






实际上,优化算法可以分成一阶优化和二阶优化算法,其中一阶优化就是指的梯度算法及其变种,而二阶优化一般是用二阶导数(Hessian 矩阵)来计算,如牛顿法,由于需要计算Hessian阵和其逆矩阵,计算量较大,因此没有流行开来。
一、SGD
样本少可以采用BGD,样本过大可以SGD,实际情况下一般MBGD。这三种形式的区别就是取决于用多少数据来计算目标函数的梯度, 涉及到参数更新的准确率和运行时间。
(1)BGD是一次将所有的样本点进行扫描并计算出梯度,每一步迭代都使用训练集的所有内容。这样对于较大的数据集速度很慢,而且也并不保险,很可能花了很长时间走到了局部最优,可是又出不来了,因为这里的梯度是0。所以并不实用。
梯度更新规则:提取训练集中的所有内容{x1,…,xn},以及相关的输出yi,计算梯度和误差并更新参数:
![]()
优点:
- 由于每一步都利用了训练集中的所有数据,因此当损失函数达到最小值以后,能够保证此时计算出的梯度为0,就是说能够收敛,因此使用BGD时不需要逐渐减小学习速率
缺点:
- 由于这种方法是在一次更新中,就对整个数据集计算梯度,所以计算起来非常慢,遇到很大量的数据集也会非常棘手,而且不能投入新数据实时更新模型
- 我们会事先定义一个迭代次数 epoch,首先计算梯度向量 params_grad,然后沿着梯度的方向更新参数 params,learning rate 决定了我们每一步迈多大。
- Batch gradient descent 对于凸函数可以收敛到全局极小值,对于非凸函数可以收敛到局部极小值。
(2)样本较大时可以用SGD,随机梯度下降,也就是说,每次只用一个随机抽取的样本点求导数,作为最终结果,进行下降,这样虽然不如直接做BGD在路径上更稳定,但是一般最终会找到最优解。还有好处是可以在局部最优解中跳出来,只要新选取的一个样本可以提供一个向外的梯度。SGD是一种可以用来做在线学习的,也就是每进来一个样本就更新一下参数。此外SGD比BGD收敛更快。
梯度更新规则:从训练集中的随机抽取一个x1,以及相关的输出y1,计算梯度和误差并更新参数:

η是学习率,gt 代表着某一个样本的梯度gradient。

缺点:
- SGD 因为更新比较频繁,会造成 cost function 有严重的震荡,此外SGD对噪声比较敏感。
(3)MBGD,就是每一次迭代计算mini-batch的梯度,然后对参数进行更新,可以尽量减少波动,同时又不必把所有的都投入训练,是最常见的优化方法。但是小批量下降并不能保证很好的收敛,并且,需要选择learning rate。完全依赖于当前batch的梯度,η可理解为允许当前batch的梯度多大程度影响参数更新。
批量梯度下降法:相当于前两种的折中方案,抽取一个批次的样本计算总误差,比如总样本有10000个,可以抽取1000个作为一个批次,然后根据该批次的总误差来更新权值。
梯度更新规则:从训练集中的随机抽取一批容量为m的样本{x1,…,xm},以及相关的输出yi,计算梯度和误差并更新参数:

