







简述
最近接触了字符分割与识别这一方面内容,奈何没有相关知识,在了解到了Halcon这一算法库后果断采用了它,因为它在字符处理这方面还是相当优秀的。
使用
Halcon这个算法库的使用是的先把图上要识别的文字区域计算出来,然后根据统计好的区域数(分割好的字符区域)输入相对应的字符,接着调用Halcon函数把图上相对应的区域与输入字符写成一个occ文件,最后再根据这个occ文件训练出一个omc文件,这个omc文件就是我们识别时候使用的文件。
效果
翻译功能需要把翻译文件拷贝到执行文件目录,训练时如果不选择字库默认会在“./”层生成默认occ、omc文件,识别时使用的是生成的omc文件。
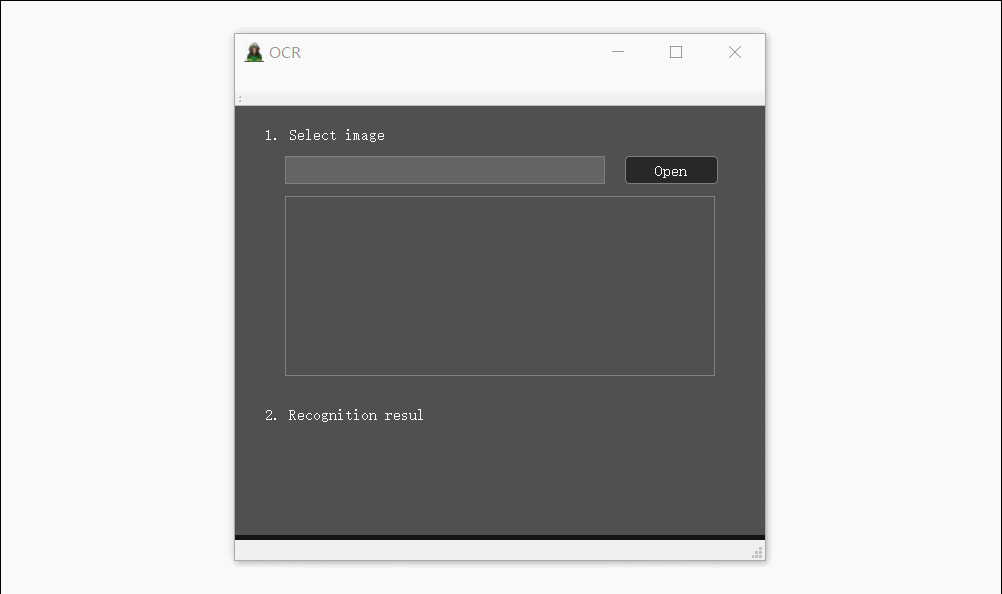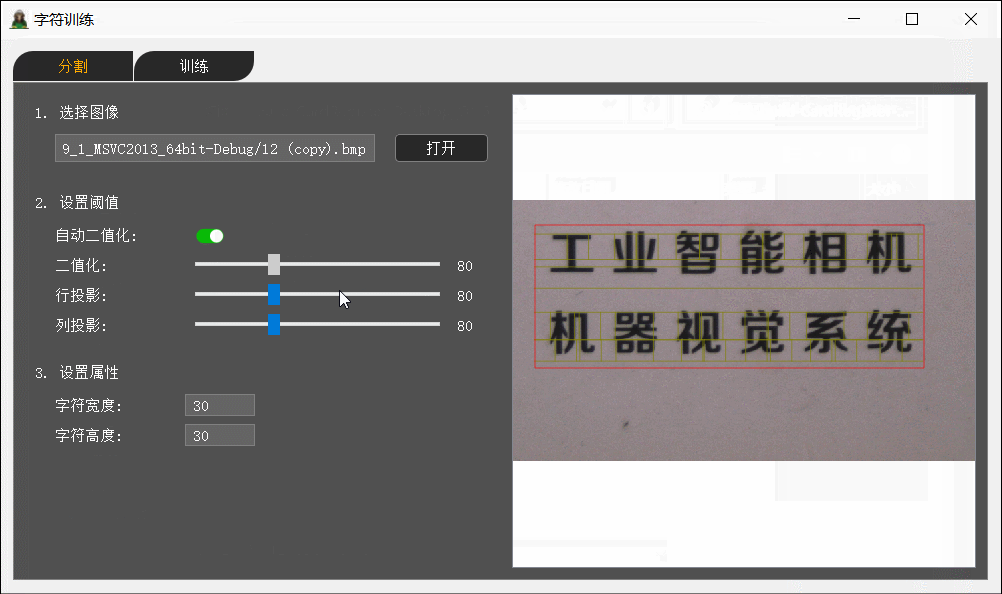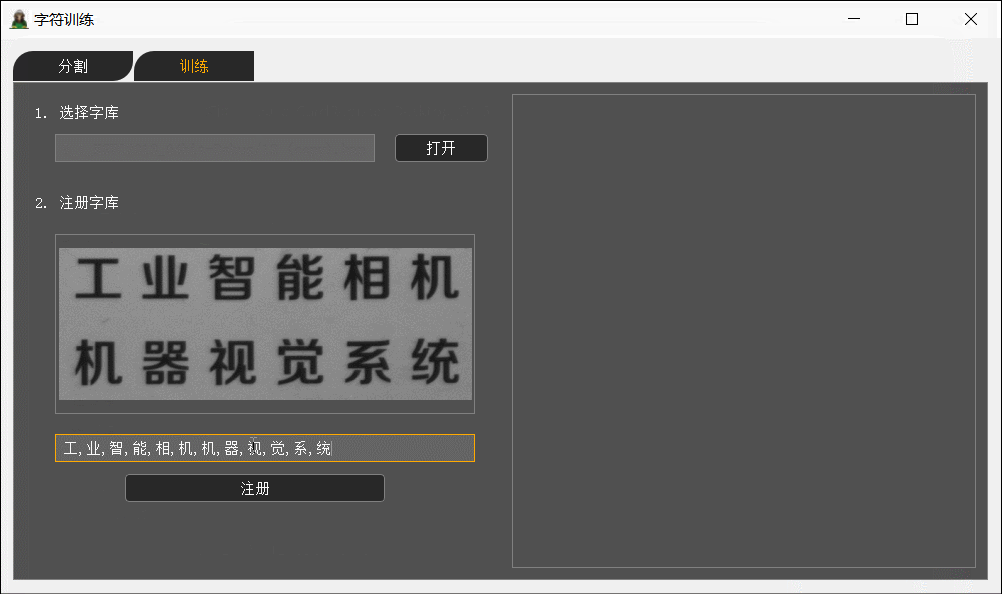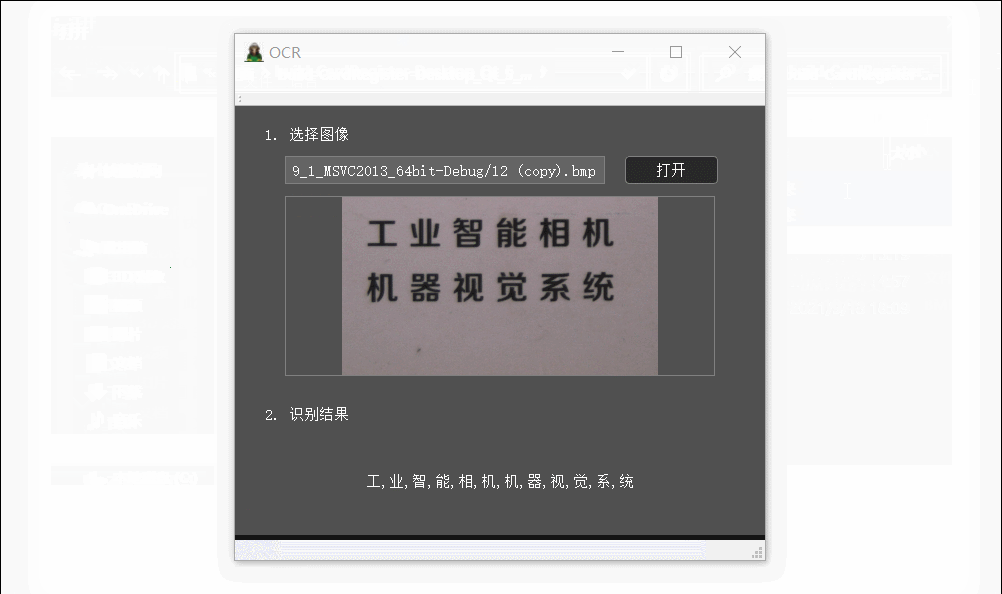
二值化功能默认为自动,关闭自动模式后可以手动拖动滑块设置二值化阈值。
分割
分割分为横向分割与纵向分割,首先根据传进来的一通道图做横向直方图统计(横向均值),统计出来的数量就是图的高度,因为统计的每一行的均值最大为255,所以使用255-value就可以得到黑色像素值跟随滑块一样变大变小。起始行的均值要大于等于横向投影的数值,因为有个字符高度所以当遇到起始行后可以直接加上字符高度直接省略了中间统计的数值提高效率;结束行的判断为均值小于横向投影的数值,因为一般都是有行间距的。
纵向投影不能用整图做,而是先取到每一行的区域然后统计一行的直方图,否则会影响统计结果,其他的基本跟横向分割类似。纵向投影也使用Halcon自带统计函数而不使用自己写的是因为Halcon的GrayProjections()比自己统计的还快,就算是它两个方向都统计。
注意:GrayProjections()的参数要给“simple”,如果给“rectangle”而图像又为正矩形时则横向纵向统计值相反。
SplitResult T20000::splitim(const HImage &image, const SplitInfo &info)
{
SplitResult result;
try
{
// 统计横向直方图
int w = image.Width();
HRegion region = image.GetDomain();
HTuple hRowPro = image.GrayProjections(region, "simple", NULL);
QList<QLineF> listH;
int proCount = hRowPro.Length();
for (int i = 0; i < proCount; i++)
{
// 一行像素的均值
float avg = 255 - hRowPro[i].D();
// 一行的开始
if (listH.count() % 2 == 0)
{
if (avg >= info.iProRow)
{
int y = qMax(0, i - 1);
