






Transformer
网络结构
Transformer也是由编码器和解码器组成的。

每一层Encoder编码器都由很多层构成的,编码器内又是self-attention和前馈网络构成的。Self-attention是用来做加权平均,前馈网络用来组合。

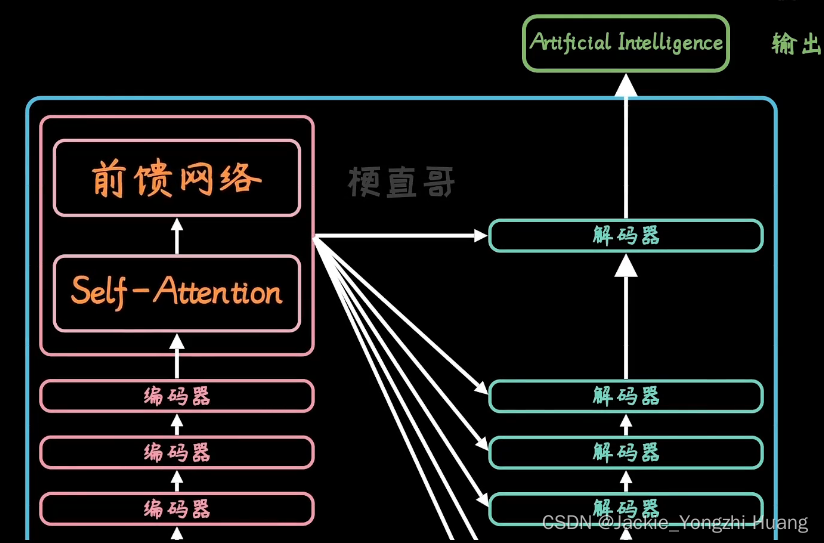
但是decoder有点不同,多了一层Encoder-Decoder Attention。这一层的作用是关注全局,也就是不仅仅要关注编码,还要关注解码过程。在翻译中,也就是不仅仅关注翻译后的内容,还要关注翻译前的上下文内容。

Self-attention又可以拆解成多个部分,就变成了Multi-Head Attention。

最终得到了,整个网络结构。

数据流程
首先,把单词做统一长度的向量化,再嵌入位置信息,这样方便单词的统一,最终是同一长度(比如都是512位)。

然后,再通过一个编码器,生成下一个编码。这里的Self-attention就是个零件(比如单词)自查表,它的作用就是通过权重标明相互之间的关系并且嵌入上下文信息。

具体的方法是,每个向量先嵌入位置信息,

再乘以三个训练好的向量Q、K和V矩阵。
(我感觉,看上去像是一个数据库的查询操作)Q就是我提出了一个查询语句,K就是查询时候键值,两个相乘就得到了一个特征向量。V就像是数据库里面的值,所以,就像利用前面计算得到的特征向量分别计算V的相关性。

用一个单词的K向量和所有单纯的Q向量相乘,得到的权重就是Attention。
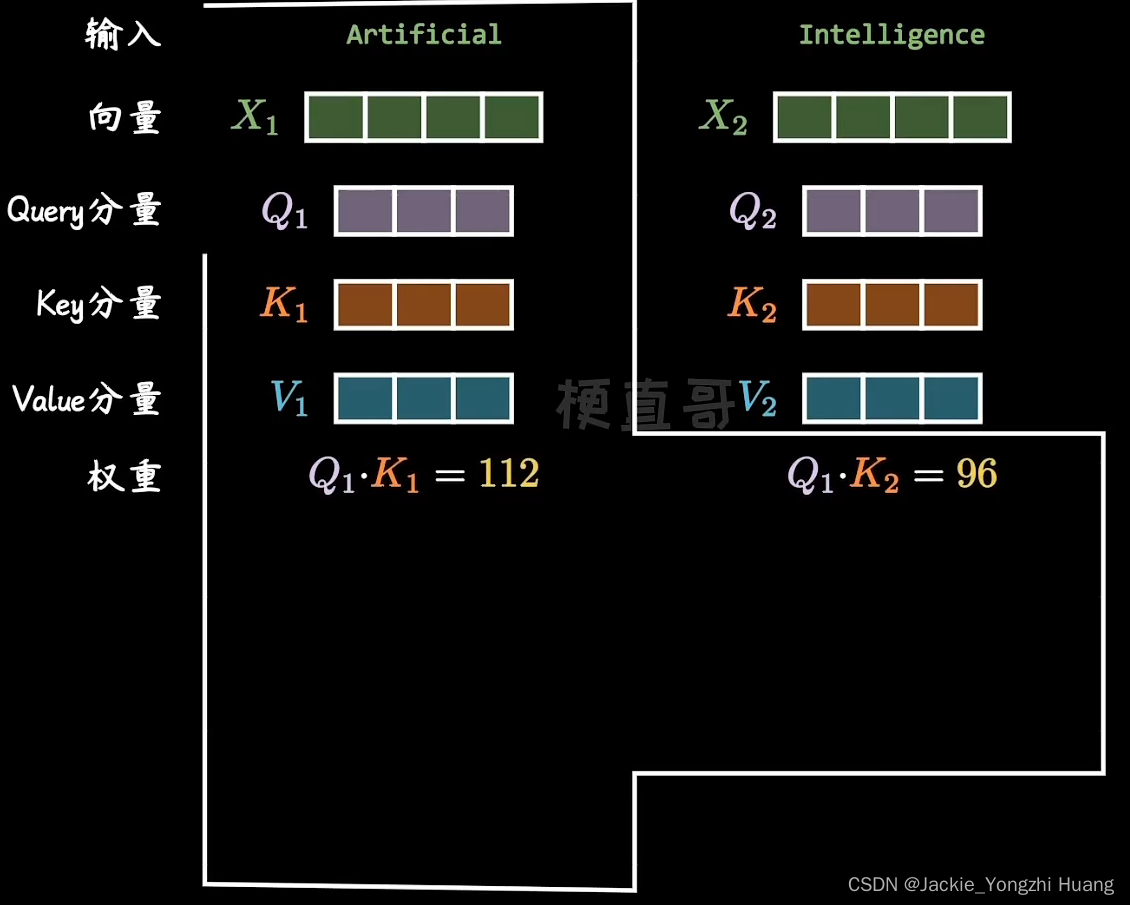
然后,通过归一化后,利用softmax函数过滤掉不相干的单词。再乘以V向量,加权求和。最终得到输出向量。
所有的步骤,就只需要知道,反正最后得到了单词的权重计算。