优点:
- 训练速度快,对于很大的数据集,也能够以较快的速度收敛。
缺点:
- 选择合适的learning rate比较困难,如果选择的太小,收敛速度会很慢,如果太大,loss function 就会在极小值处不停地震荡甚至偏离。
- 对所有的参数更新使用同样的learning rate。对于稀疏数据或者特征,有时我们可能想更新快一些对于不经常出现的特征,对于常出现的特征更新慢一些,这时候SGD就不太能满足要求了
- 对于非凸函数,还要避免陷于局部极小值处,或者鞍点处,因为鞍点周围的error 是一样的,所有维度的梯度都接近于0,SGD 很容易被困在这里。
二、Momentum
除了调整学习率之外,还可以通过使用最近一段时间内的平均梯度来代替当前时刻的梯度来作为参数更新的方向。在小批量梯度下降中,如果每次选取样本数量比较小,损失会呈现震荡的方式下降。有效地缓解梯度下降中的震荡的方式是通过用梯度的移动平均来代替每次的实际梯度,并提高优化速度,这就是动量法。
上面的SGD有个问题,就是每次迭代计算的梯度含有比较大的噪音。而Momentum方法可以比较好的缓解这个问题,尤其是在面对小而连续的梯度但是含有很多噪声的时候,可以很好的加速学习。
momentum是模拟物理里动量的概念,动量法是用之前积累动量来替代真正的梯度。每次迭代的梯度可以看作是加速度。在第t次迭代时,其中 μ 为动量因子,通常设为0.9。momentum项能够在相关方向加速SGD,抑制振荡,从而加快收敛。
梯度更新规则:从训练集中的随机抽取一批容量为m的样本{x1,…,xm},以及相关的输出yi,计算梯度和误差,并更新速度v和参数θ:

特点:
- 当前权值的改变会收到上一次权值的改变的影响,就像小球滚动时候一样,由于惯性,当前状态会受到上一个状态影响,这样可以加快速度。
- 下降初期时,使用上一次参数更新,下降方向一致,乘上较大的μ能够进行很好的加速
- 下降中后期时,在局部最小值来回震荡的时候,gradient→0,μ使得更新幅度增大,跳出陷阱
- 在梯度改变方向的时候,μ能够减少更新。
三、Nesterov
NAG就是要解决直接动量下降可能直接迈的步子太大的问题,在梯度更新时做一个校正,避免前进太快,同时提高灵敏度。
因为当前下降的时候是无法知道下一步究竟落在什么地方,但是由于momentum中下一步达到的位置很大程度是由动量项决定的,因此可以先用动量项估计一下下一步的大概位置,然后在估计的位置求取梯度,在将这个梯度作为更新的梯度项,和动量项加起来做一个update。
将上一节中的公式展开可得:Δθt=−η∗μ∗mt−1−η∗gt
可以看出, mt−1并没有直接改变当前梯度 gt,所以Nesterov的改进就是让之前的动量直接影响当前的动量。
梯度更新规则:从训练集中的随机抽取一批容量为m的样本{x1,…,xm},以及相关的输出yi,计算梯度和误差,并更新速度v和参数θ:

所以,加上nesterov项后,梯度在大的跳跃后,进行计算对当前梯度进行校正。下面这个图表示的就是momentum和NAG的区别,

momentum首先计算一个梯度(短的蓝色向量),然后在加速更新梯度的方向进行一个大的跳跃(长的蓝色向量),nesterov项首先在之前加速的梯度方向进行一个大的跳跃(棕色向量),计算梯度然后进行校正(绿色梯向量)。
- 与momentum相比,它更为聪明,因为momentum是一个路痴,它不知道去哪里,而NAG则知道我们的目标在哪里。也就是NAG知道我们下一个位置大概在哪里,然后提前计算下一个位置的梯度。然后应用于当前位置指导下一步行动。
四、Adagrad
前面的sgd是对所有的参数统一求导和下降的,但是由于实际数据中可能存在这样一种情况:有些参数已经近乎最优,因此只需要微调了,而另一些可能还需要很大的调整。这种情况可能会在样本较少的情况下出现,比如含有某一特征的样本出现较少,因此被代入优化的次数也较少,这样就导致不同参数的下降不平衡。adagrad就是来处理这类问题的。
adagrad的基本想法是,对每个参数theta自适应的调节它的学习率,只是需要设定一个全局的学习速率ϵ,自适应的方法就是对每个参数乘以不同的系数,并且这个系数是通过之前累积的梯度大小的平方和决定的,也就是说,对于之前更新很多的,相对就可以慢一点,而对那些没怎么更新过的,就可以给一个大一些的学习率。
梯度更新规则:
Adagrad其实是对学习率进行了一个约束。从训练集中的随机抽取一批容量为m的样本{x1,…,xm},以及相关的输出yi,计算梯度和误差,更新r,再根据 nt 和梯度计算参数更新量。此处,对 gt 从 1 到 t 进行一个递推形成一个约束项 regularizer, ϵ用来保证分母非0。其中⊙是按元素相乘 。

