAudio-s1-mini:高效文本转语音生成工具」,点击「在线运行此教程」。
2. 页面跳转后,点击右上角「克隆」,将该教程克隆至自己的容器中。
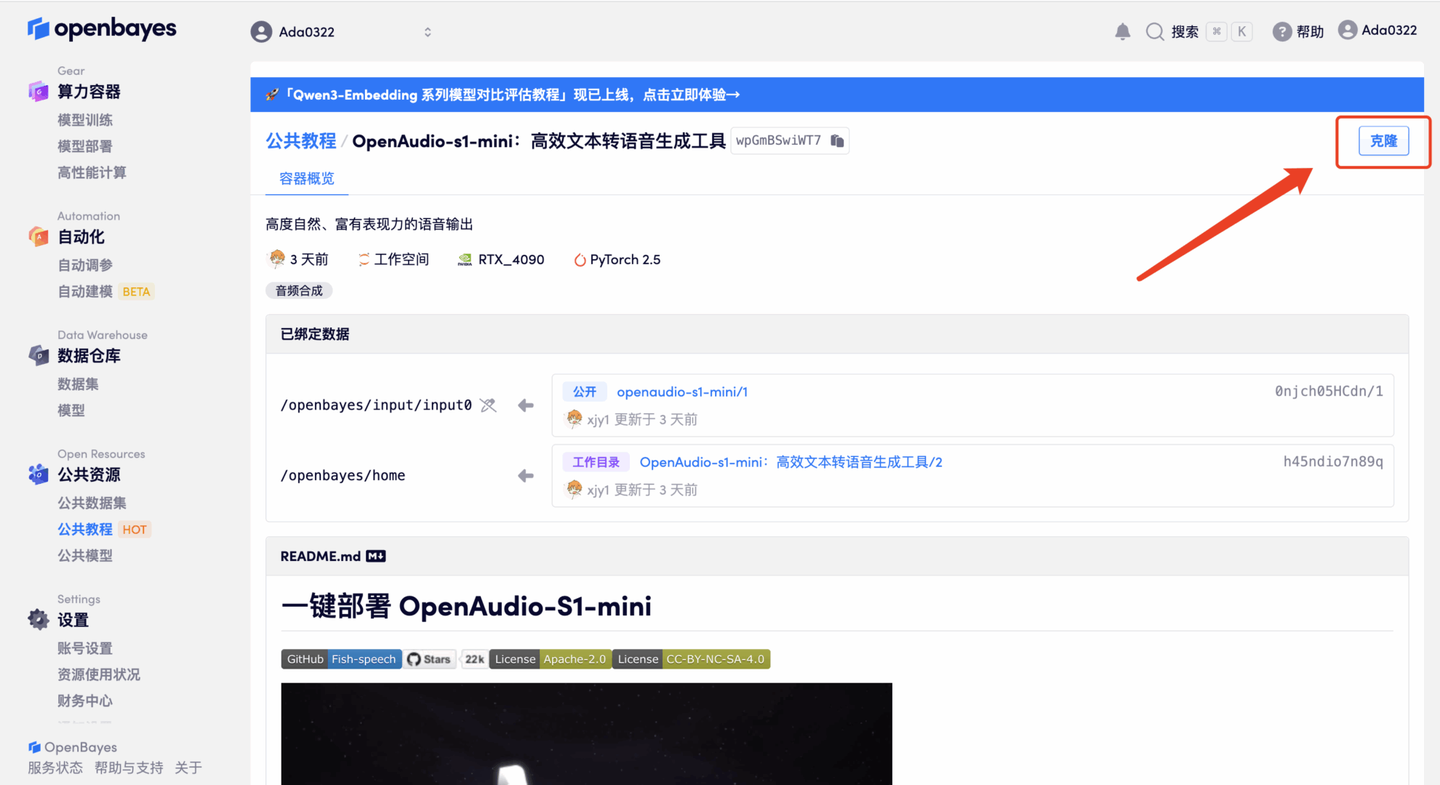
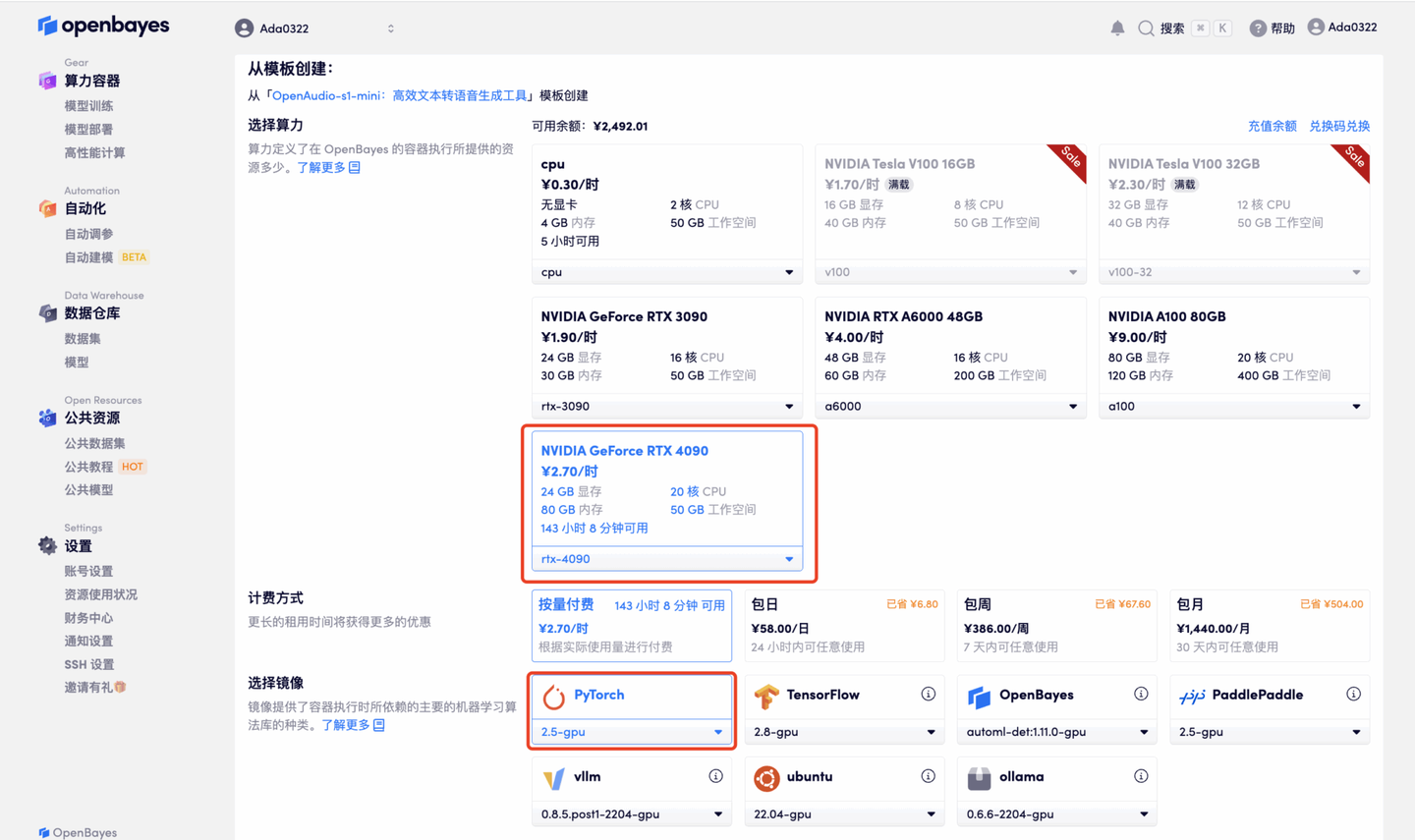
3. 选择「NVIDIA RTX 4090」以及「PyTorch」镜像,OpenBayes 平台提供了 4 种计费方式,大家可以按照需求选择「按量付费」或「包日/周/月」,点击「继续执行」。新用户使用下方邀请链接注册,可获得 4 小时 RTX 4090 + 5 小时 CPU 的免费时长!
