







同步
- 显式同步
cudaDeviceSynchronize();
- 隐式同步
隐式方法就是不明确说明主机要等待设备端,而是设备端不执行完,主机没办法进行,比如内存拷贝函数:
cudaError_t cudaMemcpy(void* dst,const void * src,size_t count,cudaMemcpyKind kind);
主机端必须要等待设备端计算完成。
并行
并行程序中经常的一种现象:把串行代码并行化时对串行代码块for的操作,也就是把for并行化。
为什么能进行并行化:
是因为每个线程对应着自己在x,y,z三维的blockIdx和threadIdx。能直接完成线程“坐标”对数组“坐标”的映射关系。
一句话总结:内置的线程坐标变量替换了数组索引。for循环的N被隐式定义用来启动N个线程
最简单的:
- 串行
void sumArraysOnHost(float *A, float *B, float *C, const int N) {
for (int i = 0; i < N; i++)
C[i] = A[i] + B[i];
}
如要并行此循环,必须执行以下 2 个步骤:
- 编写用于执行单次迭代工作的核函数。
- 调用核函数时为它配置执行参数,即并行的线程数,每个线程执行一次迭代。
- 并行
写的时候只需要想着对当前的线程&已知Idx——>对应着完成哪一块的矩阵运算
__global__ void sumArraysOnGPU(float *A, float *B, float *C) {
int i = threadIdx.x;
C[i] = A[i] + B[i];
}
上述代码,若取N=32。则和sumArraysOnGpu<<<1,32>>>()起到相同的作用。如果多到线程数目不够了,那就一轮一轮地轮着来。
计时
1、核函数
核函数开始执行后马上返回主机线程,所以我们必须要加一个同步函数等待核函数执行完毕,如果不加这个同步函数,那么测试的时间是从调用核函数,到核函数返回给主机线程的时间段
//timer
double iStart,iElaps;
iStart=cpuSecond();
sumArraysGPU<<<grid,block>>>(a_d,b_d,res_d,nElem);
cudaDeviceSynchronize();
iElaps=cpuSecond()-iStart;
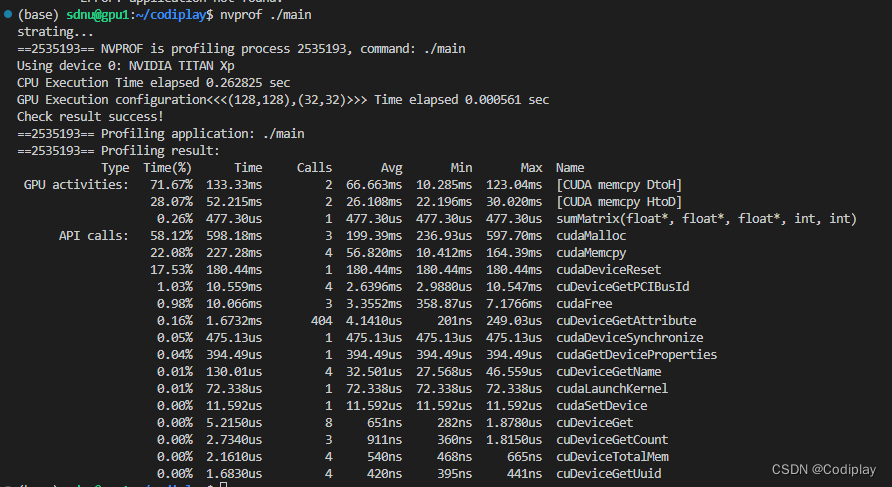
2、nvprof
nvprof是nvidia提供的用于生成gpu timeline的工具
介绍一个参数 nvprof --print-gpu-trace ./main打印GPU内发生的变化,比如memcpy的时候传输的大小、带宽;调用矩阵函数的时候Block Size,Grid Size etc.















 1149
1149











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









