









该系列仅在原课程基础上部分知识点添加个人学习笔记,或相关推导补充等。如有错误,还请批评指教。在学习了 Andrew Ng 课程的基础上,为了更方便的查阅复习,将其整理成文字。因本人一直在学习英语,所以该系列以英文为主,同时也建议读者以英文为主,中文辅助,以便后期进阶时,为学习相关领域的学术论文做铺垫。- ZJ
转载请注明作者和出处:ZJ 微信公众号-「SelfImprovementLab」
知乎:https://zhuanlan.zhihu.com/c_147249273
CSDN:http://blog.csdn.net/JUNJUN_ZHAO/article/details/79061361
1.2 Bias_Variance (偏差_方差)
(字幕来源:网易云课堂)

I’ve noticed that almost all the really good machine learning practitioners tend to be very sophisticated in understanding of Bias and Variance.Bias and Variance is one of those concepts that’s easily learned but difficult to master.Even if you think you’ve seen the basic concepts of Bias and Variance,there’s often more new ones to it than you’d expect.In the Deep Learning Error, another trend is that there’s been less discussion of what’s called the bias-variance trade-off.You might have heard this thing called the bias-variance trade-off.But in Deep Learning Error, there’s less of a trade-off,so we’d still solve the bias, we still solve the variance,but we just talk less about the bias-variance trade-off.Let’s see what this means.
我注意到 几乎所有机器学习从业人员,都期望深刻理解偏差和方差,这两个概念易学难精,即使你自认为已经理解了方差和偏差的基本概念,却总有一些意想不到的新东西出现,关于深度学习的误差问题 另一个趋势是,对偏差方差的权衡研究甚浅,大家可能听说过这个概念,但深度学习的误差很少权衡二者,我们总是分别考虑偏差和方差,却很少谈及偏差方差的权衡问题,下面我们来一探究竟。
Let’s see the data set that looks like this.If you fit a straight line to the data, maybe get a logistic regression fit to that.This is not a very good fit to the data.And so this is class of a high bias,what we say that this is underfitting the data.On the opposite end,if you fit an incredibly complex classifier,maybe deep neural network, or neural network with all the hidden units,maybe you can fit the data perfectly,but that doesn’t look like a great fit either.So there’s a classifier of high variance and this is overfitting the data.And there might be some classifier in between,with a medium level of complexity, that maybe fits it correctly like that.That looks like a much more reasonable fit to the data,so we call that just right, it’s somewhere in between.So in a 2D example like this, with just two features, X-1 and X-2,you can plot the data and visualize bias and variance.In high dimensional problems,you can’t plot the data and visualize division boundary.
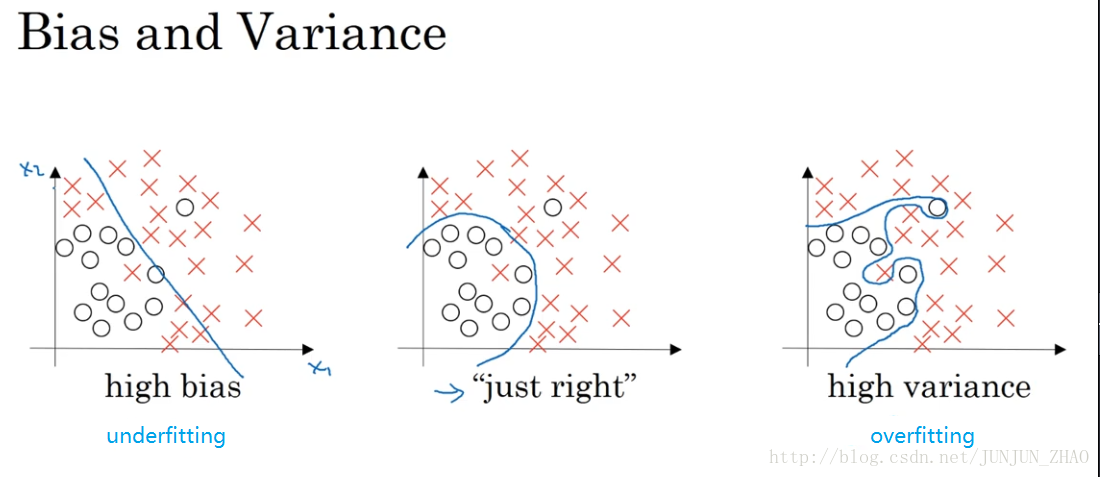
假设这就是数据集,如果给这个数据集拟合一条直线 可能得到一个逻辑回归拟合,但它并不能很好地拟合该数据集,这是偏差高的情况,我们称为“欠拟合”,相反地,如果我们拟合一个非常复杂的分类器,比如深度神经网络或含有隐藏单元的神经网络,可能就非常适用于这个数据集,但是这看起来也不是一种很好的拟合方式,分类器偏差较高 数据过度拟合,在两者之间 可能还有一些像图中这样的,复杂程度适中 数据拟合适度的分类器,这个数据拟合看起来更加合理,我们称之为“适度拟合” 是介于过拟合和欠拟合中间的一类,在这样一个只有 x1 和 x2 两个特征的二维数据集中,我们可以绘制数据 将偏差和方差可视化,在多维空间数据中,绘制数据和可视化分割边界无法实现。
Instead, there are couple of different metrics,that we’ll look at to try to understand bias and variance.So continuing our example of cat picture classification,where that’s a positive example and that’s a negative example,the two key numbers to look at to understand bias and variance will be the train set error and the dev set or the development set error.So for the sake of argument.let’s say that you’re recognizing cats in pictures is something that people can do nearly perfectly, right?So let’s say, your training set error is 1% and your dev set error is for the sake of argument.let’s say is 11%.So in this example, you’re doing very well on the training set,but you’re doing relatively poorly on the development set.So this looks like you might have overfit the training set,that somehow you’re not generalizing well, to this whole cross-validation set in the development set.And so if you have an example like this,we would say this has high variance.So by looking at the training set error and the development set error,you would be able to render a diagnosis of your algorithm having high variance.Now, let’s say, that you measure your training set and your dev set error and you get a different result.

