







本章我们介绍有限马尔可夫决策过程(Finite MDPs),这个问题和赌博机一样涉及到评估的反馈,但这里还多了一个方面--在不同的情况作出不同的选择。MDPs是经典的序列判定决策模型,就是说,你不是作出一个选择就会马上获得reward,和赌博机不一样,赌博机你只要摇一次臂即可立刻获得reward,而MDPs就像下象棋,你只有结束了对局你才会获得reward,但下象棋从开始到结束涉及到很多个行动,也就是要做出很多次选择才最终到对局结束。因此说MDPs的奖励是延迟的,同时MDPs还有一个即时的权值用来帮助当前决策。在赌博机情景中,我们对每一个行为a作出评估值Q(a)(原文这里是q(a),我认为评估值应该是Q,真实值才是q),而在MDPs情境中,我们则需要对行为a和状态(state)s,作出评估Q(s,a),也可以我们估计每个给定最佳动作选择的状态的V(s)值。
MDPs有严格的数学模型,我们介绍她的关键点比如返回值,值函数以及贝尔曼等式,我们想通过应用来传递有限马尔可夫的结构,像所有人工智能一样,都有其应用的范围。
3.1 代理器-环境(Agent–Environment)交互
我们把能够学习且做决策的对象称为agent,比如在无人驾驶中,车就是agent,提供给agent学习和交互的地方就叫Environment,代理器不断在环境中交互学习,而环境则给代理器反馈并提供一些状况给代理器,环境中包含有一些奖励,代理器就要在环境中实现奖励最大化。
大部分我们的代理器都是离散行动的,比如一次作出一个选择,就像下象棋,一次行一步,令t为步数t=1,2,3,...;每一步代理器都会获取环境状态(state)的信息,St ∈ S,一系列行为之后,代理器会获得这些行为的reward之和Rt+1,然后继续寻找新的state,MDPs的决策过程如下:

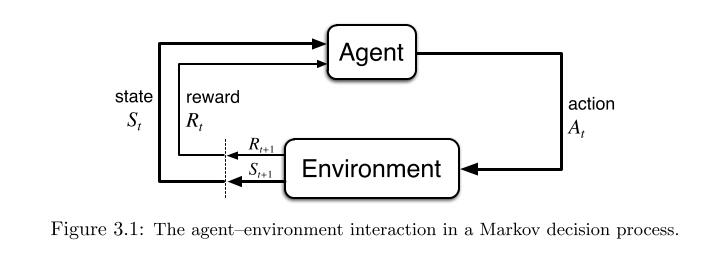
有限马尔可夫决策过程由有限个状态,行为和奖励(S,A and R)组成,随机变量Rt和St具有定义良好的离散概率分布,只依赖于先前的状态和动作,随机值s和r在t步发生的概率为:
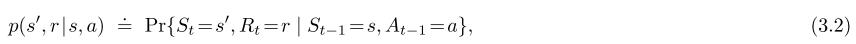
对所有s`,s,r,a,这个等式中等号上的点提醒我们是一个定义(在本例中是函数p),而不是一个与前面定义一致的事实。这个函数p:S×R×S×A→[0,1]是一个对于四个参数来说是普遍确定,式子中间那个“|”是在概率论中是条件概率,但在这里是提醒我们p是指每个s和a的概率:
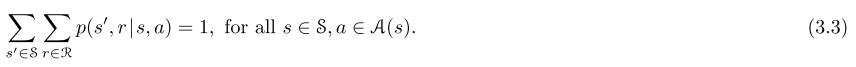
四个参数函数p给出的概率完全刻画了有限MDP的动态性质,从这个式子里,我们可以计算任何可能对环境了解的东西,比如状态转移概率(state-transition probabilities)
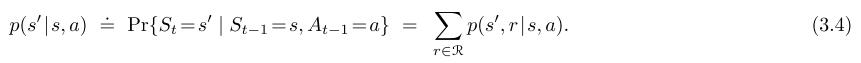
我们也能通过两个值S,A→R计算state–action的期望reward:
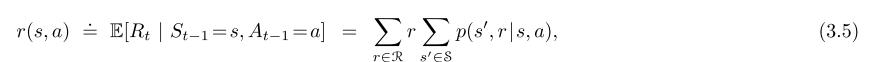
或者状态→行为→下一个状态的期望reward:
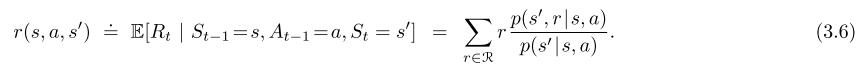