listH << QLineF(0, y, w, y);
i += info.iHeight;
}
}
// 一行的结束
else
{
if (avg < info.iProRow)
{
int y = i;
listH << QLineF(0, y, w, y);
}
}
}
// 要求为偶数
if (listH.count() % 2 != 0)
listH.removeLast();
result.list.append(listH);
// 按行统计竖向直方图
int rowCount = listH.count() / 2;
for (int i = 0; i < rowCount; i++)
{
int c1 = 0, c2 = 0;
int r1 = listH[i * 2].y1();
int r2 = listH[i * 2 + 1].y1();
HTuple hColPro;
HRegion region = HRegion(r1, 0, r2, w);
image.GrayProjections(region, "simple", &hColPro);
QList<QLineF> listV;
int proCount = hColPro.Length();
for (int j = 0; j < proCount; j++)
{
// 一列像素的均值
float avg = 255 - hColPro[j].D();
// 一列的开始
if (listV.count() % 2 == 0)
{
if (avg >= info.iProCol)
{
c1 = qMax(0, j - 1);
listV << QLineF(c1, r1, c1, r2);
j += info.iWidth;
}
}
// 一列的结束
else
{
if (avg < info.iProCol)
{
c2 = j;
listV << QLineF(c2, r1, c2, r2);
// 开始计算每个字符的区域
if (result.regions.IsInitialized())
result.regions = result.regions.ConcatObj(HRegion(r1, c1, r2, c2));
else
result.regions = HRegion(r1, c1, r2, c2);
}
}
}
// 要求为偶数
if (listV.count() % 2 != 0)
listV.removeLast();
result.list.append(listV);
}
}
catch(HException &except)
{
qDebug() << except.ErrorMessage();
}
return result;
}训练
字符训练首先是根据分割出来的区域数量,然后输入相对应的字符,我这里根据“,”区分每一个区域的字符(一个区域可以对应多个字符)。因为Halcon的HRegion、HTuple也类似链表的功能,所以可以先把分割好的文字连接到HTuple,然后一次性写入。最后根据写入的文件occ训练成omc识别文件。(occ,omc都是自己命名的没有什么规定)