但我们可以通过几个指标,来研究偏差和方差,我们沿用猫咪图片分类这个例子,这张是猫咪图片 这张不是,理解偏差和方差的两个关键数据是,训练集误差和验证集误差,为方便论证,假设我们可以辨别图片中的小猫,我们用肉眼识别几乎是不会出错的,假定训练集错误率是 1%,为方便论证,假设验证集错误率是 11%,可以看出 训练集设置得非常好,而验证集设置相对较差,我们可能过度拟合了训练集,某种程度上 验证集并没有充分利用交叉验证集的作用,像这种情况,我们称之为“高偏差”,通过查看训练集误差和验证集误差,我们便可以诊断算法是否具有高偏差,也就是说 衡量训练集和验证集误差,得出不同结论。
Let’s say, that your training set error is 15%.I’m writing your training set error in the top row,and your dev set error is 16%.In this case, assuming that humans achieve roughly 0% error,that humans can look at these pictures and just tell if it’s cat or not,then it looks like the algorithm is not even doing very well on the training set.So if it’s not even fitting the training data seam that well,then this is underfitting the data.And so this algorithm has high bias.But in contrast, this actually generalizing at a reasonable level to the dev set,whereas performance in the dev set is only 1% worse than performance in the training set.So this algorithm has a problem of high bias,because it was not even fitting the training set.Well, this is similar to the left most plots we had on the previous slide.

假设训练集错误率是 15%,我把训练集错误率写在首行,验证集错误率是 16%,假设该案例中人的错误率几乎为 0%,人们浏览这些图片 分辨出是不是猫,算法并没有在训练集中得到很好训练,如果训练数据的拟合度不高,就是数据欠拟合,就可以说这种算法偏差比较高,相反 它对于验证集产生的结果却是合理的,验证集中的错误率只比训练集的多了 1%,所以这种算法偏差高,因为它甚至不能拟合训练集,这与上一张幻灯片中最左边的图片相似。
Now, here’s another example.Let’s say that you have 15% training set error,so that’s pretty high bias,but when you evaluate to the dev set, it does even worse,maybe it does 30%.In this case, I would diagnose this algorithm as having high bias,because it’s not doing that well on the training set, and high variance.So this has really the worst of both worlds.And one last example,if you have 0.5 training set error, and 1% dev set error,then maybe our users are quite happy,that you have a cat classifier with only 1%, than just we have low bias and low variance.One subtlety, that I’ll just briefly mention that we’ll leave to a later video to discuss in detail is that this analysis is predicated on the assumption,that human level performance gets nearly 0% error or more generally, that the optimal error, sometimes called base error,so the base in optimal error is nearly 0%.I don’t want to go into detail on this in this particular video,but it turns out that if the optimal error or the base error were much higher, say,it were 15%, then if you look at this classifier 15% is actually perfectly reasonable for training set,and you wouldn’t see it as high bias and also a pretty low variance.