特点:
- 能够实现学习率的自动更改。对于常见的数据给予比较小的学习率去调整参数,对于不常见的数据给予比较大的学习率调整参数。它可以自动调节学习率,但迭代次数多的时候,学习率也会下降。
- 适合处理稀疏梯度
缺点:
- 由公式可以看出,仍依赖于人工设置一个全局学习率η
- 设置过大的话,会使regularizer过于敏感,对梯度的调节太大
- 但是时间太长的话,会造成步长太小,困在局部极值点
- 中后期,分母上梯度平方的累加将会越来越大,使gradient→0,使得训练提前结束
代码实现:
def sgd_adagrad(parameters, sqrs, lr):
eps = 1e-10
for param, sqr in zip(parameters, sqrs):
sqr[:] = sqr + param.grad.data ** 2
div = lr / torch.sqrt(sqr + eps) * param.grad.data
param.data = param.data - div
五、Adadelta
AdaDelta下降不需要设置学习率。它的基本思路是:首先,借鉴了Adagrad的思路,对每个参数进行自适应的学习率变化,依据的也是之前的梯度的累积,但是这里不是像Adagrad那样直接加起来,而是用平均值的方式(实际使用的是RMS),把之前的梯度大小的影响加进来。目的是计算历史梯度在某个窗内的值的均值,但是不通过储存窗口内的值,而是用了当前的均值和当前的梯度来近似计算。
Adadelta是对Adagrad的扩展,最初方案依然是对学习率进行自适应约束,但是进行了计算上的简化。Adagrad会累加之前所有的梯度平方,而Adadelta只累加固定大小的项,并且也不直接存储这些项,仅仅是近似计算对应的平均值。即:

AdaDelta算法还维护一个额外的状态变量Δxt。使用Δxt−1来计算自变量的变化量,在此处Adadelta其实还是依赖于全局学习率的, 但是作者做了一定处理,经过近似牛顿迭代法之后:

其中, E代表求期望。此时,可以看出Adadelta已经不用依赖于全局学习率了。
特点:
- 训练初中期,加速效果不错,很快
- 训练后期,反复在局部最小值附近抖动
- AdaDelta算法没有学习率超参数,它通过使用有关自变量更新量平方的指数加权移动平均的项来替代RMSProp算法中的学习率。
六、RMSprop
这个实际上是对adagrad的一个改进,也就是把Adagrad对历史梯度加和变成了对历史梯度求均值,然后用这个均值代替Adagrad的累加的梯度和对当前梯度进行加权,并用来update。用均值代替求和是为了解决Adagrad的学习率逐渐消失的问题。
梯度更新规则:
从训练集中的随机抽取一批容量为m的样本{x1,…,xm}了,以及相关的输出yi,计算梯度和误差,更新 ,再根据
和梯度计算参数更新量。
RMSprop可以算作Adadelta的一个特例:当ρ=0.5时,就变为了求梯度平方和的平均数。
如果再求根的话,就变成了RMS(均方根):

此时,这个RMS就可以作为学习率 η的一个约束:

特点:
- 其实RMSprop依然依赖于全局学习率。
- RMSprop算是Adagrad的一种发展,和Adadelta的变体,效果趋于二者之间。
- 相比于AdaGrad,这种方法很好的解决了深度学习中过早结束的问题。
- 适合处理非平稳目标,对于RNN效果很好。
七、Adam
adam融合了Adagrad和RMSprop的思想。Adam(Adaptive Moment Estimation)本质上是带有动量项的RMSprop,在RMSProp算法的基础上对小批量随机梯度也做了指数加权移动平均。 它利用梯度的一阶矩估计和二阶矩估计动态调整每个参数的学习率。Adam的优点主要在于经过偏置校正后,每一次迭代学习率都有个确定范围,使得参数比较平稳。
会把之前衰减的梯度和梯度平方保存起来,使用RMSprob,Adadelta相似的方法更新参数,动量法+ Bias correct(动量的基于时间的无偏估计)+ RMSprob
梯度更新规则:
从训练集中的随机抽取一批容量为m的样本{x1,…,xm},以及相关的输出yi,计算梯度和误差,更新mt和nt,再根据 mt 和 nt 以及梯度计算参数更新量