void CharTrainingDlg::on_pbRegister_clicked()
{
QStringList list = ui->leResultChar->text().split(",");
if (list.count() <= 0) return;
HImage imagex = m_pItem->regionim();
HRegion regions = m_pItem->regions();
int count = regions.CountObj();
if (count <= 0 || !imagex.IsInitialized()) return;
QString filePath = ui->leFontPath->text();
if (filePath.isEmpty()) filePath = "./card.occ";
try
{
// 写入OCC文件
HTuple textx;
for (int i = 0; i < count; i++)
{
textx = textx.TupleConcat(list.at(i).toUtf8().constData());
}
HTuple filePathx = filePath.toUtf8().constData();
if (QFile::exists(filePath))
regions.AppendOcrTrainf(imagex, textx, filePathx);
else
regions.WriteOcrTrainf(imagex, textx, filePathx);
// 插入表格
for (int i = 0; i < count; i++)
{
long r1, r2, c1, c2;
HRegion region = regions.SelectObj(i + 1);
region.SmallestRectangle1(&r1, &c1, &r2, &c2);
HImage image = imagex.CropRectangle1(r1, c1, r2, c2);
insertItem(list.at(i), HImage2QImage(image));
}
// 训练
HTuple hTrainfNames = HMisc::ReadOcrTrainfNames(filePathx, NULL);
HOCRMlp hMlp(8, 10, "constant", "default", hTrainfNames, 80, "none", 10, 42);
hMlp.TrainfOcrClassMlp(filePathx, 200, 1, 0.01, NULL);
// 写入OMC文件
QFileInfo info(filePath);
filePath = QString("%1/%2.omc").arg(info.path()).arg(info.baseName());
hMlp.WriteOcrClassMlp(filePath.toUtf8().constData());
}
