







BasicVSR: The Search for Essential Components in Video Super-Resolution and Beyond
Abstract
VSR(Video super-resolution)任务相对于SIR任务来说,其额外信息为时间维度(temporal dimension),如何处理质量与速度之间的平衡,复杂模型(参数量的提升)出现,那是否简单模型能实现其效果(选用核心组件)?
作者将VSR任务分成四个部分:Propagation,Alignment,Aggregation,Upsampling(根据在哪里?)
作者通过现存组件再加微调实现了BasicVSR(如何work?),更进一步实现了IconVSR(Information-refill mechanism and coupled propagation),如何出发的呢?
Introduction
首先基础是VSR任务的数据即多帧图像之间存在微小误差但却高度相关,为了解决这个问题模型结构越来越复杂。
- EDVR采用多尺度可变形对齐模块和多个注意层对不同帧特征进行对齐和集成
- RBPN采用多个投影模块(具体指代什么??)从不同帧(相关)之间聚合特征
作者认为这样做的缺点在于增加了模型复杂度(个人理解感觉??)为了模型的复现和比较,从功能上提出了四个步骤:

简单解释Propagation就是信息的传播方式,Alignment就是如何将具有微小误差的图像或特征进行对齐,Aggregation就是将对齐图像特征进行聚合
个人感觉如果要验证Alignment部分采用显示flow是否有作用,BasicVSR应该和BRCN作比较,而Propagation部分是否有作用,应该和FRVSR做对比。
作者针对BasicVSR在两方面做了改进,一方面在Aggregation采用information-refill,做法为从关键帧中提取特征添加到网络中做细化,另一方面在Propagation方面采用coupled propagation,其实就是将后向转播的状态作为前向传播的输入(特征混合??)
Related Work
首先大体上VSR方法分为两部分:基于sliding-window 和 recurrent
- 先前方法采用基于窗口的显示光流估计来进行空间warp以实现对齐
- 后来的方法通过复杂结构实现隐式的对齐(TDAN通过可变性卷积在特征层实现对齐;EDVR进一步使用多尺度DCNs实现对齐)
- DUF采用动态采样块实现隐式移位估计或者循环结构
- RSDN采用recurrent detailstructural block和隐藏层自适应模块来确保鲁棒性和减少误差累计
- RRN使用残差映射确保信息流和长期的纹理映射
信息填充机制基于关键帧和非关键帧,二者通常用不同方法处理。IconVSR并没有将二者分开处理,而是通过传播机制将其连接,使得长跨步信息可以相互连接。(具体如何work的呢??)
Methodology
3.1 BasicVSR

Propagation
Propagation分为三种:Local Propagation,Unidirectional Propagation,Bidirectional Propagation
-
Local Propagation:基于窗口的方法,使用窗口的的LR图像进行恢复,远距离帧间信息得不到利用(是否可以用LR图片采用级联来恢复,这里的窗口其实就是指的是选定帧的数量)
验证全局感受野??
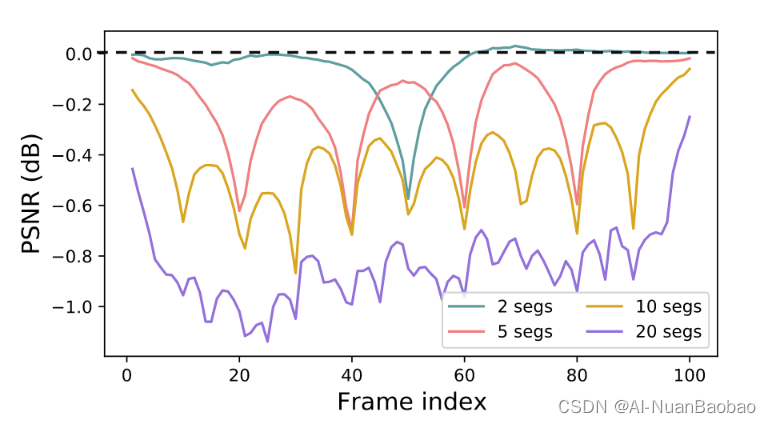
可以看到在未采用滑动窗口的情况下PSNR很大,但是可以看到窗口越小,包含的信息就越少,导致PSNR很低。个人觉得基于这样的方法对于每一个窗口来说,参考帧获得信息其实要比其他帧更多,恢复也更容易实现?
作者认为两端差异大显示了用长序列累计长信息的必要性,单个人觉得如果窗口较小是否有较大的长信息?基于窗口是否有信息的流动?
是否可以在窗口内做合适的但双向传播?窗口的大小如何确定?
- Unidirectional Propagation:解决了上述的窗口流动问题,但是这样采用的数据是整个序列(这样会不会增加复杂度)。作者在这里觉得第一帧和最后一帧之间的信息会造成不平衡(是否真的有影响?)采用双向方法会增加复杂度,如果与FRVSR比较,结果来看除了增加参数外速度和效果都要更好(双向的信息更加完全)

