







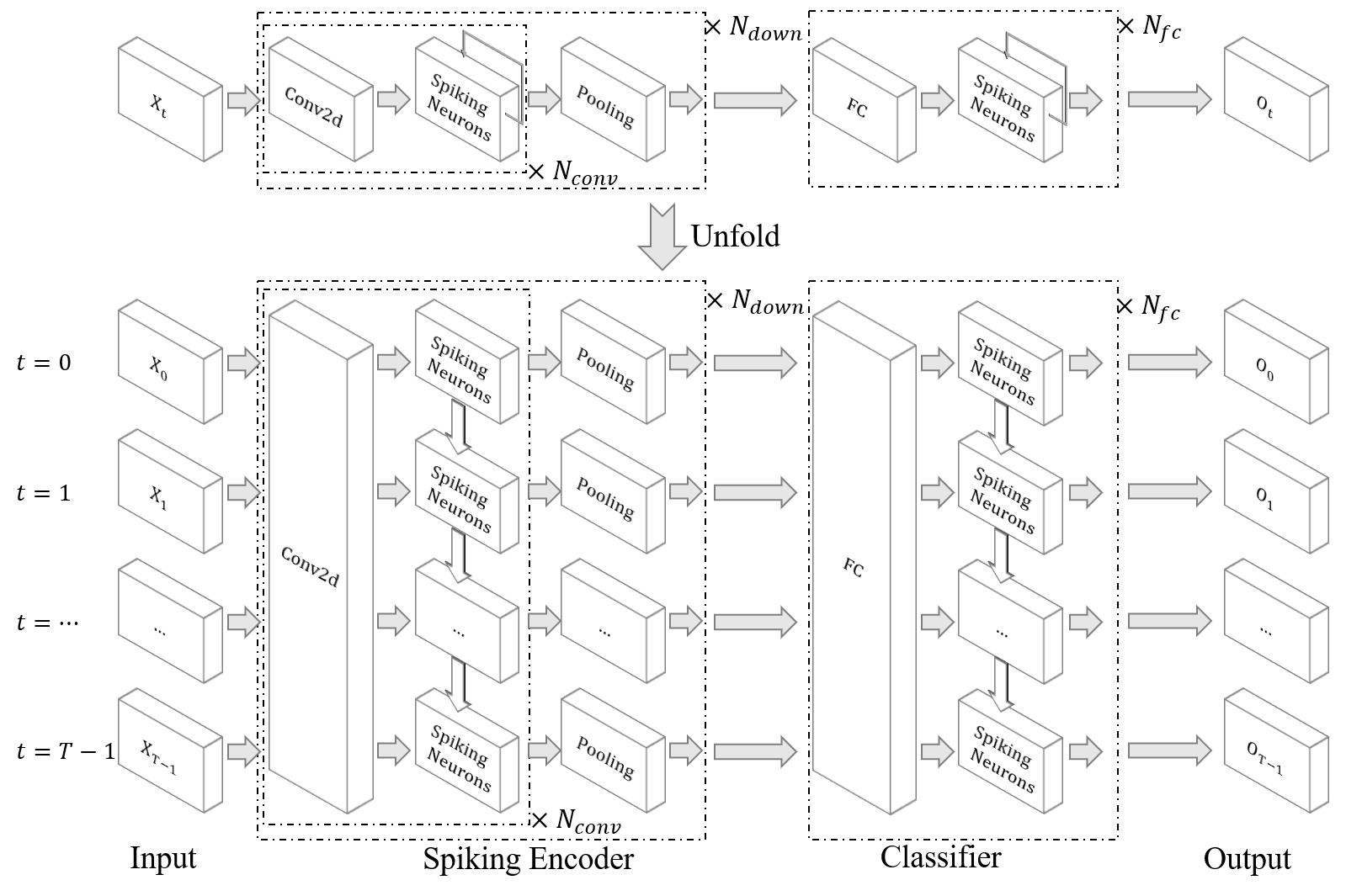
脉冲神经网络整体流程
1、导入库
import torch
import torch.nn as nn
import torch.optim as optim
import torch.nn.functional as F
from torchvision import datasets, transforms
import matplotlib.pyplot as plt
import numpy as np
# 若环境没有相应的包,则通过pip/conda install *** 进行安装
2、定义超参数
#####如下参数为常用参数,可自行添加或删除#####
parser = argparse.ArgumentParser(description='Classify MNIST Use LIF')
parser.add_argument('-device', default='cpu', help='运行的设备,例如“cpu”或“cuda:0”')
parser.add_argument('--dataset-dir', default='./', help='MNIST数据集的位置')
parser.add_argument('-b', '--batch-size', default=64, type=int, help='Batch 大小')
parser.add_argument('-T', '--timesteps', default=100, type=int, dest='T', help='时间窗口')
parser.add_argument('-lr', '--learning-rate', default=1e-3, type=float, metavar='LR', help='学习率')
parser.add_argument('-tau', default=2.0, type=float, help='LIF神经元的时间常数tau')
parser.add_argument('-epochs', default=64, type=int, metavar='N',
help='训练轮次')
parser.add_argument('-j', default=4, type=int, metavar='N',
help='number of data loading workers (default: 4)')
parser.add_argument('-channels', default=128, type=int, help='channels of Conv2d in SNN')
# parser.add_argument('--log-dir', default='./', help='保存日志文件的位置')
# parser.add_argument('--model-output-dir', default='./', help='模型保存路径')
args = parser.parse_args()
print(args)
3、定义网络结构 Net
需要先定义一个 Class,继承自 nn.Module类,这个 Class 里主要写两个函数,一个是初始化的 __init__函数,另一个是 forward 函数。
① Incorporating Learnable Membrane Time Constant to Enhance Learning of Spiking Neural Networks 论文中的网络模型
class VotingLayer(nn.Module):
def __init__(self, voter_num: int):
super().__init__()
self.voting = nn.AvgPool1d(voter_num, voter_num)
def forward(self, x: torch.Tensor):
# x.shape = [N, voter_num * C]
# ret.shape = [N, C]
return self.voting(x.unsqueeze(1)).squeeze(1)
# 参考:https://blog.csdn.net/m0_55519533/article/details/119103011
class Net(nn.Module):
def __init__(self, channels: int):
super().__init__()
conv = []
conv.extend(PythonNet.conv3x3(2, channels))
conv.append(nn.MaxPool2d(2, 2))
for i in range(4):
conv.extend(PythonNet.conv3x3(channels, channels))