catch(HException &except)
{
qDebug() << except.ErrorMessage();
}
}识别
识别的时候因为之前训练时配置一些属性(投影、宽度、高度),所以现在识别的时候也是根据之前保存的配置来分割字符区域。这里是根据拿去分割的图像与之前训练好的文件做识别处理,识别结果就是存放在HTuple这个容器中。
void MainWnd::on_pbOpenImage_clicked()
{
QString filter = "*.jpg | *.bmp | *.png";
QString filePath = QFileDialog::getOpenFileName(this, tr("Open"), "", filter);
if (filePath.isEmpty()) return;
ui->leImagePath->setText(filePath);
QImage image(filePath);
QSizeF size = ui->lDetectImage->size();
//
T20000 item;
item.setImage(image);
item.setRect(QRect(0, 0, image.width(), image.height()));
HImage imagex = item.regionim();
HRegion regions = item.regions();
// 训练
HTuple hConfidence;
HOCRMlp hMlp("./card.omc");
HTuple textx = hMlp.DoOcrMultiClassMlp(regions, imagex, &hConfidence);
QString text;
for (int i = 0; i < textx.Length(); i++)
{
text += textx[i].S() += ",";
}
ui->lDetectResult->setText(text);
// 如果超出规定区域后,按比例小的缩放
if (image.width() > size.width() || image.height() > size.height())
{
float ratio = qMin(size.width() / image.width(), size.height() / image.height());
image = image.scaled(image.size() * ratio - QSize(2, 2), Qt::KeepAspectRatio, Qt::SmoothTransformation);
}
ui->lDetectImage->setPixmap(QPixmap::fromImage(image));
}例子只是测试了环境比较好点的图片,如果是复杂的图片还是会有问题,这里的分割算法还待优化。
















 2085
2085











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











