







目录
前言
本文基于requests库爬取的奥运会相关数据,利用pandas库对数据进行处理之后,最后介绍了如何利用pyecharts库制作可视化大屏。
一、数据爬取
import requests
import pandas as pd
from pprint import pprint导入相关库
requests库用于发起网页请求,获取网页中的源代码;
pandas库用于存储和读取获取到的信息;
pprint库是漂亮的打印,对于json格式的数据,能够很好的展示结构,方便我们解析;
url = 'https://app-sc.miguvideo.com/vms-livedata/olympic-medal/total-table/15/110000004609'
data1 = requests.get(url).json()
# pprint(data1)这里利用三行代码就可以获取到网页的源代码,利用pprint库,可以清晰的展示json结构,对于我们解析数据很有帮助。
df1 = pd.DataFrame()
for info in data1['body']['allMedalData']:
name = info['countryName']
name_id = info['countryId']
rank = info['rank']
gold = info['goldMedalNum']
silver = info['silverMedalNum']
bronze = info['bronzeMedalNum']
total = info['totalMedalNum']
# 组织数据
orangized_data = [[name,name_id,rank,gold,silver,bronze,total]]
# 然后追加df
df1 = df1.append(orangized_data)
df1.columns = ['名称', 'ID', '排名', '金牌', '银牌', '铜牌', '奖牌总数']
df1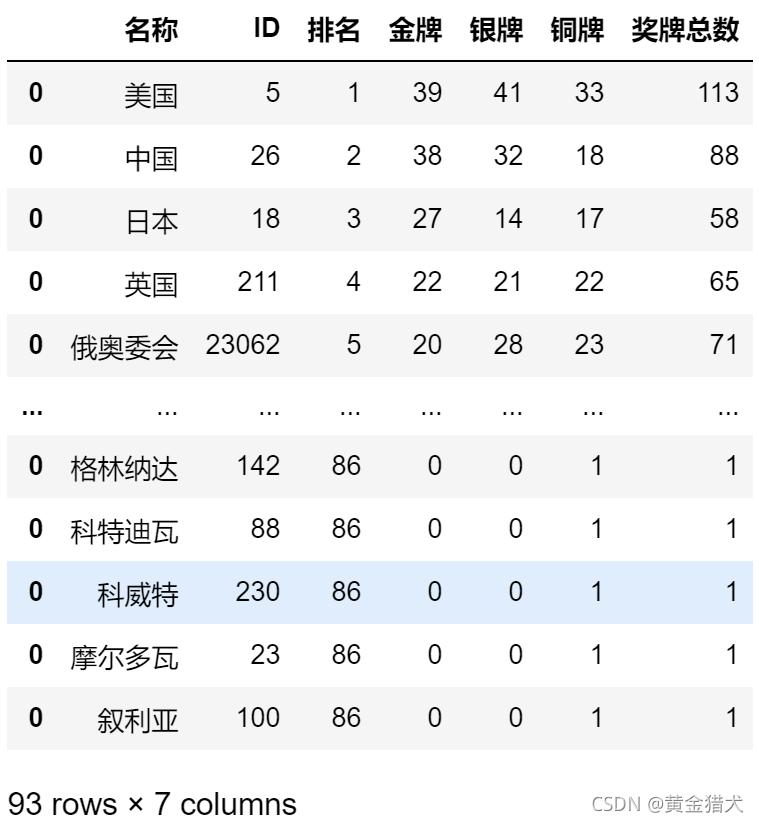
这里利用pandas库对爬取的数据进行处理,转变成结构更清楚的数据框结构。
url = 'https://app-sc.miguvideo.com/vms-livedata/olympic-medal/detail-total/15/110000004609'
data2 = requests.get(url).json()
#pprint(data2)
df2 = pd.DataFrame()
for info in data2['body']['medalTableDetail']:
english_name = info['countryName']
name_id = info['countryId']
award_time = info['awardTime']
item_name = info['bigItemName']
sports_name = info['sportsName']
medal_type = info['medalType']
# 组织数据
orangized_data = [[english_name,name_id,award_time,item_name,sports_name,medal_type]]
# 然后追加df
df2 = df2.append(orangized_data)
df2.columns = ['英文缩写', 'ID', '获奖时间', '项目名', '运动员', '金牌类型']
df2
对于另外一个网页,我们采取同样的方式对数据进行爬取和处理。
二、数据预处理
由于使用pyecharts绘制世界地图时,名称必须是英文的,所以我们需要将这里的中文名称映射为英文名称。 我们要做的就是将它与表格中的数据,做个映射转换。先把它转换为一个Excel文件,方便我们以后直接使用。
with open("D:/和鲸数据/数据可视化大屏!绘制全流程!/国家名中英文对照表.txt","r",encoding="utf-8") as f:
x = f.read()
df3 = pd.DataFrame()
for i in x.split("\n"):
x = i.split(":")[0].strip()
y = i.split(":")[1].strip 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 4万+
4万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