其中, mt, nt分别是对梯度的一阶矩估计和二阶矩估计,可以看作对期望 E|gt|, E|g2t|的估计; mt^, nt^是对 mt, nt的校正,这样可以近似为对期望的无偏估计。
可以看出,直接对梯度的矩估计对内存没有额外的要求,而且可以根据梯度进行动态调整,对学习率形成一个动态约束,而且有明确的范围。
自适应动量估计(Adaptive Moment Estimation,Adam)算法可以看作是动量法和RMSprop的结合,不但使用动量作为参数更新方向,而且可以自适应调整学习率。
| 梯度方向优化 | 优化算法 |
| 梯度方向优化 | 动量法、Nesterov加速梯度 、梯度裁剪等 |
| 改进梯度 | Adam≈动量法+RMSprop |
特点:
- 结合了Adagrad善于处理稀疏梯度和RMSprop善于处理非平稳目标的优点
- 对内存需求较小
- 为不同的参数计算不同的自适应学习率。
- 也适用于大多非凸优化,适用于大数据集和高维空间
八、Adamax
Adamax是Adam的一种变体,此方法对学习率的上限提供了一个更简单的范围。公式上的变化如下:

可以看出,Adamax学习率的边界范围更简单。
九、Nadam
Nadam类似于带有Nesterov动量项的Adam。公式如下:

可以看出,Nadam对学习率有了更强的约束,同时对梯度的更新也有更直接的影响。一般而言,在想使用带动量的RMSprop,或者Adam的地方,大多可以使用Nadam取得更好的效果。
经验之谈
- 对于稀疏数据,尽量使用学习率可自适应的优化方法,不用手动调节,而且最好采用默认值,即 Adagrad, Adadelta, RMSprop, Adam。
- SGD通常训练时间更长,容易陷入鞍点,但是在好的初始化和学习率调度方案的情况下,结果更可靠
- 如果在意更快的收敛,并且需要训练较深较复杂的网络时,推荐使用学习率自适应的优化方法。
- Adadelta,RMSprop,Adam是比较相近的算法,在相似的情况下表现差不多。
- Adam 就是在 RMSprop 的基础上加了 bias-correction 和 momentum。随着梯度变的稀疏,Adam 比 RMSprop 效果会好。整体来讲,Adam 是最好的选择。
- 在想使用带动量的RMSprop,或者Adam的地方,大多可以使用Nadam取得更好的效果
损失平面等高线
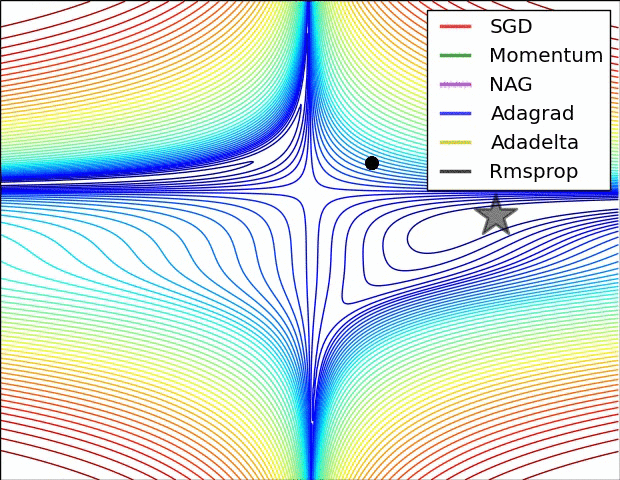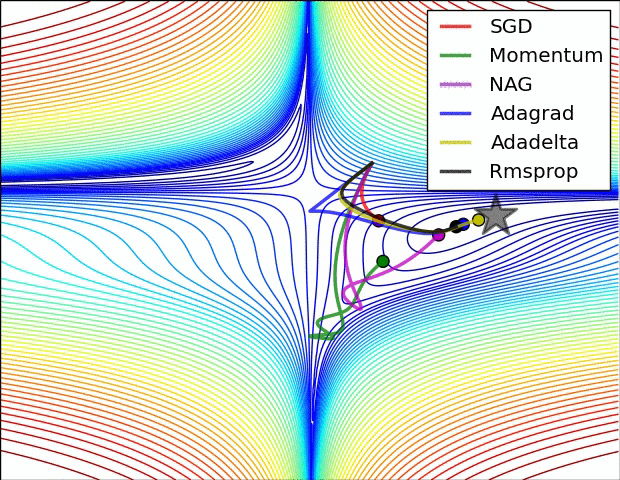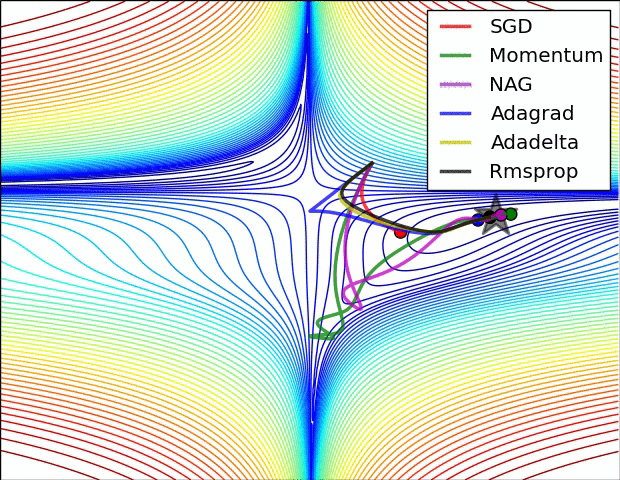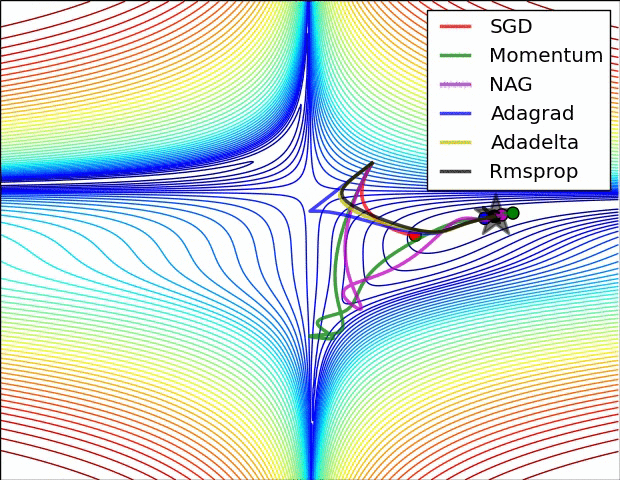
