









CMTR: Cross-modality Transformer for Visible-infrared Person Re-identification(CMTR:用于可见光-红外行人重识别的跨模态 Transformer )
期刊合集:最近五年,包含顶刊,顶会,学报>>网址
文章来源:ECCV 2022
研究背景
现有基于 CNN 的方法存在缺陷:由于模态信息感知的不足,导致无法学习到良好的鉴别模态不变的身份嵌入,为了解决这个问题,文章提出了 CMTR 方法,能够明确地挖掘出每个模态的信息,并在此基础上生成更好的识别特征。具体来说,为了获取模态的特征,文章设计了新的模态嵌入,它与令牌嵌入融合在一起,对模态信息进行编码。此外,为了增强模态嵌入的表示,调整匹配嵌入的分布,提出了基于模态学习信息的模态感知增强损失,减小了类内距离,增大了类间距离。
论文分析
贡献点如下:
-
引入了可学习模态嵌入 (ME),它直接挖掘模态信息,可以有效地缓解异构图像之间的差距。
-
设计了一个新颖的模态感知增强 (MAE) 损失函数,该函数强制 ME 捕获每个模态的更多有用特征,并协助生成判别特征。
CMTR 网络框架
评价指标:累积匹配特征曲线(CMC);平均均值精度(mAP);平均负逆惩罚(mINP)
在输入图像之前,将红外图像的单通道重复了三次,使其包含三个通道。在训练过程中,使用到了数据增强策略:随机水平翻转和随机擦除。

Overall Network Structure( 整体网络结构)

1、输入嵌套
作者通过步幅s (s < P) (软分割) 生成重叠的斑块,以增强相邻斑块之间的相关性,可以将patch重新塑造为形状为 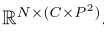 ,原来是
,原来是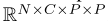 。
。
需要注意的是:斑块在被发送到 Transformer 之前,令牌嵌入序列与位置嵌入和设计模态嵌入 (ME) 融合在一起,外加一个额外的可学习 [class] 标记嵌入合并到序列中,以捕获整个图像的全局注意力。
2、特征提取
设 I 和 F 为输入嵌入和特征提取的过程,图像向量的提取方法如下:

3、多重损失约束
在多损失约束阶段,从训练批中获得的这些图像向量会经过批归一化( BN )层和全连接( FC )层。不同的层计算不同的损失,以生成对可见-红外模态不变的更具鉴别性的ID嵌入。
Visible-infrared Modality Embeddings(可见-红外模态嵌入 )
感知情态特征有助于生成情态不变特征,所以在模型中引入了模态嵌入(ME) 模块,目的是学习和捕获每个模态的固有信息和特征。
输入嵌入主要由三部分组成:token embeddings,position embeddings和modality embeddings。对于模态嵌入,每个模态中的图像与所有补丁共享相同的嵌入。
输入的嵌套阶段可表述为:

对于公式的理解:首先这个公式是由三部分组成的,第一个是令牌嵌入,第二个是位置嵌入,第三个是模态嵌入。位置嵌入在不同的斑块之间是不同的,模态嵌入在不同的图像的模态之间是不同的,用来感知不同类型的信息。
Modality-aware Enhancement Loss(模态感知增强损失 )
使用模态嵌入让模态嵌入在语义上捕获了模态的特征,但约束相对较弱,不能完美指导模态学习。为了进一步增强 ME 学习模态信息的能力,并让学习到的 ME 帮助生成更有效的模态不变嵌入,提出了模态感知增强 (MAE) 损失。

MAE 损失由两部分组成:模态感知中心损失( LMAC )和模态感知 ID 损失( LMAID ),旨在基于模态嵌入拉出类内特征和推入类间特征,表示如下:

对于LM AC的定义,重点是减少同一身份下不同模态之间的差距,并利用 ME 学习的知识来缩小类内特征的距离。

LMAC 的重点任务是减少同一身份下不同模态之间的差距,并利用 ME 学习的知识来缩小类内特征的距离。由以下公式表示:

其中,f mq,k表示从 q 身份的 k 个 m 模态图像中提取的特征。φm(·) 表示映射,用于挖掘模态嵌入em的知识,采用全连接层来实现。

让 f mq,k 减去φm(em) 其实是为了去除模态特定的信息,过滤掉模态不变的特征。
其中,f mq,c表示 q 身份的中心特征向量,为去模态后图像特征的均值。使用余弦距离D( · , ·)来测量图像特征与其中心特征向量之间的距离。通过模态感知中心损失 LM AC 的约束,我们的方法为每个身份提取更紧凑的跨模态特征。
模态感知 ID损失 ( LM AID ) 旨在学习不同身份之间的判别特征,它也是基于学习到的 ME 信息,中间也有一步要去过滤掉模态不变的特征,具体表示为:

Overall Objective Function(总体目标函数)

如上图所示,网络接受三种损失的约束,并对这些约束进行了联合优化。总体目标函数定义如下:

实验结果


交融实验:

通过上表可以发现:MAE 约束损失存在较大的潜力,包含的 MAC 跟 MAID 有着巨大的互补性和潜力,通过第三行跟第四行结果显示,合理运用两层损失可以达到更好的性能。
总结
在本文中,提出了应用于跨模态行人重识别的跨模态 Transformer (CMTR) 网络。通过引入模态嵌入 (ME),该模型可以直接感知每个模态的特征。此外,设计的模态感知增强损失 (MAE),它可以增强 ME 的学习能力,帮助生成更好的判别模态不变嵌入。

( a ) 是可见光源图像,( b ) 是红外光源图像,( c ) / ( d ) 是通过 Base 基线生成的 CAM 图,( e ) / ( f ) 是通过 Base+ME 生成的 CAM 图,不难发现,图像经过 Base+ME 操作之后,图像中的不变特征多了很多,轮廓信息也展示出来更多了。

不同的颜色代表不同的身份,实心方和空心圆分别代表两种模态图像。从图 (a) 到图 (b) 和图 ©, MAC 损失有助于缩小类内差异,而 MAID 损失有助于扩大类间差异。如 (d) 所示,当使用 MAE 损失时,嵌入具有较好的分布,类内距离紧凑,类间距离均匀较大。因此,MAE损失有助于生成更有效的检索嵌入。















 461
461











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











