






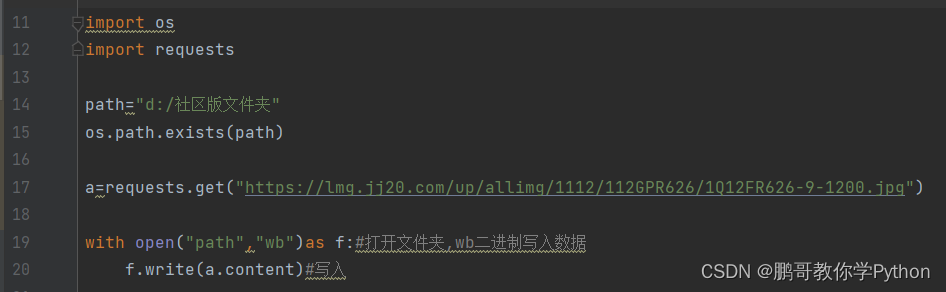
爬取网站图片也避免不了用到库,这次我们用到的库是requests,win+R输入cmd回车,
pip install requests
下载完成为绿色,于是我们导入模块
import requests
a=requests.get("https://lmg.jj20.com/up/allimg/1112/112GPR626/1Q12FR626-9-1200.jpg")
#(https://lmg......这一串为图片的url,右击图片获取)
接着,我们写代码来打开文件夹,文件夹要提前创建,当然也可以加个创建文件夹的代码来创建,,其中的wb为二进制写入数据
with open("D://111//2.jpg","wb")as f:
f.write(a.content)#写入
接下来就是自动创建文件夹,并且保存图片啦。。。废话不多说,看图
这是一项最基础的爬取图片教程,关注我,带你学更多















 2673
2673











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