conv.append(nn.MaxPool2d(2, 2))
self.conv = nn.Sequential(*conv)
# (0): Conv2d(2, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
# (1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
# (2): LIFNode(
# v_threshold=1.0, v_reset=0.0, detach_reset=True, tau=2.0
# (surrogate_function): ATan(alpha=2.0, spiking=True)
# )
# (3): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
self.fc = nn.Sequential(
nn.Flatten(),
layer.Dropout(0.5),
nn.Linear(channels * 4 * 4, channels * 2 * 2, bias=False),
neuron.LIFNode(tau=2.0, surrogate_function=surrogate.ATan(), detach_reset=True),
layer.Dropout(0.5),
nn.Linear(channels * 2 * 2, 110, bias=False),
neuron.LIFNode(tau=2.0, surrogate_function=surrogate.ATan(), detach_reset=True)
)
# (0): Flatten(start_dim=1, end_dim=-1)
# (1): Dropout(p=0.5)
# (2): Linear(in_features=2048, out_features=512, bias=False)
# (3): LIFNode(
# v_threshold=1.0, v_reset=0.0, detach_reset=True, tau=2.0
# (surrogate_function): ATan(alpha=2.0, spiking=True)
# )
self.vote = VotingLayer(10) # 平均池化,将输出层的tensor(16,110)采用投票机制,转为tensor(16,11)
# (voting): AvgPool1d(kernel_size=(10,), stride=(10,), padding=(0,))
def forward(self, x: torch.Tensor):
x = x.permute(1, 0, 2, 3, 4) # [N, T, 2, H, W] -> [T, N, 2, H, W]
out_spikes = self.vote(self.fc(self.conv(x[0])))
for t in range(1, x.shape[0]):
out_spikes += self.vote(self.fc(self.conv(x[t])))
return out_spikes / x.shape[0]
@staticmethod
def conv3x3(in_channels: int, out_channels):
return [
nn.Conv2d(in_channels, out_channels, kernel_size=(3, 3), padding=1, bias=False), # c128k3s1
nn.BatchNorm2d(out_channels), # BN
neuron.LIFNode(tau=2.0, surrogate_function=surrogate.ATan(), detach_reset=True) # MPk2s2
]
② 一个简单识别 MNIST 数据集的网络结构
net = nn.Sequential(
nn.Flatten(), # 将28*28->784
nn.Linear(28 * 28, 10, bias=False),
neuron.LIFNode(tau=tau)
)
将网络加载到运行设备上
net = Net()
net = net.to(device)
4、选择优化器 Optimizer
# 添加超参数
parser.add_argument('-opt', default='SGD', type=str, help='use which optimizer. SDG or Adam')
parser.add_argument('-momentum', default=0.9, type=float, help='momentum for SGD')
# 选择优化器:'SGD、Adam or others'
optimizer = None
