









本节将梯度下降与代价函数结合,并拟合到线性回归的函数中

这是我们上两节课得到的函数,包括:
- 梯度下降的公式
- 用于拟合的线性假设和h(x)
- 平方误差代价函数 J(θ0 , θ1)
步骤
我们把J(θ0 , θ1)带入到左边的梯度下降公式中,展开成下面形式
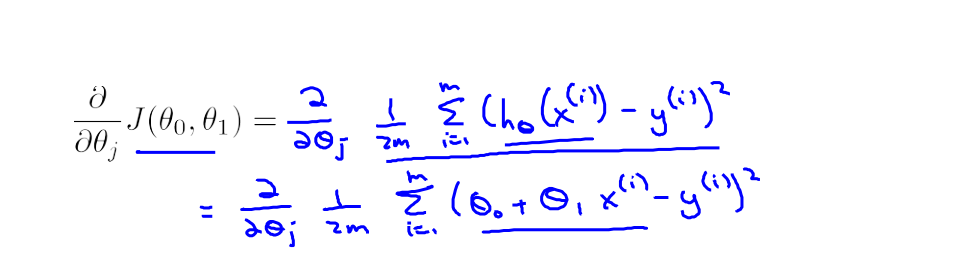
我们假设梯度下降算法起始地两个初值J = 0 , 1 。分别对θ0 和θ1求偏导
- 带入到我们的梯度下降公式中得到:
- 然后我们不断执行算法,θ0 和 θ1 不断被更新,直到收敛。
这就是我们的线性回归算法。
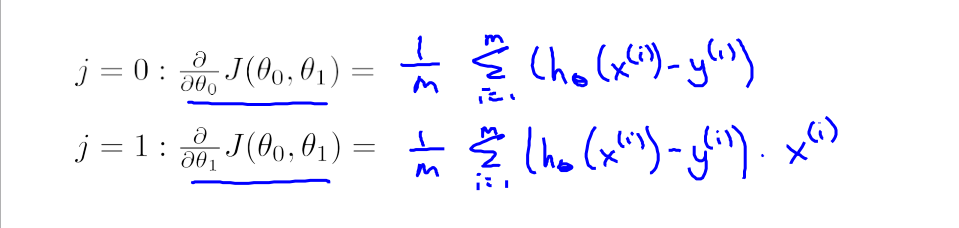