再举一个例子,训练集错误率是 15%,偏差相当高,但是 验证集的评估结果更糟糕,错误率达到 30%,这种情况下 我会认为这种算法偏差高,因为它在训练集上结果不理想 方差也很高,这是方差偏差都很糟糕的情况,再看最后一个例子,训练集错误率是 0.5% 验证集错误率是 1%,用户看到这样的结果会很开心,猫咪分类器只有 1% 的错误率 偏差和方差都很低,有一点我先在这儿简单提一下,具体的留到后面课程里讲,这些分析都是基于假设预测的,假设人眼辨别的错误率接近 0%,一般来说 最优误差也被称为基本误差,所以 最优误差接近 0%,我就不在这里细讲了,如果最优误差或基本误差非常高,比如 15% 我们再看看这个分类器,15% 的错误率对训练集来说也是非常合理的,偏差不高 方差也非常低。
So the case of how to analyze bias and variance,when no classifier can do very well, for example,if you have really blurry images,so that even a human or just no system could possibly do very well,then maybe base error is much higher,and then there are some details of how this analysis will change.But leaving aside this subtlety for now,the takeaway is that by looking at your training set error,you can get a sense of how well you are fitting, at least the training data,and so that tells you if you have a bias problem.And then looking at how much higher your error goes,when you go from the training set to the dev set,that should give you a sense of how bad is the variance problem,so you’ll be doing a good job generalizing from a training set to the dev set,that gives you sense of your variance.All this is under the assumption that the base error is quite small and that your training and your dev sets are drawn from the same distribution.If those assumptions are violated,there’s a more sophisticated analysis you could do,which we’ll talk about in the later video.
当所有分类器都不适用时,如何分析偏差和方差呢,比如 图片很模糊,即使是人眼 或者没有系统可以准确无误地识别图片,这种情况下 基本误差会更高,那么分析过程就要做些改变了,我们暂时先不讨论这些细微差别,重点是通过查看训练集误差,我们可以判断数据拟合情况 至少对于训练数据是这样,可以判断是否有偏差问题,然后查看错误率有多高,当完成训练集训练 开始验证集验证时,我们可以判断方差是否过高,从训练集到验证集的这个过程中,我们可以判断方差是否过高,以上分析的前提都是假设基本误差很小,训练集和验证集数据来自相同分布,如果没有这些假设作为前提,分析过程更更加复杂,我们将会在稍后课程里讨论。
Now, on the previous slide,you saw what high bias, high variance looks like and I guess you have the sense of what it a good class can look like.What does high bias and high variance looks like?This is kind of the worst of both worlds.So you remember, we said that a classifier like this,then your classifier has high bias,because it underfits the data.So this would be a classifier that is mostly linear and therefore underfits the data,we’re drawing this is purple.But if somehow your classifier does some weird things,then it is actually overfitting parts of the data as well.So the classifier that I drew in purple, has both high bias and high variance.Where it has high bias,because by being a mostly linear classifier is just not fitting.You know, this quadratic line shape that well,but by having too much flexibility in the middle,it somehow gets this example, and this example overfits those two examples as well.So this classifier kind of has high bias, because it was mostly linear,but