HyperAI 超神经专属邀请链接(直接复制到浏览器打开):
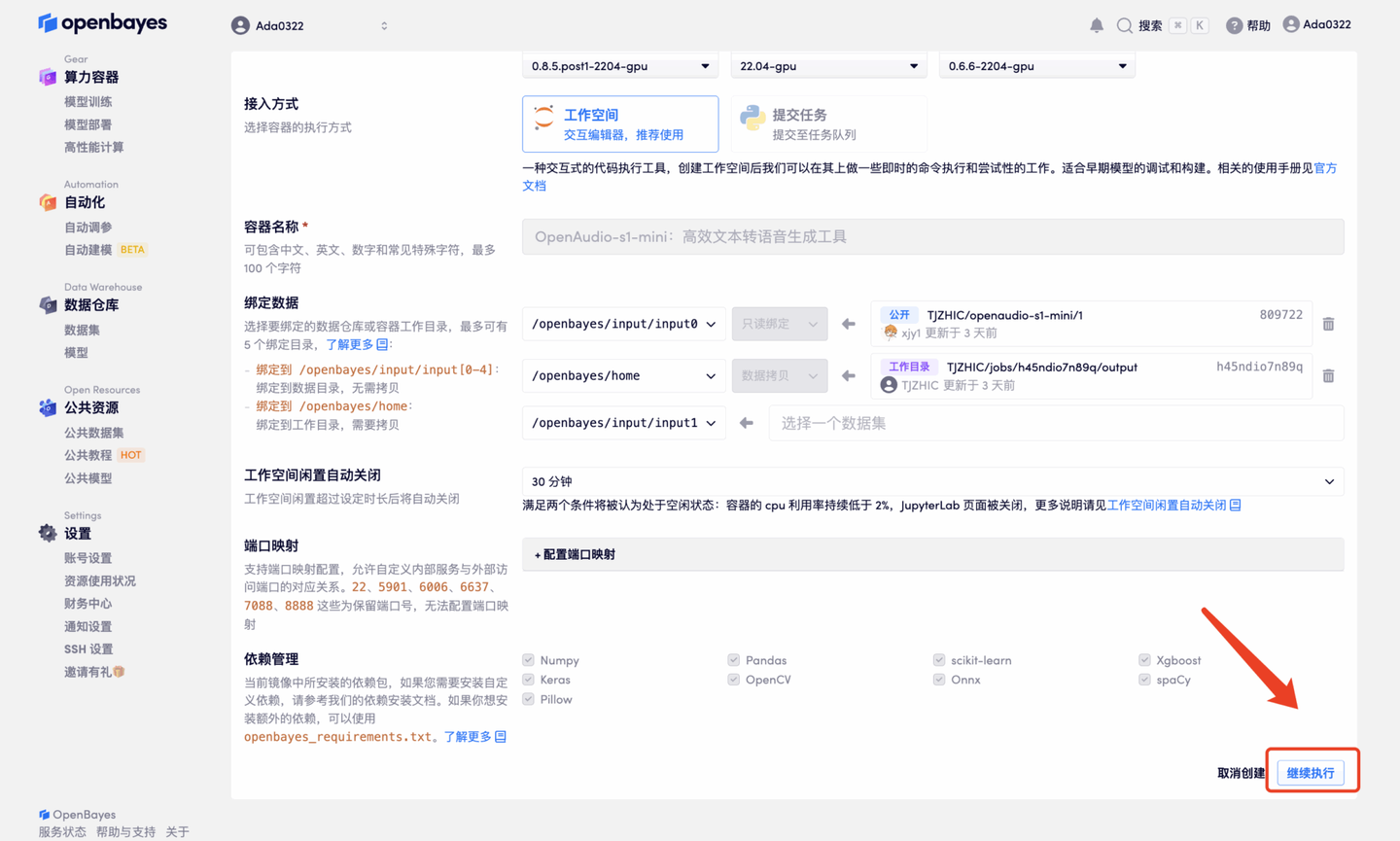
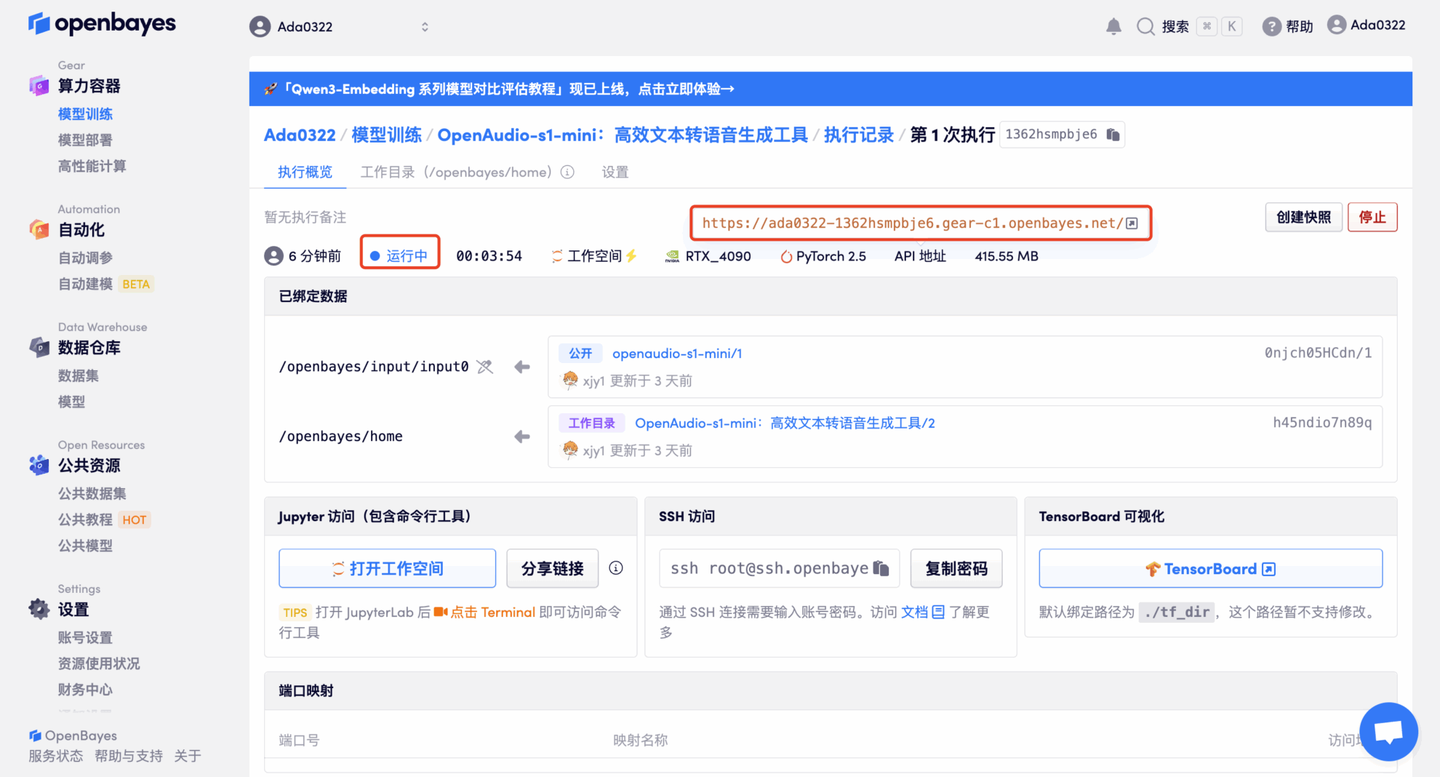
4. 等待分配资源,首次克隆需等待 2 分钟左右的时间。