用矩阵描述就是,先把X乘以三个矩阵。

然后,利用得到的Q和K,计算Z矩阵。

如果是Multihead-Attention,就会使用多个不同权重的矩阵,计算多次,得到多个Z。Multihead的作用是,消除QKV初始值的影响。那就像是八个不同的人做,更能够排除意外的影响。

最后通过一个加权平均,合成一个Z矩阵。

梳理
变形金刚要变形,从小车到机器人。
- 编码器一开始,先拆成零件。

- Self-attention就是给出一个变形说明书,说明零件之间的关系和权重。


- 左边编码把输入转换成了降维的向量和零件说明书,K和V;右边解码,还需要看两个东西,一个自己的拆解说明书和与其他零件的项目关系;一个零件一个零件的组装。
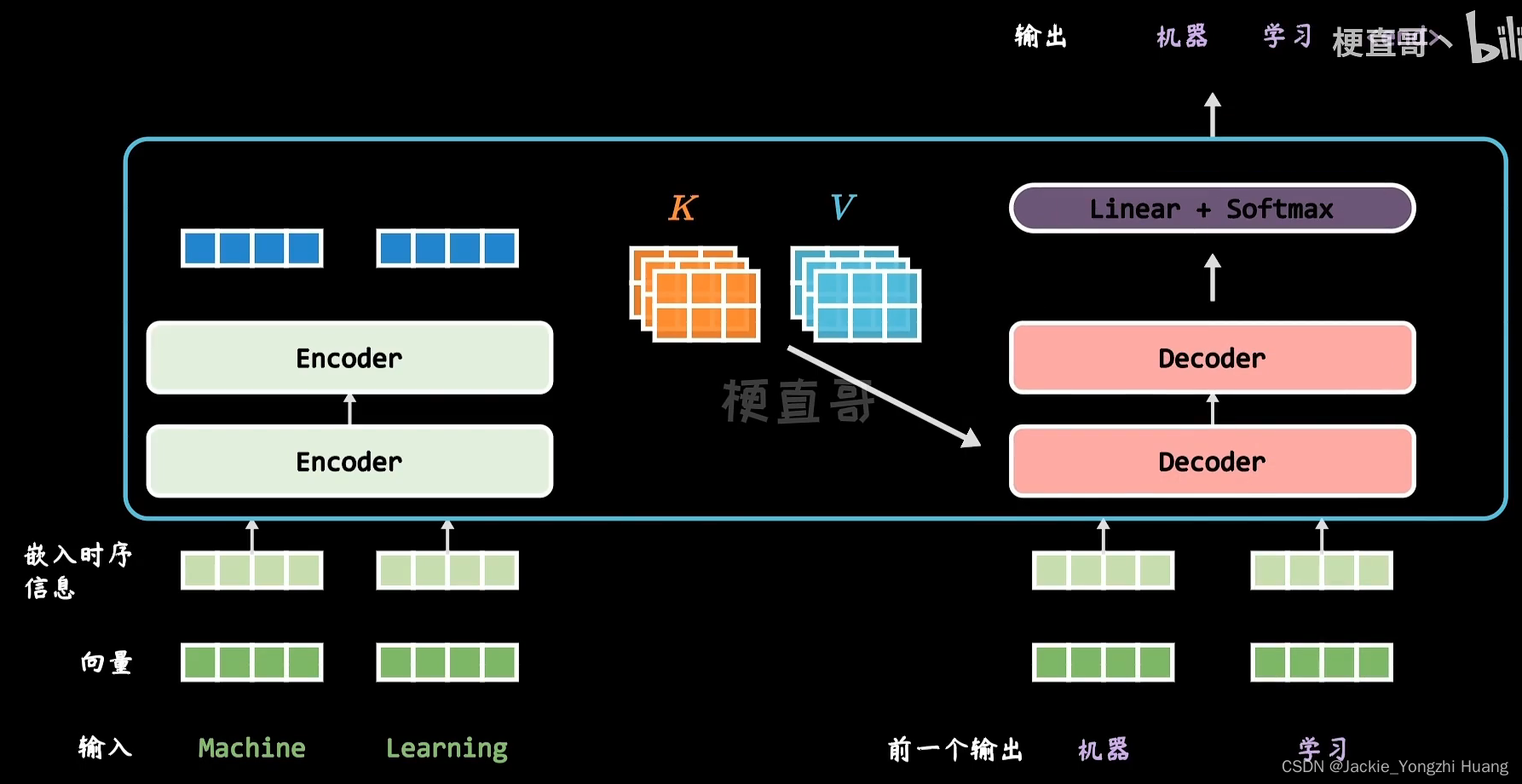
