









随机梯度下降是很常用的算法,他不仅被用在线性回归上,实际上被应用于机器学习领域中的众多领域。
本节我们可以用这种算法来将代价函数最小化

我们想要使用梯度下降算法得到 θ0和θ1来使代价函数J(θ0 , θ1)最小化,当然也适用于其他跟一般的函数比如J(θ0,….θn)。
下面是关于梯度下降的构想:
- 预估两个初始值θ0和θ1作为起点
- 不断改变θ0和θ1使代价函数 J(θ0 , θ1)减小直到最小为止
直观解释
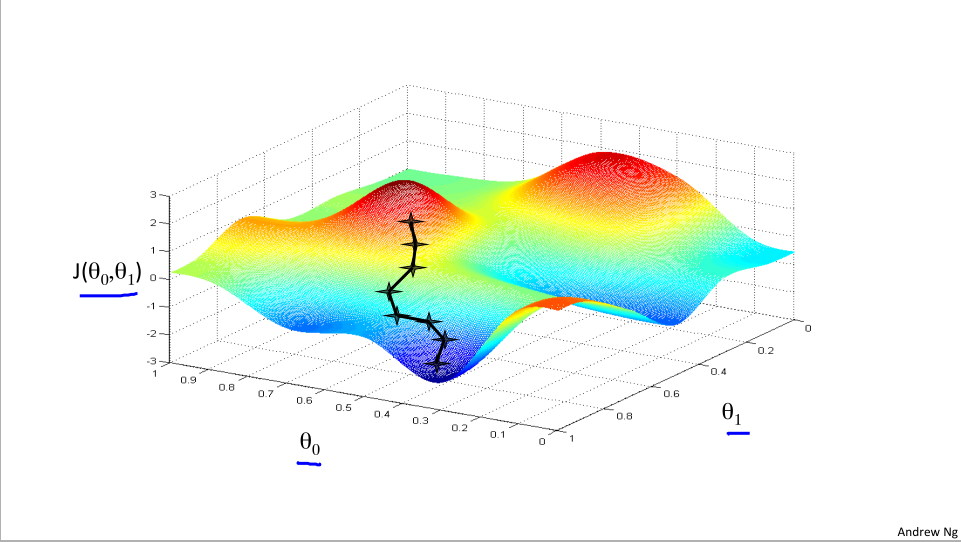
我们试图让代价函数最小,注意θ0和θ1在水平轴上,而图形表面高度代表了J的值
我们把图形想象成山,我们现在在半山腰某个位置,想要尽快的小碎步下山,所以环顾四周,寻找下山最好的道路,一步一回头,不断找好路走,最后下降到一个很低的地方。