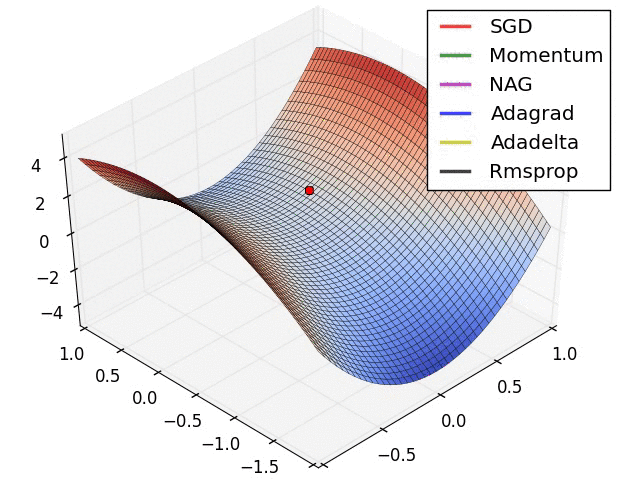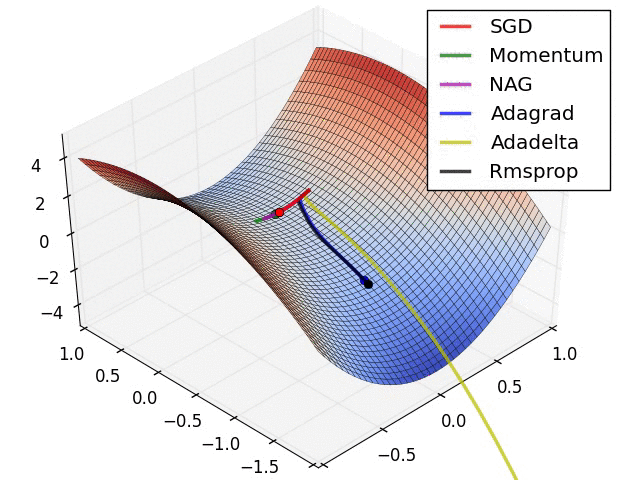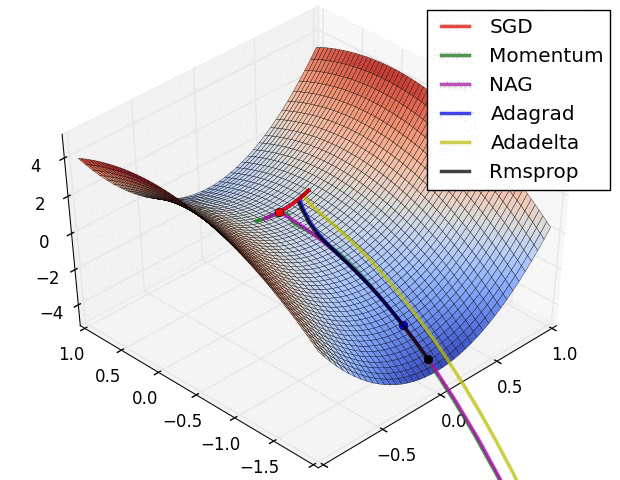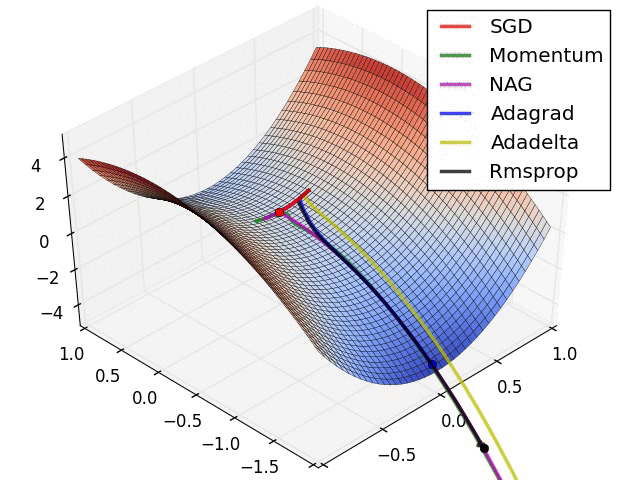
上面两种情况都可以看出,Adagrad, Adadelta, RMSprop 几乎很快就找到了正确的方向并前进,收敛速度也相当快,而其它方法要么很慢,要么走了很多弯路才找到。
由图可知自适应学习率方法即 Adagrad, Adadelta, RMSprop, Adam 在这种情景下会更合适而且收敛性更好。
参考文献:
机器学习优化过程中的各种梯度下降方法(SGD,AdaGrad,RMSprop,AdaDelta,Adam,Momentum,Nesterov)_江户川柯壮的博客-CSDN博客_adadelta梯度下降
深度学习最全优化方法总结比较(SGD,Adagrad,Adadelta,Adam,Adamax,Nadam)_ycszen的博客-CSDN博客_adam和nadam
深度学习笔记:优化方法总结(BGD,SGD,Momentum,AdaGrad,RMSProp,Adam)_sunflower_sara的博客-CSDN博客_adagrad
《动手学深度学习》第三十三天---AdaGrad算法,RMSProp算法,AdaDelta算法,Adam算法_打着灯笼摸黑的博客-CSDN博客















 3万+
3万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









