





论文地址:https://arxiv.org/abs/2407.01219
摘要
检索增强生成(RAG)技术已被证明可以有效地整合最新信息、减轻幻觉和提高响应质量,特别是在专业领域。 尽管已经提出了许多 RAG 方法来通过依赖于查询的检索来增强大型语言模型,但这些方法仍然存在复杂的实现和较长的响应时间。 通常,RAG 工作流程涉及多个处理步骤,每个处理步骤都可以通过多种方式执行。 在这里,我们研究现有的 RAG 方法及其潜在组合,以确定最佳的 RAG 实践。 通过大量的实验,我们提出了几种平衡性能和效率的 RAG 部署策略。 此外,我们证明多模态检索技术可以显着增强有关视觉输入的问答能力,并使用“检索即生成”策略加速多模态内容的生成。 资源可在 https://github.com/FudanDNN-NLP/RAG 获取。
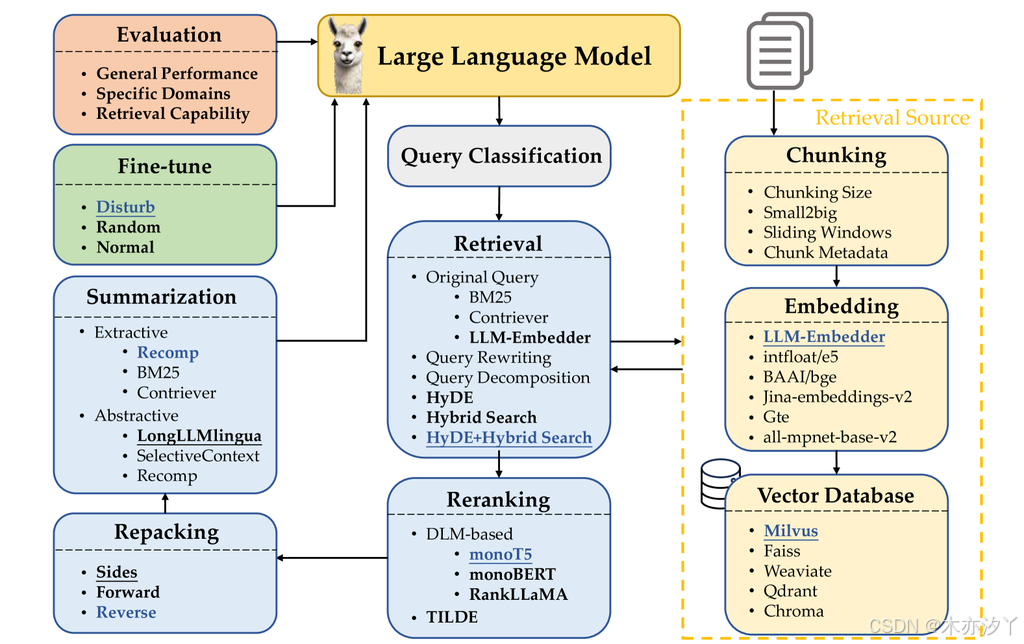
本研究调查了每个组件的贡献,并通过广泛的实验提供了对最佳 RAG 实践的见解。 每个组件考虑的可选方法以粗体字体表示,而方法下划线表示各个模块的默认选择。 以蓝色字体表示的方法表示根据经验确定的性能最佳的选择。
1、简介
生成式大型语言模型很容易产生过时的信息或捏造事实,尽管它们通过强化学习[1]或轻量级替代方案[2,3,4,5]与人类偏好保持一致。检索增强生成 (RAG) 技术通过结合预训练和基于检索的模型的优势来解决这些问题,从而为增强模型性能提供强大的框架[6]。 此外,只要提供与查询相关的文档,RAG就可以为特定组织和领域快速部署应用程序,而无需更新模型参数。
人们提出了许多 RAG 方法来通过依赖于查询的检索来增强大型语言模型 (LLM)[7,8,6]。
典型的RAG工作流程通常包含多个中间处理步骤:查询分类(确定对于给定的输入查询是否需要进行检索)、检索(高效地获取与查询相关的文档)、重新排序(根据文档与查询的相关性对检索到的文档进行排序)、重新打包(将检索到的文档组织成结构化的形式以更好地生成)、摘要(从重新打包的文档中提取关键信息用于生成响应并消除冗余)模块。实现 RAG 还需要决定如何正确地将文档分割成块、用于语义表示这些块的嵌入类型、有效存储特征表示的向量数据库的选择以及有效微调 LLM 的方法(参见图1)。
增加复杂性和挑战的是实施每个处理步骤的可变性。 例如,在检索输入查询的相关文档时,可以采用各种方法。 一种方法涉及首先重写查询并使用重写的查询来检索[9]。 或者,可以先生成对查询的伪响应,然后比较这些伪响应与后端文档之间的相似度来检索[10]。 另一种选择是直接采用嵌入模型,通常使用正负查询响应对 [11, 12] 以对比方式进行训练。 每个步骤及其组合所选择的技术都会显着影响 RAG 系统的有效性和效率。 据我们所知,还没有系统性的努力来追求 RAG 的最佳实施,特别是对于整个 RAG 工作流程。