you need maybe a curve function or quadratic function,and it has high variance,because it had too much flexibility to fit those two mislabel,or those live examples in the middle as well.In case this seems contrived, well,this example is a little bit contrived in two dimensions,but with very high dimensional inputs,you actually do get things with high bias in some regions and high variance in some regions,and so it is possible to get classifiers like this in high dimensional inputs that seem less contrived.
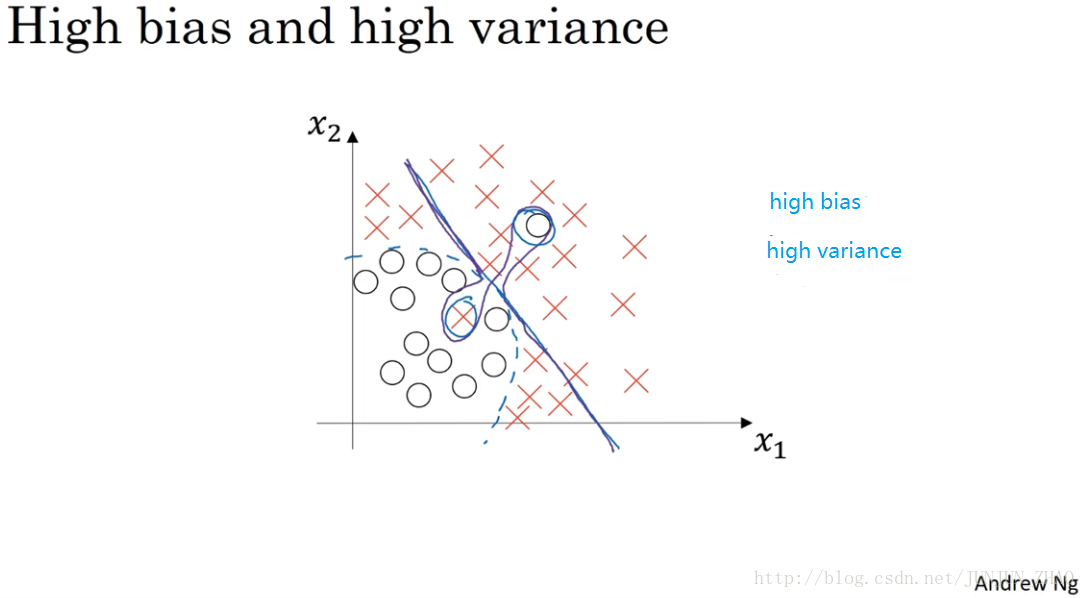
上一张幻灯片,我们讲了高偏差和高方差的情况,大家应该对优质分类器有了一定的认识,偏差和方差都高是什么样子呢,这种情况对于两个衡量标准来说都是非常糟糕的,我们之前讲过 这样的分类器,会产生高偏差,因为它的数据拟合低,像这种接近线性的分类器 数据拟合度低,我用紫色线画出,但如果我们稍微改变一下分类器,它会过度拟合部分数据,用紫色线画出的分类器具有高偏差和高方差,偏差高是因为,它几乎是一条线性分类器 并未拟合数据,这种二次曲线能够很好地拟合数据,这条曲线中间部分灵活性非常高,却过度拟合了这两个样本。这类分类器偏差很高 因为它几乎是线性的,而采用曲线函数或二次元函数,会产生高偏差,因为它曲线灵活性太高 以致拟合了这两个错误样本,和中间这些活跃数据,这看起来有些不自然,从两个维度上看都不太自然,但对于高维数据,有些数据区域偏差高 有些数据区域方差高,所以在高维数据中采用这种分类器看起来就不会这么牵强了。
So to summarize,you’ve seen how by looking at your algorithm’s error on the training set and your algorithm’s error on the dev set, you can try to diagnose,whether it has problems of high bias or high variance,or maybe both, or maybe neither.And depending on whether your algorithm suffers from bias or variance,it turns out that there are different things you could try.So in the next video, I want to present to you,what I call a basic recipe for Machine Learning,that lets you more systematically try to improve your algorithm,depending on whether it has high bias or high variance issues.So let’s go on to the next video.
总结一下,今天我们讲了如何通过分析训练集训练算法产生的误差,和验证集验证算法产生的误差,来诊断算法是否存在高偏差或高方差,是否两个值都高 或者两个值都不高,根据算法偏差和方差的具体情况,决定接下来你要做的工作,下节课 我会根据,算法偏差和方差的高低情况,讲解一些机器学习的基本方法,帮助大家更系统地优化算法,我们下节课见。
重点总结:
偏差、方差
对于下图中两个类别分类边界的分割:
从图中我们可以看出,在欠拟合(underfitting)的情况下,出现高偏差(high bias)的情况;在过拟合(overfitting)的情况下,出现高方差(high variance)的情况。
在 bias-variance trade off 的角度来讲,我们利用训练集对模型进行训练就是为了使得模型在 train 集上使 bias 最小化,避免出现underfitting 的情况;
但是如果模型设置的太复杂,虽然在 train 集上 bias 的值非常小,模型甚至可以将所有的数据点正确分类,但是当将训练好的模型应用在dev 集上的时候,却出现了较高的错误率。这是因为模型设置的太复杂则没有排除一些 train 集数据中的噪声,使得模型出现 overfitting 的情况,在dev 集上出现高 variance 的现象。
所以对于 bias 和 variance 的权衡问题,对于模型来说是一个十分重要的问题。
例子:
几种不同的情况:

以上为在人眼判别误差在 0% 的情况下,该最优误差通常也称为“贝叶斯误差”,如果“贝叶斯误差”大约为 15%,那么图中第二种情况就是一种比较好的情况。
High bias and high variance 的情况
上图中第三种 bias 和 variance 的情况出现的可能如下:
没有找到边界线,但却在部分数据点上出现了过拟合,则会导致这种高偏差和高方差的情况。
虽然在这里二维的情况下可能看起来较为奇怪,出现的可能性比较低;但是在高维的情况下,出现这种情况就成为可能。
参考文献:
[1]. 大树先生.吴恩达Coursera深度学习课程 DeepLearning.ai 提炼笔记(2-1)– 深度学习的实践方面
PS: 欢迎扫码关注公众号:「SelfImprovementLab」!专注「深度学习」,「机器学习」,「人工智能」。以及 「早起」,「阅读」,「运动」,「英语 」「其他」不定期建群 打卡互助活动。
















 1438
1438

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









