







论文阅读笔记(五)——FD-MOBILENET
前言
刚看完一篇,昨晚晚上八点多睡了,半夜两三起来肝论文,hhhh

1 论文简介
1.1 关于文章
论文名称:FD-MOBILENET: IMPROVED MOBILENET WITH A FAST DOWNSAMPLING STRATEGY
1.2 关于模型
又是一个mobilenet的变体~
2 文章正文
2.1 摘要
我们提出了快速下采样MobileNet(FD-MobileNet),这是一种高效且准确的网络,适用于非常有限的计算预算(例如10-140 MFLOP)。 我们的主要思想是将快速下采样策略应用于MobileNet框架。 在FD-MobileNet中,我们在12层内执行32倍下采样,仅为原始MobileNet的一半。 该设计带来三个优点:(i)显着降低了计算成本。 (ii)它增加了信息容量并实现了显着的性能改进。 (iii)它是工程友好的,并且提供了快速的实际推断速度。 在ILSVRC 2012和PASCAL VOC 2007数据集上进行的实验表明,在不同的计算预算下,FD-MobileNet始终优于MobileNet并与ShuffleNet取得可比的结果,例如,在ILSVRC 2012 top-1准确性上,MobileNet分别超过5.5%,在VOC上超过3.6%。 在12个MFLOP的复杂性下的2007年mAP。 在基于ARM的设备上,在相同的复杂度下,FD-MobileNet在MobileNet上的推理速度提高了1.11倍,在ShuffleNet上实现了1.82倍的推理速度。
2.2 Motivation&Contributions
PS: 这一段主要是方便我们以后写Introduction与Related Work
2.2.1 Motivation
随着深度学习技术的发展,CNN 在 i图像分类 / 语义分割 / 目标检测 等视觉任务中已大显身手,然而 CNN 模型往往需要巨大的计算资源和巨大的模型尺寸,这严重限制了其在移动或嵌入式上的应用因此,CNN 的压缩与加速吸引着深度学习社区的关注
作者从加速的角度出发, 提出 a Fast Down-sampling Strategy(30X down-sampling within the first 12 layers),避免 shrinking channels 的压缩方式带来精度的过度损失,同时达到压缩模型的作用
现有压缩与加速方法可以大致分为如下 4 类
- Tensor decomposition methods(low rank)Tensor分解方法
- 卷积层分解为几个较小的卷积层,从而降低了整体复杂度和参数数量。 此类方法通常涉及低秩估计过程和微调过程,从而导致训练过程缓慢
- Parameter quantization methods 参数量化方法
- 利用低精度参数,并提供显着的理论加速和巨大的内存节省。 但是,当前的硬件尚未针对低精度计算进行最佳优化,因此量化方法需要特定的硬件才能实现理想的加速
- Network pruning 网络修剪方法
- 早期的修剪方法采用非结构化修剪方案,并且会导致随机内存访问,而当前硬件对此却没有很好的支持。 关于网络修剪的最新研究主要集中在结构化修剪上,以利用现有硬件
- Compact networks 轻量化网络
- ShuffleNet(虽然降低了参数量,实际在移动端跑起来会很慢)
- MobileNet(相比 shuffleNet,在移动端更快,但是由于 slow down sampling strategy 策略,当 当计算预算相对较小较小时,会导致严重的性能下降)
- squeezeNet(老年人)
2.2.2 Contributions
在本文中,文章提出了一种名为Fast-Downsampling MobileNet(FD-MobileNet)的高效,准确的网络,用于极其有限的计算资源(例如10至140个MFLOP)。
文章不仅通过缩小网络宽度来适应较小的计算预算,还通过在MobileNet框架中采用快速下采样策略来构成FD-MobileNet。 在提出的FD-MobileNet中,文章在前12层内执行32倍下采样,这仅是原始MobileNet数量的一半。 之后,应用一系列深度可分离卷积以获得更好的表示能力。
得益于快速下采样策略,FD-MobileNet具有以下三个优点:
i)由于特征图的空间尺寸较小,FD-MobileNet的计算成本得以降低。
ii)在相同的复杂性下,FD-MobileNet允许的通道数量比MobileNet对应的通道更多。这显着增加了FD-MobileNet的信息容量,这对于超小型网络的性能至关重要。
iii)FD-MobileNet继承了MobileNet的简单体系结构,并在工程实施中提供了快速的推理速度
进行了广泛的实验,以检验所提出的FD-MobileNet的有效性。 首先,文章将FD-MobileNet与ILSVRC 2012数据集上其他先进的紧凑型网络进行比较。 然后,文章检查FDMobileNet在PASCAL VOC 2007数据集上的泛化能力。 实验表明,所提出的FD-MobileNet明显优于MobileNet,并且在各种计算预算下均可与ShuffleNet媲美。 例如,在12个MFLOP的计算预算下,与MobileNet相比,FD-MobileNet的ILSVRC 2012 top-1准确性提高了5.5%,VOC 2007 mAP提升了3.6%。 最后,文章进一步评估了基于ARM的设备上FD-MobileNet的实际推理速度。 在12个MFLOP的复杂性下,FD-MobileNet在MobileNet上提供了1.11倍的加速,在ShuffleNet上提供了1.82倍的加速。
深度可分离卷积
这个玩意儿相信大家都很熟悉了,就不过多介绍了,就贴个图吧。如果不懂可以去看我前面笔记,或者去搜一下~

