




发展阶段:
-
起步发展期:1943年—20世纪60年代
-
反思发展期:20世纪70年代
-
应用发展期:20世纪80年代
-
平稳发展期:20世纪90年代—2010年
-
蓬勃发展期:2011年至今
2.1 起步发展期:1943年—20世纪60年代
人工智能概念的提出后,发展出了符号主义、联结主义(神经网络),相继取得了一批令人瞩目的研究成果,如机器定理证明、跳棋程序、人机对话等,掀起人工智能发展的第一个高潮。
- 1943年,美国神经科学家麦卡洛克(Warren McCulloch)和逻辑学家皮茨(Water Pitts)提出神经元的数学模型,这是现代人工智能学科的奠基石之一。

- 1950年,艾伦·麦席森·图灵(Alan Mathison Turing)提出“图灵测试”(测试机器是否能表现出与人无法区分的智能),让机器产生智能这一想法开始进入人们的视野。

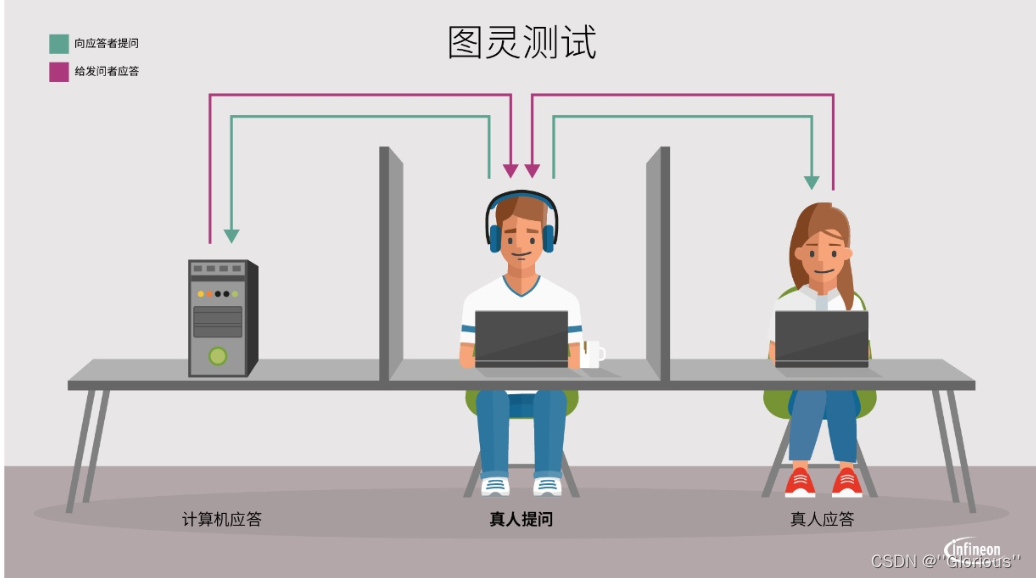
图灵测试,也就是图灵所说的"模仿游戏""的操作很简单:一位询问者将自己的问题写下来,发给处于另外一个房间之中的一个人和一台机器,然后根据他们给出的答案确定哪个是真人——如果无法判断或混淆了被考察的机器和人,则可认为被测试的机器具有某种程度的智慧
图灵测试视频讲解:【什么是图灵测试?】https://www.bilibili.com/video/BV1bW4y1n7Xz
- 1950年,克劳德·香农(Claude Shannon)提出计算机博弈。