if args.opt == 'SGD':
optimizer = torch.optim.SGD(net.parameters(), lr=args.lr, momentum=args.momentum)
elif args.opt == 'Adam':
optimizer = torch.optim.Adam(net.parameters(), lr=args.lr)
else:
raise NotImplementedError(args.opt)
# 输出net.parameters()参数,为各层网络权重值
for _, param in enumerate(net.parameters()):
print(param.shape)
5、(选用)选择学习率衰减策略
# 添加超参数
parser.add_argument('-lr_scheduler', default='CosALR', type=str, help='学习率衰减策略. StepLR or CosALR')
parser.add_argument('-step_size', default=32, type=float, help='step_size for StepLR')
parser.add_argument('-gamma', default=0.1, type=float, help='gamma for StepLR')
parser.add_argument('-T_max', default=32, type=int, help='T_max for CosineAnnealingLR')
# 选用学习率衰减策略:'StepLR or CosALR or others'
lr_scheduler = None
if args.lr_scheduler == 'StepLR':
lr_scheduler = torch.optim.lr_scheduler.StepLR(optimizer, step_size=args.step_size, gamma=args.gamma)
elif args.lr_scheduler == 'CosALR':
lr_scheduler = torch.optim.lr_scheduler.CosineAnnealingLR(optimizer, T_max=args.T_max)
else:
raise NotImplementedError(args.lr_scheduler)
6、(选用)自动混合精度训练
# 添加超参数
parser.add_argument('-amp', action='store_true', help='是否进行自动混合精度训练,可以大幅度提升速度,减少显存消耗')
scaler = None
if args.amp:
scaler = amp.GradScaler()
7、加载数据
train_dataset = torchvision.datasets.MNIST(
root=dataset_dir,
train=True,
transform=torchvision.transforms.ToTensor(),
download=True
)
test_dataset = torchvision.datasets.MNIST(
root=dataset_dir,
train=False,
transform=torchvision.transforms.ToTensor(),
download=True
)
train_data_loader = data.DataLoader(
dataset=train_dataset,
batch_size=batch_size,
shuffle=True,
drop_last=True
)
test_data_loader = data.DataLoader(
dataset=test_dataset,
batch_size=batch_size,
shuffle=False,
drop_last=False
)
8、编码数据为脉冲序列
在定义完之后,开始一次一次的循环:
① 先清空优化器里的梯度信息,optimizer.zero_grad();
② 再将data传入,正向传播,output=net(data);
③ 计算损失,loss=F.mse_loss(target,output) # 这里target就是识别目标,需要自己准备,和之前传入的input类型一一对应;
④ 误差反向传播,loss.backward();
⑤ 更新参数,optimizer.step();
⑥ 重置网络状态,functional.reset_net(net);














 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言










{kind=link}