






1.编写算法将单链表反转,时间复杂度为O(n),空间复杂度为O(1)(原链表上操作,不创建新的链表)。
带头节点的单链表:
LinkList Reverse_1 (LinkList &L){
//依次遍历线性表L,并将结点指针反转
LNode *pre,*p=L->next,*r=p->next;
p->next=NULL;
while(r!=NULL){
pre=p;
p=r;
r=r->next;
p->next=pre;
}
L->next=p;
return L;
}
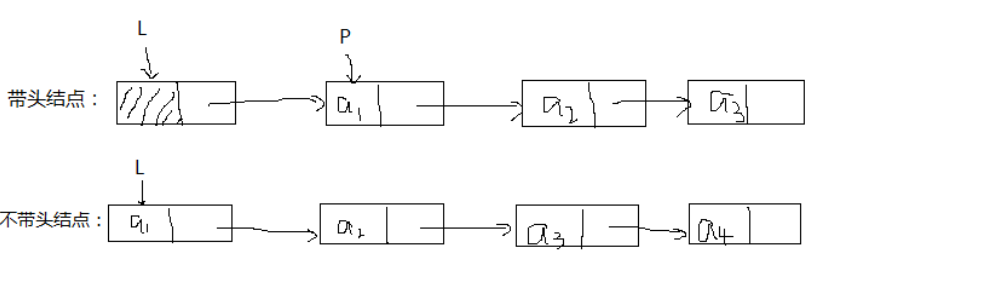
关于“头结点”和“头指针”:单链表中头指针始终存在,一般用L表示,当有头结点时,头指针指向头节点,当没有头结点时,头指针指向第一个元素结点。为了操作上的方便,在单链表的第一个结点之前附加一个结点,称为头结点。头结点的数据域可以不设任何信息,也可以记录表长等相关信息。
不带头结点的单链表:
LinkList Reverse_1 (LinkList &L){
//依次遍历线性表L,并将结点指针反转
LNode *pre,*p=L,*r=p->next;
p->next=NULL;
while(r!=NULL){
pre=p;
p=r;
r=r->next;
p->next=pre;
}
L=p;
return L;
}2.三人斗地主,共54张牌,农民17张牌,地主20张牌,问大小王同时出现在一人手里的概率是多少?
大小王同时在农名1手中:k1=C(15,52)/C(17,54)=0.09504
大小王同时在农民2手中:k2=C(15,52)/C(17,54)=0.09504
大小王同时在地主手中: k3=C(18,52)/C(20,54)=0.13277
则大小王同时出现在一人手里的概率为:
k1+k2+k3=0.32285
3.成绩表table_score中,写出降序查询分数排名10-20名的学生的name的mysql中执行的sql语句。
select name from table_score order by scoredesc limit 9,10
本题要求的写的是mysql的SQL语句,mysql中前n条记录或者是某段记录,一般使用limit,不同于sql server 和 access中的top,limit 9,10 前面的9代表从第10个开始,后面的10代表取连续10个。limit 10 则代表前10个。
4.极大似然估计在朴素贝叶斯中的作用。
极大似然估计的目的是极大化似然函数(极大化概率模型-)。朴素贝叶斯使用极大似然估计进行参数估计、使用极大后验概率估计进行决策。极大后验概率估计的目的是极大化参数的后验概率,从公式上来说只比极大似然估计的公式多了一项参数的先验概率。
5.欠拟合和过拟合产生的原因,如何避免?
欠拟合的原因:模型复杂度过低,不能很好的拟合所有的数据,训练误差大;
避免欠拟合:增加模型复杂度,如采用高阶模型(预测)或者引入更多特征(分类)等。
过拟合的原因:模型复杂度过高,训练数据过少,导致训练误差小,而测试误差大,即泛化能力差;
避免过拟合:降低模型复杂度,如加上正则惩罚项,如L1,L2,增加训练数据等。
6.写出sigmoid函数公式,描述其在逻辑回归中的作用。

逻辑回归和多重线性回归模型有很多相同之处,最大的区别就是它们的因变量不同,逻辑回归在多维线性回归的外面套上了一个sigmoid激活函数。为什么要套上sigmoid这个激活函数呢?因为多维线性回归的结果是在负无穷到正无穷之间的,为了能表示预测的概率,我们希望把输出值限制在0-1之间,而不是负无穷到正无穷,所以使用了sigmoid函数。
7.核函数在SVM中的作用。
将数据从原始空间映射到一个更高维的特征空间,可以解决数据在原始低维空间线性不可分的问题。但是如果维数太高甚至无穷维,就会带来计算量的问题,这时候就需要核函数。核函数是二元函数,输入是变换之前的两个向量,其输出与两个向量变换之后的内积相等。低维空间核函数=高维空间向量内积。核函数相当于用在低维空间内的计算模拟了向高维空间映射后在高维空间内的计算。
核函数让人们不需要知道Φ(.)长什么样,不需要知道怎么选取映射,就能够算出内积。因此这常常被认作是一种implicit mapping(隐映射)。这是由Mercer Theorem 保证的,即只要核函数满足一定条件,那么映射空间一定存在。
8.梯度下降法与随机梯度下降法的区别。















 998
998

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