在本书中,我通常使用式子3.2,其他式子偶尔都很方便,MDP框架很抽象也很灵活,能够应用到很多种不同的情况,举个例子,在低级应用中,我们控制施加在机器人手臂上的电压来操纵手臂,在高级应用中,可以是是不吃午饭,还是去学校。同样的,state也有很多种,一个代理器可能处于不确定某个对象在哪里,或者只是在某种明确的意义上感到惊讶的状态,类似地,有些动作可能完全是心理或计算的,举个例子,有些动作可能控制代理选择思考什么,或者集中注意力,总的来说,行动可以是我们想学做的任何决定,而state可以是我们所知道的任何可能有用的决策。
代理和环境之间的边界通常不等同于机器人或动物身体的物理边界,机器人及其传感硬件的电机和机械连接通常应被视为环境的一部分,而不是部件的一部分,同样,如果我们将MDP框架应用于人或动物,则肌肉、骨骼和感觉器官应被视为环境的一部分,奖励也可能在自然和人工学习系统的物理身体内计算,但被认为是外部的代理。我们遵循的一般规则是,任何不能由代理随意改变的东西都被认为是外部环境的一部分,例如,代理经常知道它的奖励是如何作为其操作的函数和它们被接受的状态来计算的,但我们总是认为奖励计算是外部的,因为它定义了面向代理的任务,因此必须超出其任意更改的能力,事实上,在某些情况下,代理可能知道其环境如何工作,仍然面临困难的强化学习任务,正如我们可能确切地知道像厄尔诺·鲁比克的魔方这样的拼图如何工作,但仍然无法解决它,代理-环境边界代表代理的绝对控制的限制,而不是其知识的限制。
MDP框架是一个相当抽象的目标导向的学习交互问题,它提出了什么的感觉,记忆中的细节,和控制装置,不管目的是试图实现的,任何问题的学习目标导向行为可以归结为三个信号来回传递剂和其环境之间:一个信号来表示代理人的选择(行动),一个信号代表作出选择的基础(状态),和一个信号来定义代理人的目标(奖励),他的框架可能不足以有效地代表所有的决策学习问题,但它已被证明是广泛的有用和适用。
当然,每个任务的特定状态和行为都会有很大的差异,他们的表示会直接影响性能,在强化学习中,与其他类型的学习一样,这种表现选择目前比艺术更具艺术性,在这本书中,我们提供了一些关于表达状态和行为的好方法的建议和例子,但是我们的主要焦点是一旦选择了表达方式,学习如何表现的一般原则。
例子3.1 生物感应器 假设正在应用强化学习来确定生物反应器(用于生产有用化学物质的大量营养物和细菌)的瞬时温度和搅拌速度,这样的应用中的动作可能是目标温度和目标搅拌速度,这些速度被传递到较低级别的控制系统,然后直接激活加热元件和马达以达到目标,这些状态可能是热电偶和其他感官读数,可能是过滤和延迟,再加上象征性的输入和目标化学品,奖励可能是对生物反应器产生有用化学物质的速度的瞬间测量,注意在这里每个状态是传感器读数和符号输入的列表或向量,每个行为是由目标温度和搅拌速度,这就是典型结构化表示的状态和行为的强化学习任务。另一方面,奖励总是单一的数字。
例子3.2 拾放机器人 考虑使用强化学习来控制机器人手臂在重复性拾放任务中的运动,如果我们想要学习快速平滑的动作,学习代理将不得不直接控制电机,并且获得关于机械联动的当前位置和速度的低延迟信息,在这种情况下的动作可能是施加到每个关节处的每个电动机的电压,并且这些状态可能是关节角度和速度的最新读数,对于成功拾取和放置的每个对象,奖励可能是+1,为了鼓励平稳的运动,在每个时间步骤上,可以给出一个小的负面奖励,作为运动的瞬间“急动”的函数。
课后习题3.3 考虑驾驶的问题, 您可以根据加速器,方向盘和制动器来定义动作,即身体与机器相遇的位置,或者你可以把它们定义得更远 - 比如橡胶在路面上的位置,考虑到你的行为是轮胎扭矩,线路的哪一个位置是优先于另一个位置的?偏好一个地点比另一个地点更重要,还是自由选择?
