










目录
配置Hadoop的core-site.xml和hdfs-site.xml
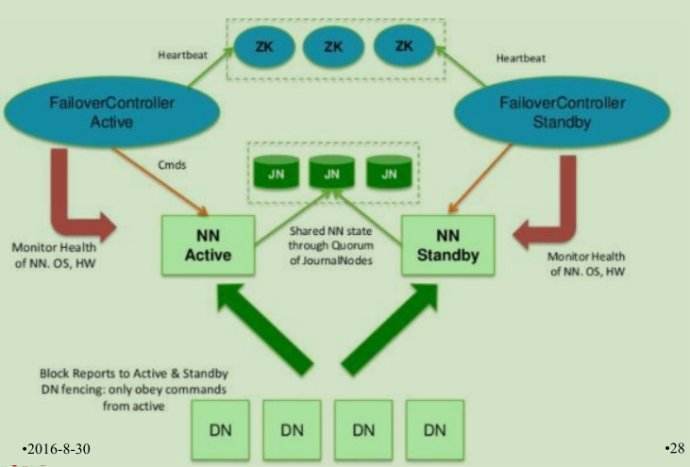
-
角色定义
| 服务器 | NameNode | NameNode | JournalNode | DataNode | ZKFC | ZOOKEEPER |
|---|---|---|---|---|---|---|
| node01 | * | * | * | |||
| node02 | * | * | * | * | * | |
| node03 | * | * | * | |||
| node04 | * | * |
-
停止之前的集群
$ stop-dfs.sh-
对node01,node02机器进行免密
# node02:
$ cd ~/.ssh
$ ssh-keygen -t dsa -P '' -f ./id_dsa
$ cat id_dsa.pub >> authorized_keys
$ scp ./id_dsa/pub node01:`pwd`/node02.pub
# node01:
$ cd ~/.ssh
$ cat node02.pub >> authorized_keys
-
zookeeper集群搭建
# zookeeper是用Java语言开发,需要先安装JDK,部署在node02-04机器
# 1.下载zookeeper安装包并上传到node02 然后解压
$ tar xf zookeeper-3.6.1.tar.gz
# 2.移动解压包到大数据安装目录
$ mv zookeeper-3.6.1 /opt/bigdata
# 3.切换到zookeeper的conf目录
$ cd /opt/bigdata/zookeeper-3.6.1/conf
# 4.复制zoo-sample.cfg并重命名为zoo.cfg
$ cp zoo-sample.cfg zoo.cfg
# 5.修改zoo.cfg
$ vi zoo.cfg
# 修改: datadir = /var/bigdata/hadoop/zk
# 添加: server.1=node02:2888:3888
# 添加: server.2=node03:2888:3888
# 添加: server.3=node04:2888:3888
# server.n ==>> n 代表权重,
# 6.创建目录
$ mkdir /var/bigdata/hadoop/zk
# 7.新建myid文件并写入权重值
$ echo 1 > /var/bigdata/hadoop/zk/myid
# 8.修改配置文件
$ vi /etc/profile
$ export ZOOKEEPER_HOME=/opt/bigdata/zookeeper-3.6.1
$ export PATH=$ZOOKEEPER_HOME/bin:$PATH
$ . /etc/profile
# 9.将配置好的zookeeper分发给node03 node04
$ cd /opt/bigdata
$ scp -r ./zookeeper-3.6.1 node03:`pwd`
$ scp -r ./zookeeper-3.6.1 node04:`pwd`
# 10.修改node03 04 的zookeeper设置,同步骤6,7, 8 (myid值设置对应的值)
# 11.启动node02-node04的zookeeper
$ zkServer.sh start
-
配置Hadoop的core-site.xml和hdfs-site.xml
core-site.xml
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://mycluster</value>
</property>
<property>
<name>ha.zookeeper.quorum</name>
<value>node02:2181,node03:2181,node04:2181</value>
</property>
</configuration>
hdfs-site.xml
<configuration>
<!--namenode个数 -->
<property>
<name>dfs.replication</name>
<value>2</value>
</property>
<!-- namenode和DataNode文件存放路径 -->
<property>
<name>dfs.namenode.name.dir</name>
<value>/var/bigdata/hadoop/ha/dfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>/var/bigdata/hadoop/ha/dfs/data</value>
</property><!-- 配置namenodes一对多, 逻辑到物理节点的映射-->
<property>
<name>dfs.nameservices</name>
<value>mycluster</value>
</property>
<property>
<name>dfs.ha.namenodes.mycluster</name>
<value>nn1,nn2</value>
</property>
<property>
<name>dfs.namenode.rpc-address.mycluster.nn1</name>
<value>node01:8020</value>
</property>
<property>
<name>dfs.namenode.rpc-address.mycluster.nn2</name>
<value>node02:8020</value>
</property>
<property>
<name>dfs.namenode.http-address.mycluster.nn1</name>
<value>node01:50070</value>
</property>
<property>
<name>dfs.namenode.http-address.mycluster.nn2</name>
<value>node02:50070</value>
</property><!-- 配置journalnode -->
<property>
<name>dfs.namenode.shared.edits.dir</name>
<value>qjournal://node01:8485;node02:8485;node03:8485/mycluster</value>
</property>
<property>
<name>dfs.journalnode.edits.dir</name>
<value>/var/bigdata/hadoop/ha/dfs/jn</value>
</property><!--配置namenode切换的实现类以及发送消息的调用方式 -->
<property>
<name>dfs.client.failover.proxy.provider.mycluster</name>
<value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value>
</property>
<property>
<name>dfs.ha.fencing.methods</name>
<value>sshfence</value>
</property>
<!--配置ssh免密,满足zkfc和namenode免密 -->
<property>
<name>dfs.ha.fencing.ssh.private-key-files</name>
<value>/root/.ssh/id_dsa</value>
</property>
<!--开启HA -->
<property>
<name>dfs.ha.automatic-failover.enabled</name>
<value>true</value>
</property></configuration>
-
分发配置
$ scp core-site.xml hdfs-site.xml node02:`pwd`
$ scp core-site.xml hdfs-site.xml node03:`pwd`
$ scp core-site.xml hdfs-site.xml node04:`pwd`
-
初始化和启动
# 1.分别在node01~03启动journalNode
$ hadoop-daemon.sh start journalnode
# 2.在node01,node02任一台机器进行namenode初始化
$ hdfs namenode -format
# 3.启动这个namenode,以备另一个namenode同步
$ hadoop-deamon.sh start namenode
# 4. 在另一台机器进行namenode同步
$ hdfs namenode -bootstrapStandby
# 5.格式化zookeeper
$ hdfs zkfc -formatZK
# 6.启动集群
$ start-dfs.sh















 370
370











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









