







 本文详细探讨了深度学习优化器的性能,通过广泛的基准测试比较了15种流行优化器在8个深度学习任务上的效果。研究发现优化器在不同任务间的性能差异显著,使用默认参数的多个优化器与微调单个优化器的效果相当。ADAM在多数情况下表现出色,但没有一种优化器在所有测试中占据主导地位。论文提供了开源的实验结果,有助于未来优化器的比较和选择。
本文详细探讨了深度学习优化器的性能,通过广泛的基准测试比较了15种流行优化器在8个深度学习任务上的效果。研究发现优化器在不同任务间的性能差异显著,使用默认参数的多个优化器与微调单个优化器的效果相当。ADAM在多数情况下表现出色,但没有一种优化器在所有测试中占据主导地位。论文提供了开源的实验结果,有助于未来优化器的比较和选择。
论文阅读笔记(一)——DESCENDING THROUGH A CROWDED VALLEY—BENCHMARKING DEEP LEARNING OPTIMIZERS
前言
把论文阅读笔记换一个地方存放了,当新的开始了~ 之前的到15的,其实很多都是偏应用的,所以这次从头认真看看吧~以前都是翻译软件阅读,现在顺便练习一下英语的阅读。
这是一篇关于优化器的论文
个人博客地址:二两酥肉
论文地址:Descending through a Crowded Valley - Benchmarking Deep Learning Optimizers
1、论文概念
1.1 论文摘要
优化器的选择被认为是在深度学习中最关键的设计决策之一,并且它不是一个简单的工作。越来越多的文献如今列出了上百种优化器方法。在缺乏清晰的理论指导和准确的权威证据下,关于优化器的决策往往充满奇闻轶事(anecdotes,有点奇怪,但是不知道怎么翻译合适)。在这项工作中,文章旨在取代这些奇闻轶事,如果不是一种结论性的排名,那么至少也要提供一种证据支持的启发式教学法。为此,文章对15个特别流行的深度学习优化器执行了广泛、标准化的基准测试,同时给出了广泛的可能选择的简明概述。分析了大约50000次单独的运行,文章得出了以下三点:(1)优化器表现在不同的任务重差异很大。(2)文章观察到,使用默认参数评估多个优化器的工作效果与调整单个固定优化器的超参数差不多。(3)虽然文章不能清楚地识别一个优化方法在所有测试任务中占主导地位,但是文章找到了一个显著减少的特定算法和参数选择的子集(subset),这些优化器和参数选择通常会导致文章的实验中具有竞争性的结果:ADAM仍然是一个强有力的竞争者,新的方法不能显著地和持续地超过它。文章把所有的实验结果进行了开源,让他们称为可用的具有挑战性和良好调整的基线。这允许在评估新的优化方法时进行更有意义的比较,而不需要进一步的计算工作。
1.2 创新点
1.2.1 优化器选择的公正实验
- 因为优化器很多,但是目前没有一个较为大规模的测验,测试不同优化器的基准测试,如果要想用相关的优化器只能去看论文原著,而原著都会吹自己,所以参考性并不会那么大。这篇文章进行了不涉及原著的第三方实证比较,对各种优化器进行了测试。
1.2.2 提供优化器使用指导
作者提出**“我们要为更有意义的、非增量的研究提供动力。”**,对不同的深度学习任务,提出了不同的使用指导,避免了大规模无效的比较。比如ADAM仍然是一个综合可行的选择,而NAG和RMSPROP在单个问题上优很好的效果。
1.2.3 总结一下
感觉实验还是比较充足,后面那一堆大图就可以看出来了,但是感觉有点太宽泛了,比如视觉任务上只是选择了MNIST和cifar10,100这种数据集,而网络代表性也不是非常具有权威性。感觉作者想做的太大了,导致在实际实验中,这篇论文可以提供参考性,但是不具备权威性。不过这篇论文很不错,值得读一下。
2、正文
2.1 工作
2.1.1一个优化算法和时间表的简明总结
提供了一个超过100个优化器和超过20个超参数计划组的紧凑广泛的列表。(表在文末,太大了,两张表没涨占一页,很丰富)
2.1.2在深度学习任务上进行的广泛的优化器测试
进行了大规模优化器基准测试,使用4种不同的调度对8个深度学习问题评估了14个优化器,并调整了几十个超参数设置。(确实不少了)
2.1.3分析超过5000次优化器的运行
- 评估带有默认超参数的多个优化器与为固定优化器微调超参数的效果差不多。
- 对总体而言,使用一个额外的未微调( untuned)的学习率计划(schedule)是有帮助的,但其效果很大程度上取决于优化器和测试问题。
- 虽然在所有测试的工作负载中没有明显占主导地位的优化器,但文章测试的一些算法表现出高度可变的性能(就是特定任务上有些优化器效果差异很大),其他的算法则表现良好。文章因此不推荐其中的任何一个,因为文章找不到一个具有统治地位的明显的赢家。
2.1.4对未来优化器基准测试的开源基线
提供了开源的结果代码,可以减少优化器比较所需的预算(确实)。并且推荐大家加入这个实验(意思是让你给个star)。
开源代码:文中提供的github链接
2.2 相关工作(同类论文推荐)
[1] Frank Schneider, Lukas Balles, and Philipp Hennig. DeepOBS: A Deep Learning Optimizer Benchmark Suite. In 7th International Conference on Learning Representations, ICLR, 2019.
[2] Prabhu Teja Sivaprasad, Florian Mai, Thijs V ogels, Martin Jaggi, and Francois Fleuret. Optimizer Benchmarking Needs to Account for Hyperparameter Tuning. In 37th International Conference on Machine Learning, ICML, 2020
2.3 实验方法
从100多个优化器中选出了14种优化器作为基准测试,使用了4种微调(Tuning)运算和4种学习率方法。
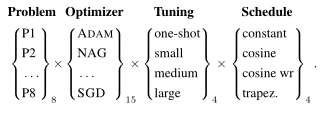
2.3.1 深度学习问题
选择了八种深度学习问题…现在看其实还是可以继续做下拓展&#x
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 2039
2039

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