3.2 目标和奖励
目标既是agent的目标,代理器完成目标就会获得奖励,奖励reward这个东西,前面已经讲了很多了,这里就略过。
3.3 返回和情节(Returns and Episodes)
到目前为止,我们已经非正式讨论了学习的目的,我们已经说过,代理人的目标是最大限度地获得长期的累积奖励,这要如何正式定义?如果每一步的奖励累加,Rt+1 , Rt+2 , Rt+3 , . . .那么我们希望最大化精确这个序列的哪个方面,通常来说,我们力求最大化预期回报,用Gt表示回报,回报既是奖励之和:

T是最后一步,当agent-environment交互自然地分解成子序列时,我们称之为Episodes,就好象在玩迷宫游戏时候,通过迷宫或者任何形式的重复交互。我作个比喻,就好像下象棋,Episode就好像一局对决,一旦一方被将军那么这局Episode结束,然后环境会重置,到下一个Episode,就好象下棋,一局结束后,重新摆好棋子继续,上一局游戏和这一局游戏是相互独立的。因此,这些事件都可以被认为是以相同的终端状态结束,对不同的结果有不同的回报,这种情节的任务被称为情节任务(episodic tasks)。
另一种情况,有时候,我们会遇到没有终结的任务,比如无人驾驶就没有任务限制,车一直开,它就一直学,没有说到什么一个地方又重置什么的,这类任务叫连续任务(continuing tasks),当应用continuing tasks的时候,式子3.7就不能运用了,因为continuing tasks是没有时间限制的,所以它的T是无限大的,那永远无法获取Gt,在本书中,我们通常使用概念上稍微复杂一点但在数学上更简单的返回定义。
现在,我们添加一个概念:折扣(discounting),根据这种方法,代理人试图选择行动,以便在未来收到的折扣奖励的总和最大化,折扣回报函数:
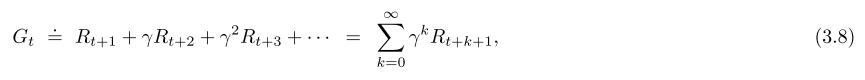
γ是折扣率,区间为[0,1],折扣率决定了未来奖励的现值,如果现在获取一个未来第K步的奖励(是获取将来的奖励),那么折扣率就为γ的K+1次方,如果γ小于1,那么式子3.8就会收敛到有限个,如果γ等于0,代理器只会看到最近的reward,在这种情况下,它的目标是学习如何选择At,以使Rt+1最大化,如果每个代理人的行为都只影响直接的奖励,那么代理人可以通过分别最大化每个直接奖励来最大化式子(3.8),但总的来说,为了最大限度地获得即时奖励,可以减少获得未来奖励的机会,从而减少回报,当γ为1,回报目标更强烈地考虑到未来的回报,代理器变得更有远见。
课后练习3.5 平衡杠,这个任务的目的是对沿着轨道移动的推车施力,以保持铰接在推车上的杆不会掉落。如果杆从垂直方向跌落超过给定角度,或者手推车跑离轨道,则失败,每次失败后,电杆都会重置为垂直位置,这个任务可以被视为偶发事件,其中自然事件是反复尝试平衡极点,每一步都会获得奖励,直到杆跌下该Episode结束,在这种情况下,永久的成功平衡意味着无限的回报,或者,我们可以使用贴现来将极点平衡视为一项持续的任务。在这种情况下,每次失败的奖励为-1,其他时间为零,在任何一种情况下
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 6352
6352











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