- 1956年,达特茅斯学院人工智能夏季研讨会上正式使用了人工智能(artificial intelligence,AI)这一术语。这是人类历史上第一次人工智能研讨,标志着人工智能学科的诞生。
-
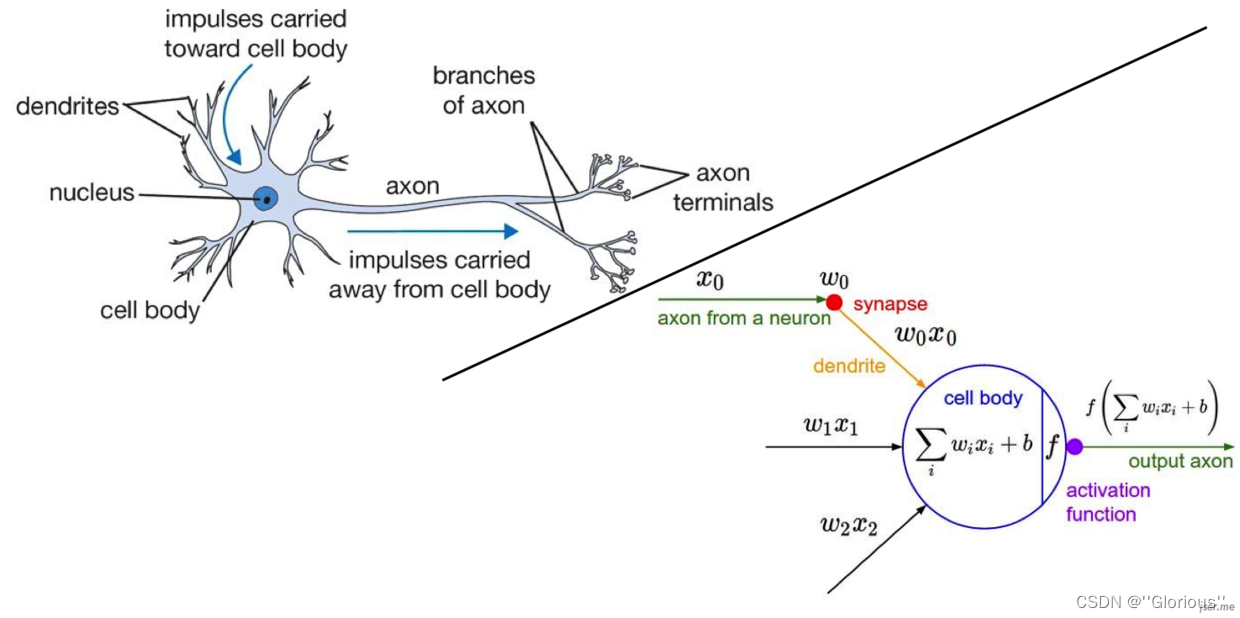
1957年,弗兰克·罗森布拉特(Frank Rosenblatt)在一台IBM-704计算机上模拟实现了一种他发明的叫做“感知机”(Perceptron)的神经网络模型。


感知机可以被视为一种最简单形式的前馈式人工神经网络,是一种二分类的线性分类判别模型,其输入为实例的特征向量想(x1,x2...),神经元的激活函数f为sign,输出为实例的类别(+1或者-1),模型的目标是要将输入实例通过超平面将正负二类分离。
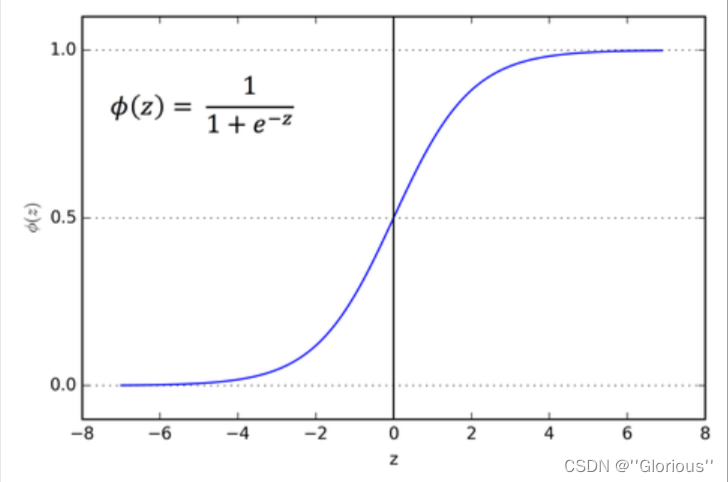
1958年,David Cox提出了logistic regression
LR是类似于感知机结构的线性分类判别模型,主要不同在于神经元的激活函数f为sigmoid,模型的目标为(最大似然)极大化正确分类概率。
- 1959年,Arthur Samuel给机器学习了一个明确概念:Field of study that gives computers the ability to learn without being explicitly programmed.(机器学习是研究如何让计算机不需要显式的程序也可以具备学习的能力)

1961年,Leonard Merrick Uhr 和 Charles M Vossler发表了题目为A Pattern Recognition Program That Generates, Evaluates and Adjusts its Own
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 14万+
14万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