当状态变为「运行中」后,点击「API 地址」旁边的跳转箭头,即可跳转至 Demo 页面。由于模型较大,需等待约 3 分钟显示 WebUI 界面,否则将显示「Bad Gateway」。请注意,用户需在实名认证后才能使用 API 地址访问功能。
效果演示
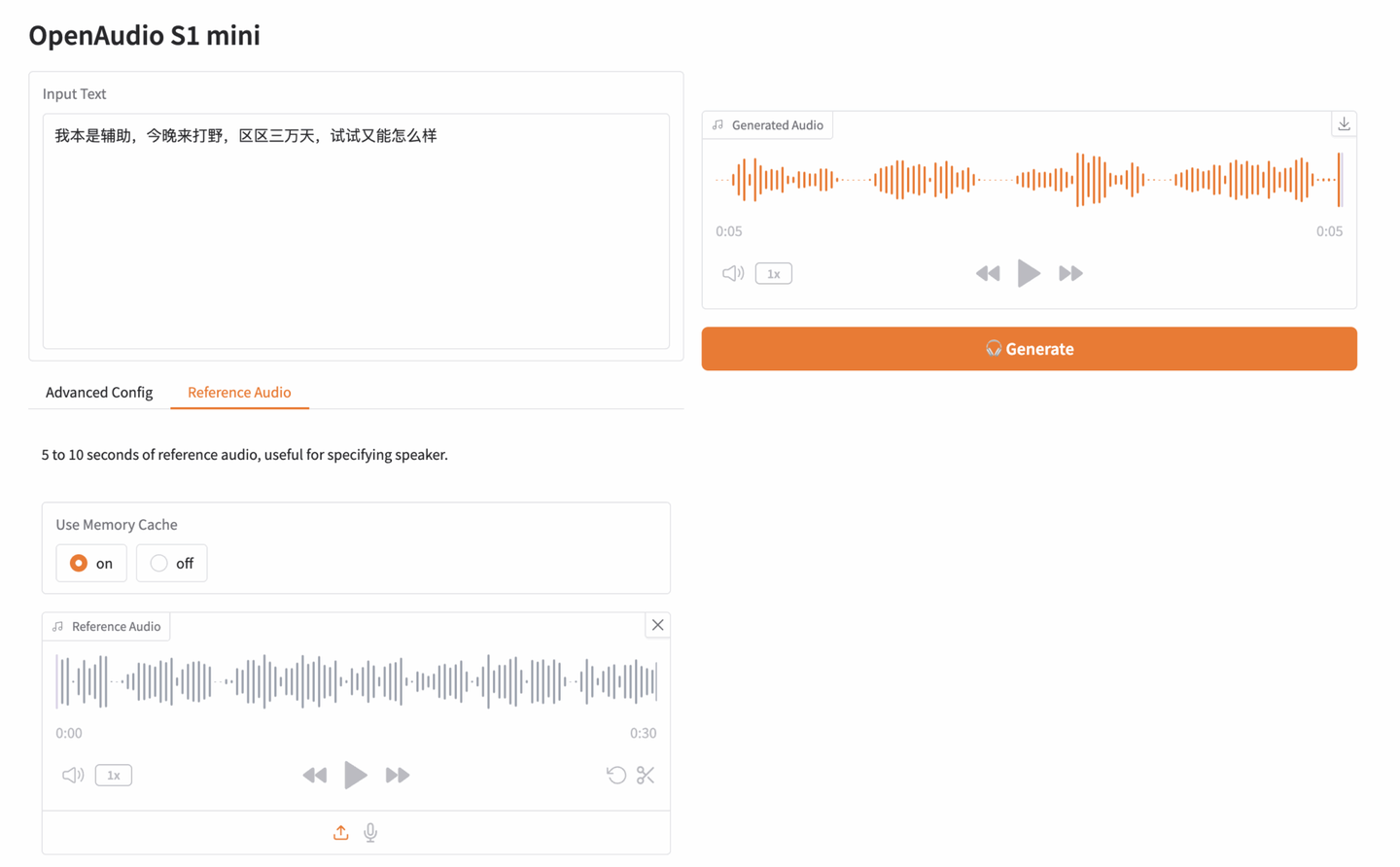