梯度下降算法是如何工作的?
我们上节课展示的梯度下降算法是这样的
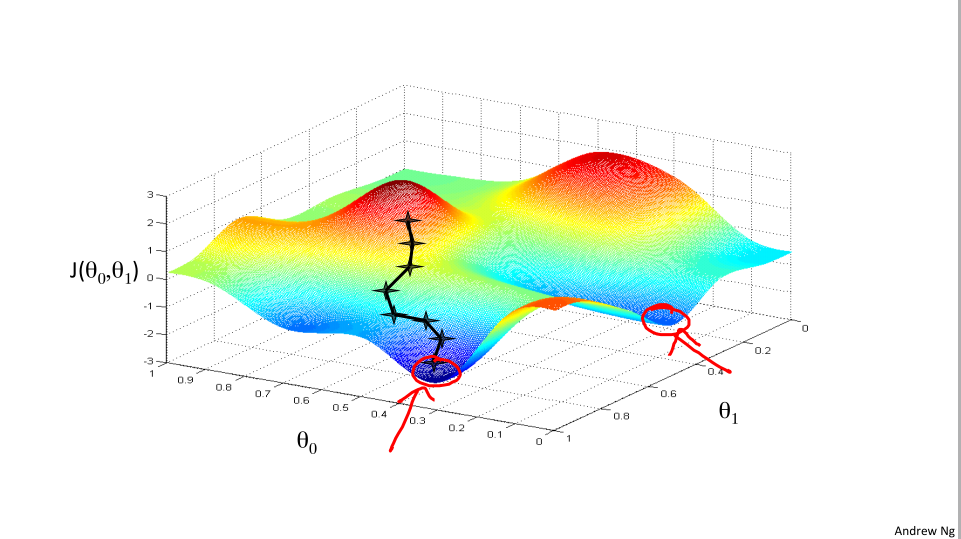
不同的点可能走到不同的局部最优点
但是事实证明用于线性回归的代价函数总是一个凸函数的形式
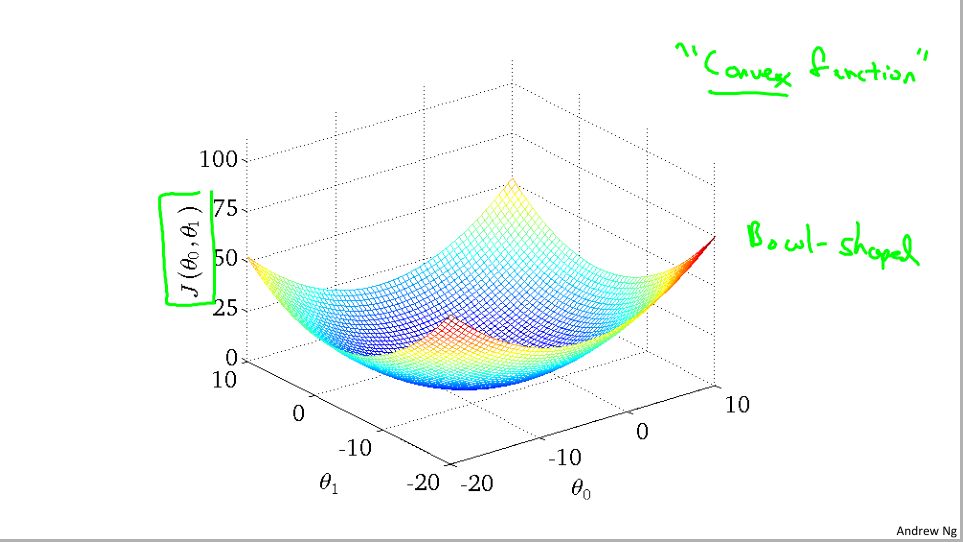
在线性回归中,无论如何我们只能找到一个全局最优解
下面我们通过轮廓图展示下降过程:
轮廓图展示:
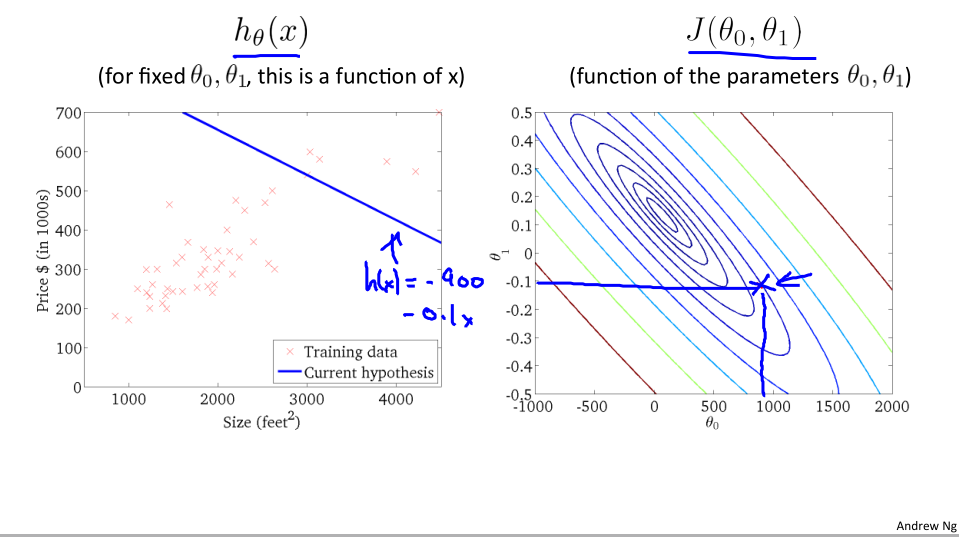
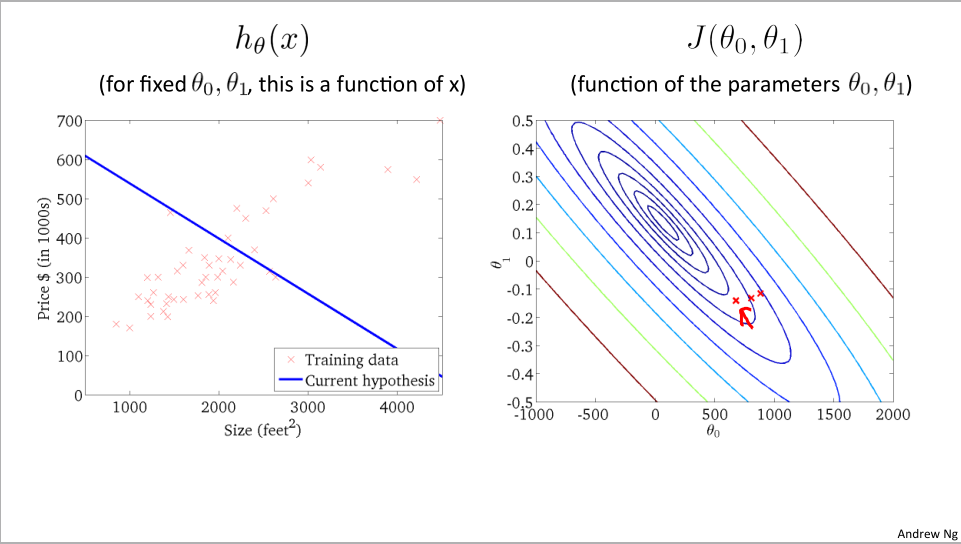
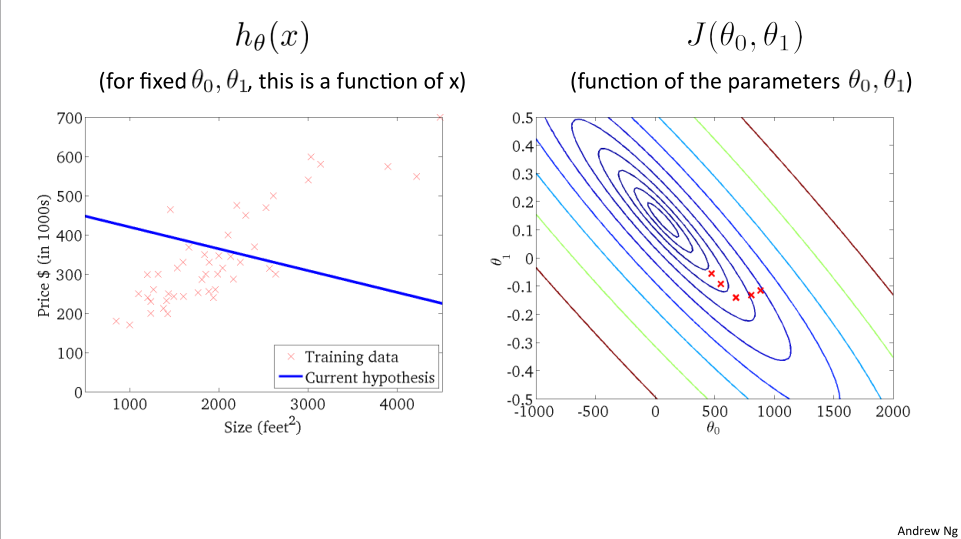