快速下采样策略
不同的下采样策略在轻量级网络的详细的特征表示和大型信息容量之间给出了折中。在慢速下采样策略,下采样在网络中的较后面的层中发挥作用,因而更多层具有大的空间维度。正相反,快速下采样策略中下采样在网络的开始便发挥作用,这很大程度上减少了计算代价。于是,给定一个固定的运算限制,慢速下采样策略倾向于产生更多的细节特征然而快速下采样策略可以提升通道数目且允许更多的信息编码。
当运算限制极其小的时候,信息容量就在网络的性能方面起着很重要的作用。按照惯例,减少通道数目来使轻量级网络架构适应某种复杂性。在采用慢速下采样的情况下,网络为了能够编码大量信息而变得狭窄,这导致了严重的性能下降。例如,在12 MFLOPs,原始MobileNet架构在全局池化之前的最后一层仅有128个通道,因而信息容量十分有限。
基于这种原因,作者提出在FD-MobileNet架构中采用快速下采样策略并且推迟特征提取过程到最小的分辨率。更快的下采样通过在网络开始处连续应用大步幅的深度可分离卷积来实现。在这里作者没有采用max pooling因为作者发现这并没有获得性能提升而引入额外的运算。提出的FD-MobileNet输入一个大小为224x224的图片,在最初的两层运行4倍下采样而在12层中运行32倍下采样,然而在原始的MobileNet中运行相同的下采样层数分别是4和24。更准确而言,这12层由1个标准卷积层、5个深度可分离卷积(每一个有1个深度卷积层和一个逐点卷积层)、一个深度卷积层组成。给出了在140 MFLOPs运算限制下使用快速下采样策略的FD-MobileNet、MobileNet和ShuffleNet之后的比较。从图中可以看出,在特征映射到
7
×
7
7\times 7
7×7之前FD-MobileNet比其他架构浅得多。

剩余层
快速下采样策略的使用显着降低了最小空间尺寸(7×7)之前各层的计算成本。 如图所示,在140个MFLOP的计算预算下,MobileNet在最大的4种分辨率上花费了约129个MFLOP,而FD-MobileNet仅花费了约59个MFLOP,因此,在建议的体系结构中可以利用更多的层和更多的通道。 在这里,文章利用6个深度可分离卷积来提高生成特征的表示能力。 前5个深度可分离卷积的输出通道是512,而最后一个是1024,这是MobileNet对应卷积(0.5×MobileNet-224)的两倍。 信道数量的增加有助于更大的信息容量,这对于在极其有限的计算资源下的网络性能至关重要。