点击「API 地址」即可体验模型,笔者上传了一段原神中的任人物「派蒙」的音频,Input text 如下:
我本是辅助,今晚来打野,区区三万天,试试又能怎么样。
随后,点击右侧 Generate 即可生成音频:
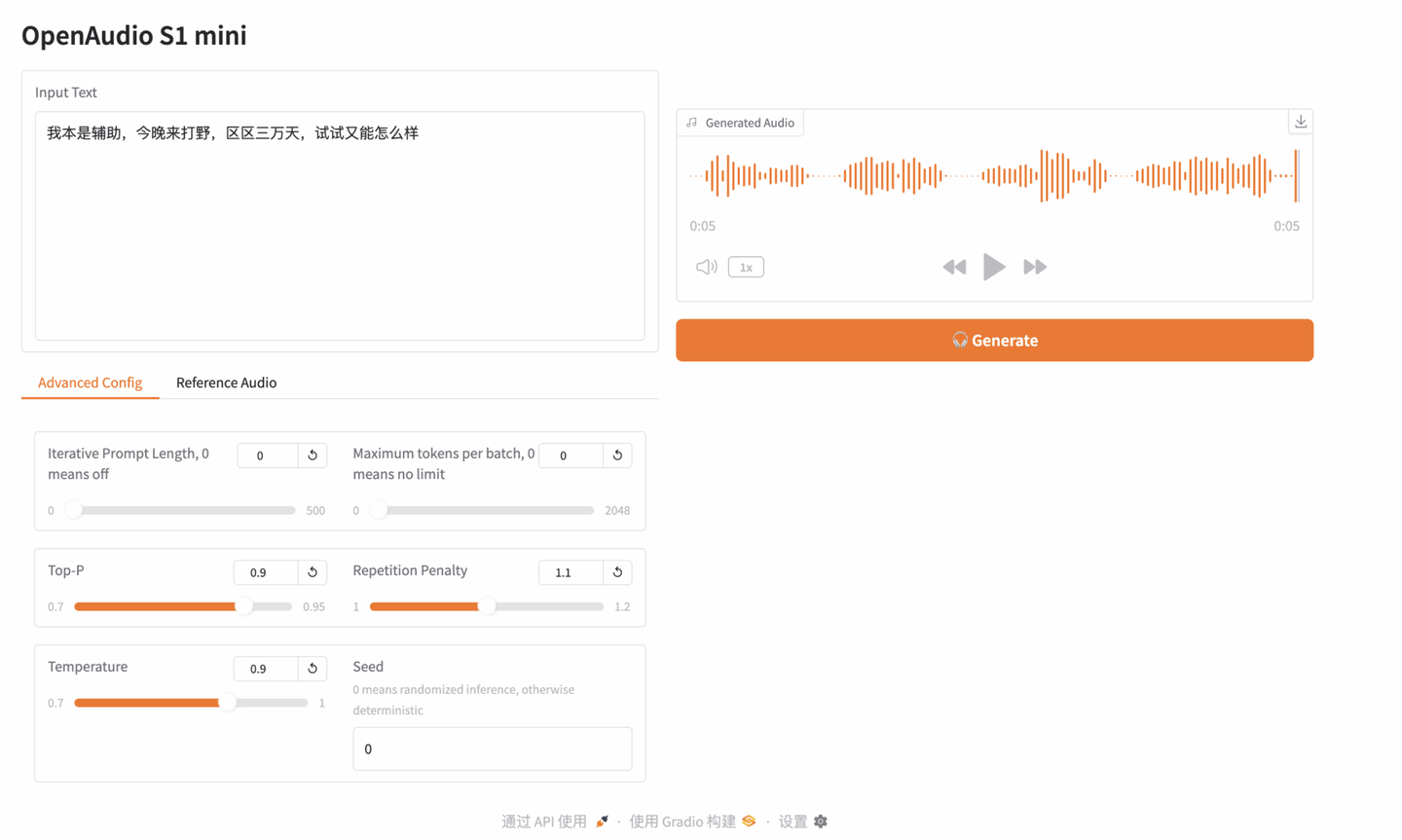
以上就是 HyperAI 超神经本期推荐的教程啦,欢迎大家在线体验:

















 21万+
21万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