在本研究中,我们的目标是通过广泛的实验确定 RAG 的最佳实践。 鉴于测试这些方法的所有可能组合是不可行的,我们采用三步方法来确定最佳 RAG 实践。 首先,我们比较每个 RAG 步骤(或模块)的代表性方法,并选择最多三种性能最佳的方法。 接下来,我们通过针对单个步骤一次测试一种方法来评估每种方法对整体 RAG 性能的影响,同时保持其他 RAG 模块不变。 这使我们能够根据每个步骤的贡献以及在响应生成过程中与其他模块的交互来确定每个步骤最有效的方法。 一旦为模块选择了最佳方法,就会在后续实验中使用它。 最后,我们根据经验探索了一些适合不同应用场景的有前景的组合,其中效率可能优先于性能,反之亦然。 基于这些发现,我们提出了几种平衡性能和效率的 RAG 部署策略。
这项研究的贡献有三方面:
- 通过广泛的实验,我们彻底研究了现有的 RAG 方法及其组合,以确定并推荐最佳的 RAG 实践。
- 我们引入了一个全面的评估指标框架和相应的数据集,以全面评估检索增强生成模型的性能,涵盖通用、专业(或特定领域)和 RAG 相关的能力。
- 我们证明,多模态检索技术的集成可以显着提高视觉输入的问答能力,并通过“检索即生成”策略加速多模态内容的生成。
2、相关工作
确保 ChatGPT [13] 和 LLaMA [14] 等大型语言模型 (LLM) 生成的响应的准确性至关重要。 然而,简单地扩大模型大小并不能从根本上解决幻觉问题[15, 16],尤其是在知识密集型任务和专业领域。 检索增强生成 (RAG) 通过从外部知识库检索相关文档,为 LLM [6]提供准确、实时、特定领域的上下文来应对这些挑战。 之前的工作通过查询和检索转换优化了 RAG 管道,增强了检索器性能,并对检索器和生成器进行了微调。 这些优化改进了输入查询、检索机制和生成过程之间的交互,确保响应的准确性和相关性。
2.1、查询与检索转换
有效的检索要求查询准确、清晰、详细。 即使转换为嵌入,查询和相关文档之间的语义差异也可能持续存在。 先前的工作探索了通过查询转换来增强查询信息的方法,从而提高检索性能。 例如,Query2Doc [17] 和 HyDE [10] 从原始查询生成伪文档以增强检索,而 TOC [18] 则分解查询到子查询中,聚合检索到的内容以获得最终结果。
其他研究集中于转换检索源文档。 LlamaIndex [19] 提供了一个接口来生成用于检索文档的伪查询,从而改善与真实查询的匹配。 一些作品采用对比学习来使查询和文档嵌入在语义空间中更加接近[20,12,21]。 对检索到的文档进行后处理是增强生成器输出的另一种方法,采用分层提示摘要 [22] 等技术以及使用抽象和提取压缩器 [23] 来减少上下文长度和删除冗余[24]。
2.2、检索器增强策略
文档分块和嵌入方法显着影响检索性能。 常见的分块策略将文档划分为多个块,但确定最佳块长度可能具有挑战性。 小块可能会碎片化句子,而大块可能包含不相关的上下文。 LlamaIndex [19] 优化了 Small2Big 和滑动窗口等分块方法。 检索到的块可能不相关并且数量可能很大,因此需要重新排序以过滤不相关的文档。 常见的重新排名方法采用深度语言模型,例如 BERT [25]、T5 [26] 或 LLaMA [27],这需要较慢的速度重新排序期间的推理步骤,但可以获得更好的性能。 TILDE [28, 29] 通过预先计算和存储查询项的可能性、根据它们的总和对文档进行排名来提高效率。