但是如果我们处在半山腰另一个地方呢?
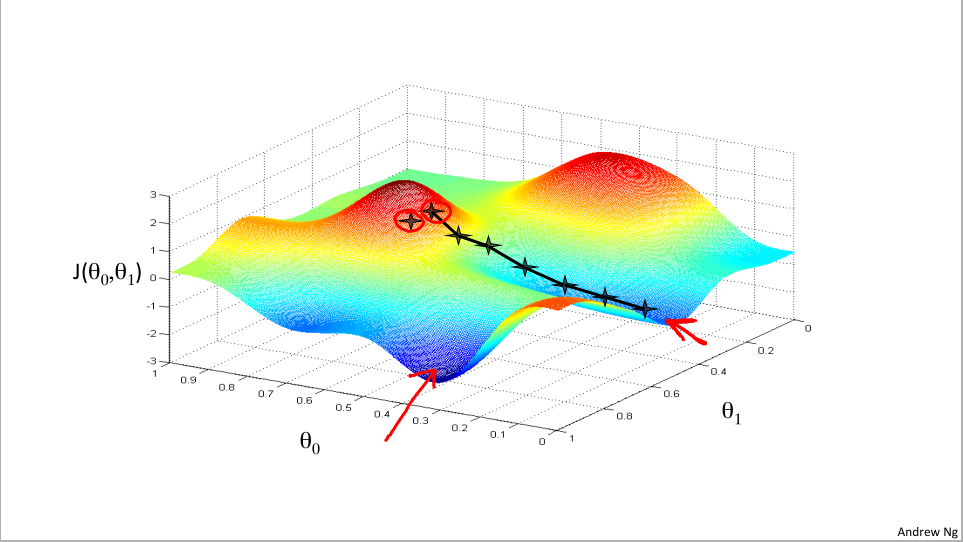
我们可能就会寻找到另一条下山路径,到达另一个低点。
所以我们初始位置的不同,就有可能的带不同的局部最优解。
数学定义
梯度下降算法就是重复计算直到收敛
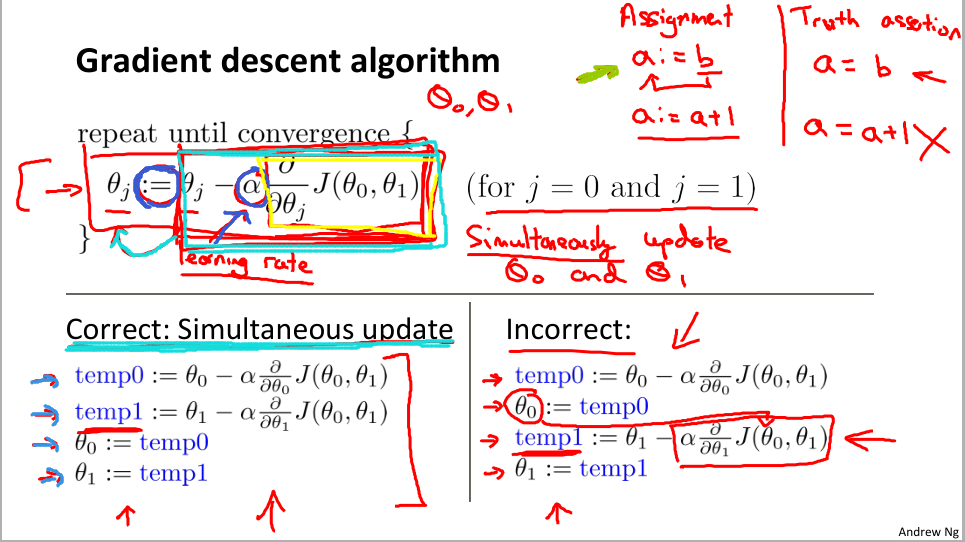
图中的 := 代表赋值符号,而且需要注意的是每次更新都是同时赋值。
alpha 代表的是学习速率,它控制我们以多大的的幅度更新这个参数代表θj。也就是上面说的大步流星下山或是小碎步下山。
直观解释
下面解释alpha 和它后面的微分式的意义,以及为什么梯度下降算法会在这个函数上起作用。