网络结构
图展示了FD-MobileNet的总体体系结构。FD-MobileNet采用简单的堆栈体系结构,包含24层,包括1个标准卷积层,11个深度可分离卷积和1个完全连接层。
在之后,在每个卷积层之后应用batch normalization和ReLU激活。 为了方便地使FDMobileNet适应不同的计算预算,文章引入了[18]中称为宽度乘法器的超参数
α
α
α,以统一调整FD-MobileNet的宽度。文章使用简单的符号“
F
D
M
o
b
i
l
e
N
e
t
α
×
FDMobileNetα×
FDMobileNetα×”表示具有宽度乘数α的网络,图中的网络表示为“
F
D
−
M
o
b
i
l
e
N
e
t
1
×
FD-MobileNet 1×
FD−MobileNet1×”。
推理效率
当前的深度学习框架通过构建非循环计算图来完成神经网络的推理。 对于移动或嵌入式设备,内存和缓存资源是有限的。 结果,复杂的计算图可能引起频繁的内存/高速缓存切换,从而减慢了实际推理速度。 FD-MobileNet继承了原始MobileNet的简单体系结构,并且在计算图中只有一条信息路径。 这使得FD-MobileNet对工程实施非常友好,并在物理设备上高效。
实验 Experiments
ILSCRC 2012
数据集:
LSVRC 2012
ILSVRC 2012数据集由120万张训练图像和50,000张验证图像组成
训练:
PyTorch
四个GPU
90epochs
batchsize:256
momentum:0.9
学习率:从0.1开始,每30个epoch下降一个数量级。
使用了4e-5的权重衰减
数据增强,一种不太积极的多尺度增强方案( a slightly less aggressive multi-scale augmentation schem)而没有使用色彩抖动
评估时,报告验证集中的,the center-crop top-1top-1准确率
首先将每个验证图像的短边调整为256像素,然后使用中心224×224像素的裁切进行评估
结果
表展示了在三种计算预算下FD-MobileNet,MobileNet和ShuffleNet的top-1准确性的比较。 从表中可以看出,FD-MobileNet在不同的计算预算下比MobileNet有了实质性的改进。
可以看出,在140个MFLOP的复杂度下,FD-MobileNet比MobileNet差1.6%,在计算预算分别为40和12个MFLOP的情况下,性能分别提高了5.6%和5.5%。
值得注意的是,当计算预算非常小时(例如40和12 MFOP),FD-MobileNet大大优于MobileNet。 文章将这些改进归功于FD-MobileNet中快速下采样策略的有效性。
最初的MobileNet采用慢速下采样策略,因此,更多的图层具有相对较大的特征图,并且计算量更大。 因此,MobileNet相对较窄以保持计算效率,这限制了信息容量。
另一方面,FD-MobileNet采用了更快的下采样策略,从而可以利用更多的信道并减轻信息容量的下降。 例如,在12个MFLOP下,MobileNet的最后一层仅输出128个通道,而FD-MobileNet中的数量增加了一倍。 信息容量的增加大大提高了FD-MobileNet的性能。
与ShuffleNet相比,FD-MobileNet的结果可比或稍差。
文章推测,这些差异是由于ShuffleNet单元的旁路连接结构的有效性所致。 事实证明,旁路连接结构在各种计算机视觉任务中都很强大。 但是,在低功率移动或嵌入式设备上,旁路连接结构会引起频繁的内存/缓存切换,并损害实际的推理速度。相反,FD-MobileNet的简单体系结构有助于有效利用内存和缓存