2.3、检索器和生成器微调
RAG 框架内的微调对于优化检索器和生成器至关重要。 一些研究侧重于微调生成器以更好地利用检索器上下文[30,31,32],确保生成的内容忠实且稳健。 其他人对检索器进行微调,以学习检索对生成器[33,34,35]有益的段落。 整体方法将 RAG 视为一个集成系统,对检索器和生成器进行微调,以提高整体性能[36,37,38],尽管复杂性和集成挑战有所增加。
多项调查广泛讨论了当前的 RAG 系统,涵盖文本生成 [7, 8]、与 LLM 集成 [6, 39]、多模式 [40] 等方面,以及人工智能生成的内容[41]。 虽然这些调查提供了对现有 RAG 方法的全面概述,但为实际实施选择适当的算法仍然具有挑战性。 在本文中,我们重点关注应用 RAG 方法的最佳实践,促进 LLM 对 RAG 的理解和应用。
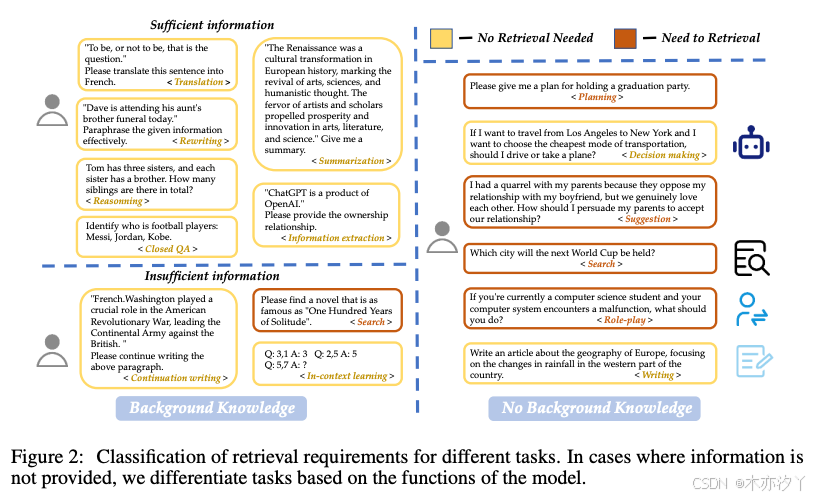
3、RAG 工作流程
在本节中,我们将详细介绍 RAG 工作流程的组件。 对于每个模块,我们都会回顾常用的方法,并为最终管道选择默认和替代方法。 章节4 将讨论最佳实践。 图1展示了每个模块的工作流程和方法。 附录A中提供了详细的实验设置,包括数据集、超参数和结果。
3.1、查询分类
由于 LLM 的固有功能,并非所有查询都需要检索增强。 虽然 RAG 可以提高信息准确性并减少幻觉,但频繁检索会增加响应时间。 因此,我们首先对查询进行分类来确定检索的必要性。 需要检索的查询通过 RAG 模块进行;其他则由 LLM 直接处理。
当需要超出模型参数的知识时,通常建议进行检索。 然而,检索的必要性因任务而异。 例如,训练到 2023 年的 LLM 可以处理“Sora was returned by OpenAI”的翻译请求,而无需检索。 相反,对同一主题的介绍请求将需要检索以提供相关信息。
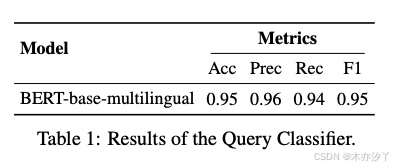
因此,我们建议按类型对任务进行分类,以确定查询是否需要检索。 我们分类根据是否提供足够的信息分为15个任务,具体任务和示例如图2所示。 对于完全基于用户给定信息的任务,我们表示为“足够”,不需要检索;否则,我们表示为“不足”,并且可能需要检索。 我们训练一个分类器来自动化这个决策过程。 实验细节参见附录A.1。 章节4 探讨了查询分类对工作流的影响,比较了有分类和没有分类的场景。
3.2、分块
将文档分成更小的片段对于提高检索精度和避免 LLM 中的长度问题至关重要。 该过程可以应用于各种粒度级别,例如标记、句子和语义级别。
-
Token 级分块很简单,但可能会分裂句子,影响检索质量。
-
语义级分块使用 LLM 来确定断点,可以保留上下文,但非常耗时。