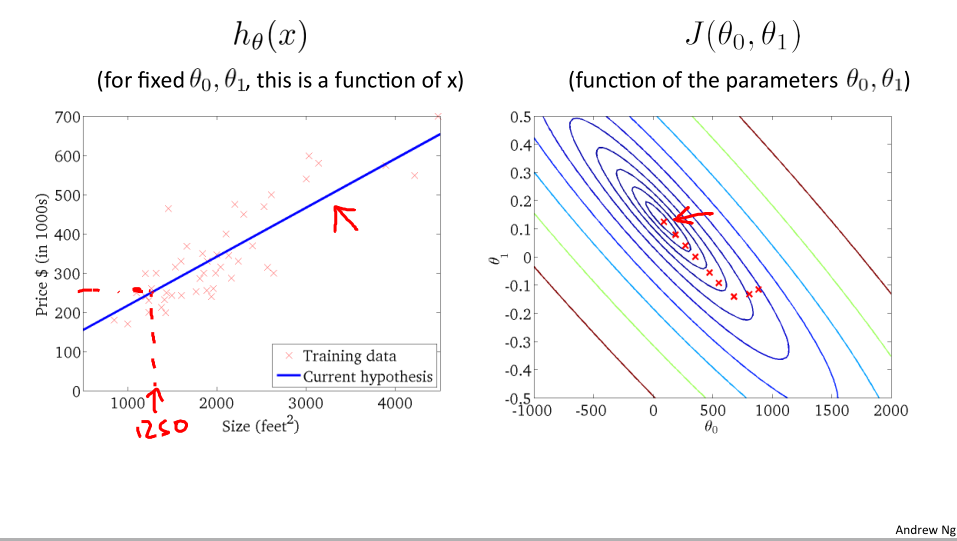
图左边对应着相应的假设函数,最终我们找到了数据最好的拟合结果,现在就可用利用这条直线来预测结果。
批量梯度下降法:

刚才这种梯度下降法同样也可以称为批量梯度下降法,因为在刚才的下降过程中,我们每一步都计算了对训练集中所有的样本就行了求和运算。
- 当然也有些梯度下降算法在每次计算式只关注数据集中小部分。将在后面课程介绍。















 502
502

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