为了方便解释,我们还是只取一个属于实数的θ值。下面我们解释这个关于代价函数J(θ0 , θ1)的微分式
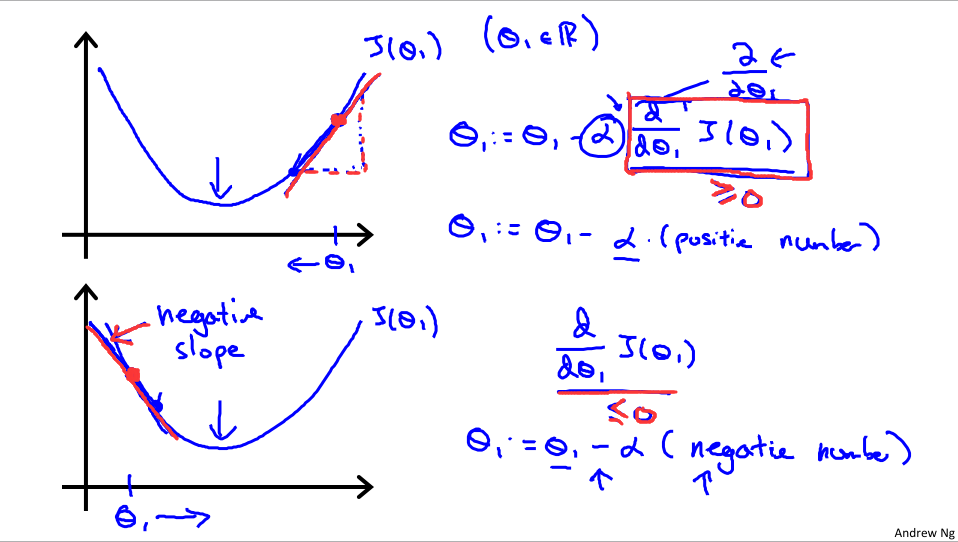
- 可以看到,对代价函数这条弓形线求导实际上就是求曲线的斜率,当θ1在最低点右边时,斜率为正,那么 θ1 := θ1 - alpha(正值) 就会减小,θ1在x轴上往左移动。
- 同理,如果初始θ1在左边,斜率为负,θ1变大,往右移动。直到找到最优的点
步长大小
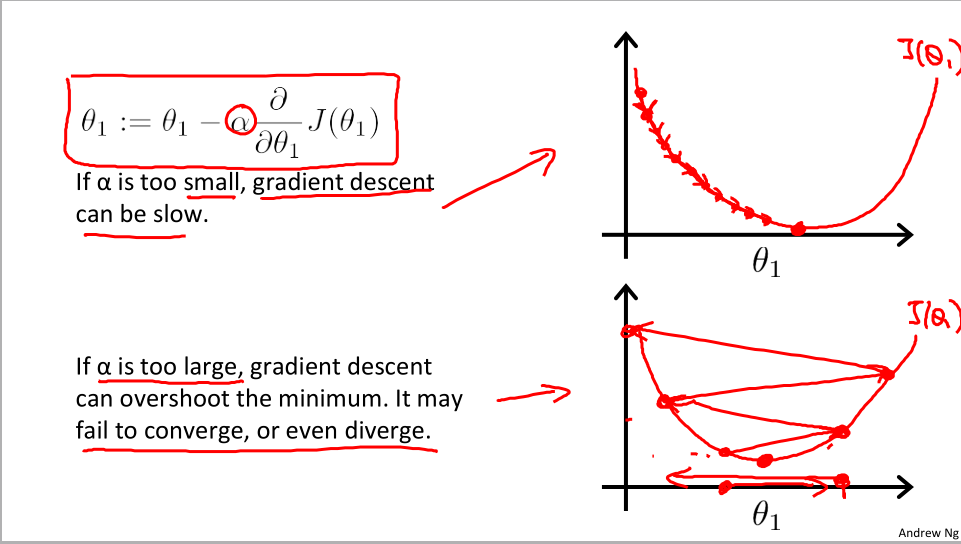
容易想到如果学习速率alpha过大或过小,就会导致步子过大或过小,导致学习进度很慢,或者直接跳过最低点导致无法收敛。
越来越慢
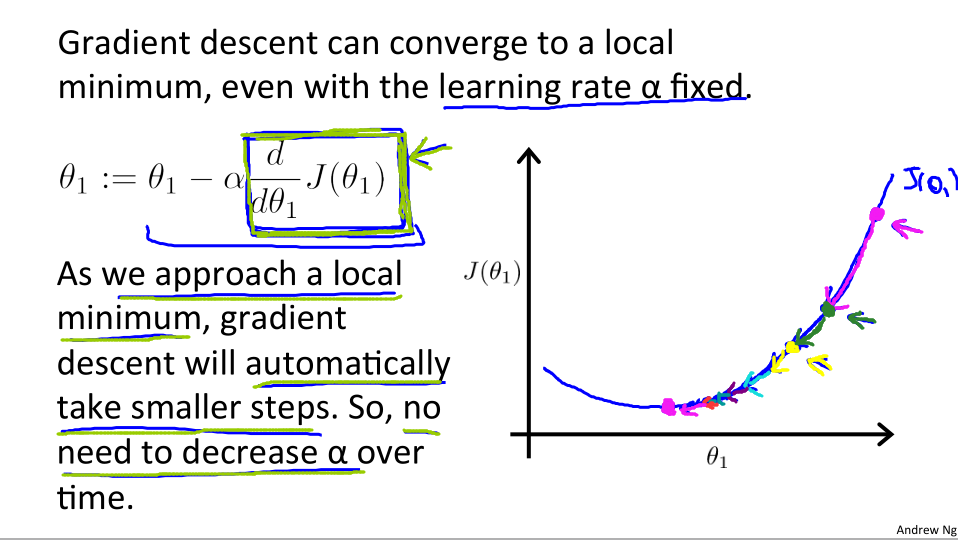
- 当然,如果我们一开始就选中了最低点,那么我们的算法就会停留原地不做改变。
- 在梯度下降算法更新的过程中,越接近局部最低时,导数值会自动变的越来越小,步子也会慢慢减小,所以没有必要另外去减小α















 502
502

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