VOC2007
数据集:
PASCAL VOC 2007
PASCAL VOC 2007数据集包含约10,000张图像,分为三组(train/val/test)。 在实验中,对探测器进行了VOC 2007训练集的训练,并报告了VOC 2007测试集的单模型结果。
训练:
Faster R-CNN
在三种计算预算(140、40和12 MFLOP)
600分辨率
15epochs
batch size 1
学习率从1e-3开始,每5个epoch除以10
权重衰减设置为4e-5
其他超参数设置遵循中原始的Faster R-CNN
表中显示了结果的比较。可以看出,在不同的计算预算下,FD-MobileNet比MobileNet有了显着改进。 在140个MFLOP的计算预算下,FD-MobileNet检测器在mAP上比MobileNet检测器高出1.6%。 当复杂度较低时,差距会扩大。 当复杂度限制为40个和12个MFLOP时,FD-MobileNet在mAP上的性能分别比MobileNet高出2.8%和3.6%。 更具体地说,在单班成绩上,FD-MobileNet在大多数班上的表现都优于MobileNet。 从表中可以看出,当计算预算较小时,FD-MobileNet比MobileNet有了更大的改进。 例如,当计算预算为12个MFLOP时,FD-MobileNet在MobileNet很难的类上实现了一致的改进,例如瓶(5.3%),椅子(2.4%)和船(0.2%)。 这些改进已证明FDMobileNet具有强大的泛化学习迁移能力

实际推断时间评估
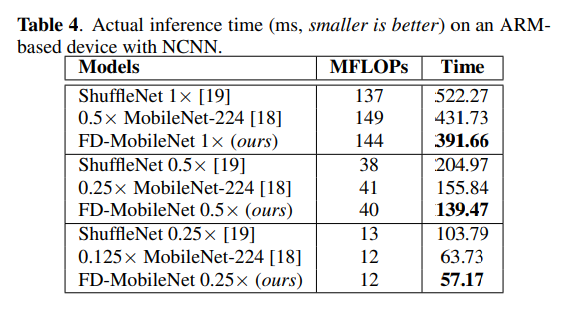
为了研究物理设备上的性能,文章进一步比较了基于ARM的平台上FD-MobileNet,MobileNet和ShuffleNet的实际推断时间。 实验是在i.MX 6系列CPU(单核,800 MHz)上使用优化的NCNN框架进行的。
表分别显示了在140、40和12个MFLOP的计算预算下三个紧凑网络的推理时间。 与MobileNet相比,在三个计算预算下,FD-MobileNet的速度是MobileNet的1.1倍。 这些改进归功于FD-MobileNet快速下采样架构的有效性。
与ShuffleNet相比,FD-MobileNet提供了明显更快的推理速度。当计算预算为140和40 MFLOP时,FD-MobileNet在ShuffleNet上分别获得1.33倍和1.47倍的加速。在12个MFLOP的复杂度下,速度得以提高:FD-MobileNet比ShuffleNet快1.82倍。值得注意的是,在140和40个MFLOP下,ShuffleNet模型的FLOP比FD-MobileNet同类的要少,但它们要慢得多。 这种减慢是由ShuffleNet单元的旁路连接结构效率低下引起的。在低功耗设备上,旁路连接结构会导致频繁的内存和高速缓存切换,从而减慢了实际推理速度。相反,简单的堆栈体系结构使FD-MobileNet可以更有效地利用内存和缓存,从而有助于提高实际推断速度。 这些结果表明FDMobileNet在实际的移动或嵌入式应用程序中有效。
总结
在这项工作中,文章介绍了快速下采样MobileNet(FDMobileNet),这是一种非常高效且准确的网络,适用于非常有限的计算预算。 FD-MobileNet是通过在最新的MobileNet框架中采用快速下采样策略而构建的。与原始MobileNet相比,快速下采样方案的利用允许更多的信道,这增加了网络的信息容量并有助于显着提高性能。 在ILSVRC 2012分类数据集和PASCAL VOC 2007检测数据集上进行的实验表明,在不同的计算预算下,FD-MobileNet始终优于MobileNet。 对实际推理时间的评估表明,在相同复杂度下,FD-MobileNet在基于ARM的设备上比ShuffleNet有了显着的加速。 为了将来的工作,文章计划在ShuffleNet等其他紧凑型网络中采用快速下采样策略,以提高性能。
收获
- 快速下采样策略
- 信道数量的增加有助于更大的信息容量,这对于在极其有限的计算资源下的网络性能至关重要















 2236
2236











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