- 最后,线性层把向量投影到一个很长的序列中,包含所有单词的序列。
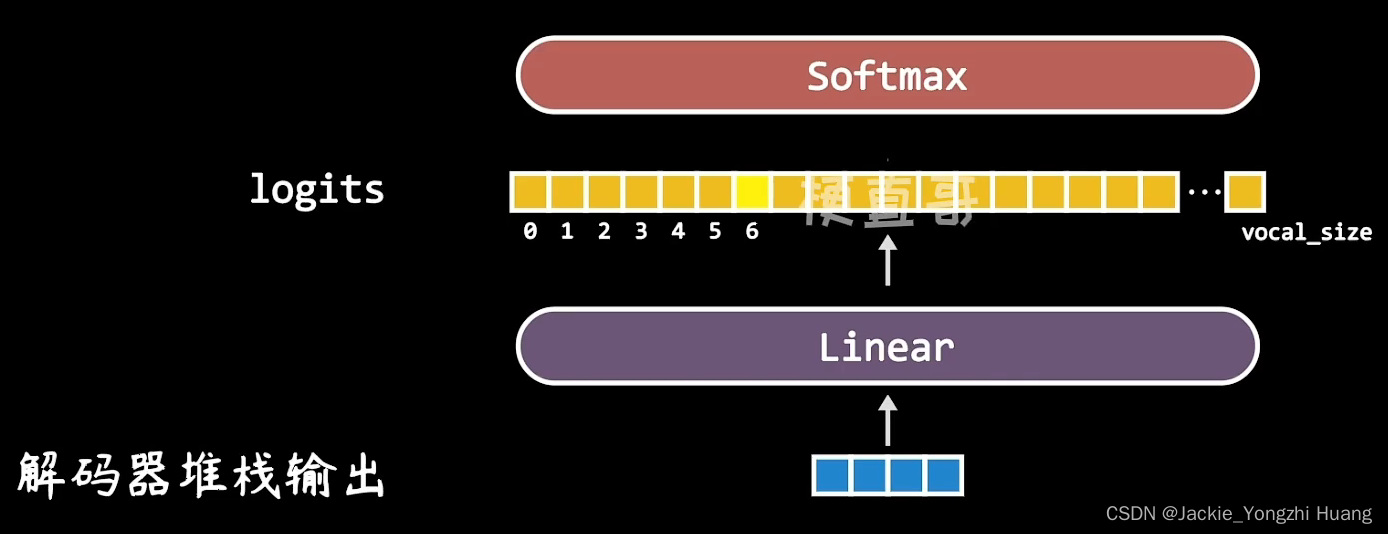
- softmax做归一化,得到一个最大的概率。

参考资料:
【【Transformer模型】曼妙动画轻松学,形象比喻贼好记】 https://www.bilibili.com/video/BV1MY41137AK/?share_source=copy_web&vd_source=91d02e058149c97e25d239fb93ebef76















 3074
3074











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