考虑到问题就是说在窗口内采用这种机制会不会起作用?还是说窗口内的信息很少,不需要这么复杂的机制
- Bidirectional Propagation

但是这样其实可以发现信息的流通还是单独的,是否可以在中间混合?
最大的疑问就是双向流通采用的还是未恢复的图像,正反来一次效果真的有提升吗
Alignment
Alignment也可以分三种:without alignment, image alignment, 和 feature alignment
循环网络不对齐会导致性能的弱化(为什么?为什么对齐就可以导致性能更好?)作者说实验表明不对齐会导致卷积具有更少的感受野,反正说来说去就是说考虑到的信息更多,对齐更好效果就更好(其实显然)
图像对齐与特征对齐个人感觉图像对齐其实更准确,毕竟特征看起来就很一样。
作者在特征空间执行对齐和warp

3.2. From BasicVSR to IconVSR
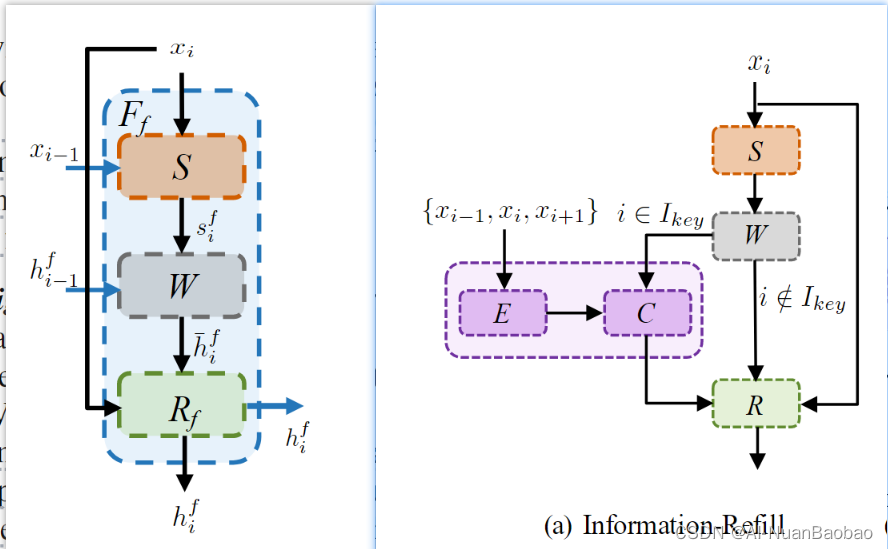
Information-Refill
其实这里我感觉长时间步一长之后特征之间的对齐就会很困难,会有误差的累积产生,比较一下二者
用公式解释如下,
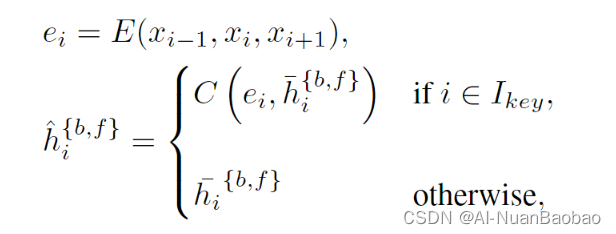
具体这样做的原理???
Coupled Propagation

前面提到过这个问题?是否可以优化















 519
519











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