-
句子级分块在保留文本语义与简单性和效率之间取得了平衡。
在本研究中,我们使用句子级分块,平衡简单性和语义保留。 我们从四个维度来研究分块。
3.2.1、块大小
块大小显着影响性能。 较大的块提供更多的上下文,增强理解,但会增加处理时间。 较小的块可以提高检索回忆并减少时间,但可能缺乏足够的上下文。
寻找最佳块大小涉及一些指标(例如忠实性和相关性)之间的平衡。 忠实度衡量响应是否是幻觉或与检索到的文本匹配。
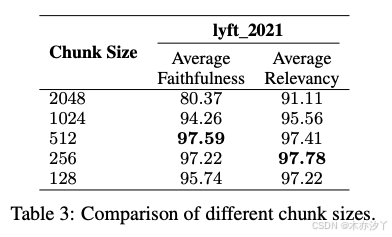
相关性衡量检索到的文本和响应是否与查询匹配。 我们使用 LlamaIndex [43] 的评估模块来计算上述指标。 对于嵌入,我们使用 text-embedding-ada-002模型,支持长输入长度。 我们选择zephyr-7b-alpha 和 gpt-3.5-turbo分别作为生成模型和评估模型。 块重叠的大小是 20 个 Token 。 文档前六十页 lyft_2021 用作语料库,然后提示 LLM 根据所选语料库生成大约170个查询。 不同块大小的影响如表3所示。
3.2.2、分块技术
small2big和滑动窗口等先进技术通过组织块块关系来提高检索质量。 小尺寸的块用于匹配查询,并且返回包含小块以及上下文信息的较大块。
为了证明高级分块技术的有效性,我们使用 LLM-Embedder [20] 模型作为嵌入模型。 较小的块大小为 175 个标记,较大的块大小为 512 个标记,块重叠为 20 个标记。 small2big和滑动窗口等技术通过维护上下文并确保检索到相关信息来提高检索质量。 详细结果如表4所示。

3.2.3、嵌入模型选择
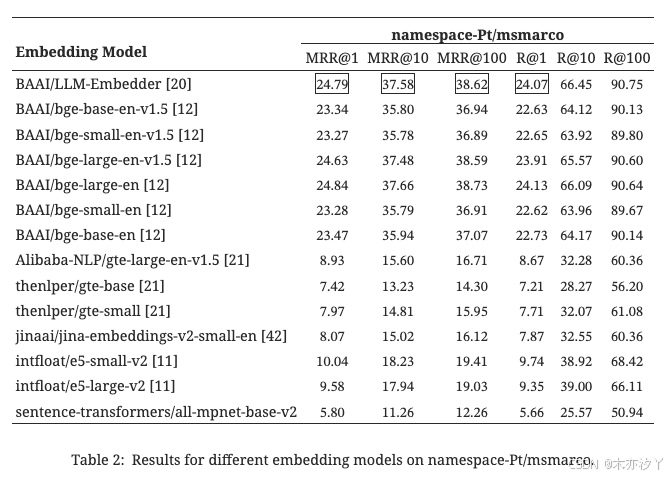
选择正确的嵌入模型对于查询和块块的有效语义匹配至关重要。 我们使用FlagEmbedding作为评估模块,该模块使用数据集namespace-Pt/msmarco作为查询和数据集namespace-Pt/msmarco-corpus作为语料库来选择合适的开源嵌入模型。如表2所示,LLM-Embedder[20]与BAAI/bge-large-en[12]取得了可比的结果,然而,前者的尺寸是后者的三分之一。因此,我们选择了LLM-Embedder[20],因为它在性能和尺寸之间取得了平衡。
3.2.4、元数据添加
使用标题、关键字和假设问题等元数据增强块可以改进检索,提供更多方法来后处理检索到的文本,并帮助 LLM 更好地理解检索到的信息。 关于元数据包含的详细研究将在未来的工作中进行。
3.3、向量数据库
向量数据库存储嵌入向量及其元数据,从而能够通过各种索引和近似最近邻 (ANN) 方法有效检索与查询相关的文档。
为了为我们的研究选择合适的向量数据库,我们根据四个关键标准评估了多个选项:多种索引类型、十亿级向量支持、混合搜索和云原生能力。 选择这些标准是因为它们对现代基于云的基础设施中的灵活性、可扩展性和易于部署的影响。 多种索引类型提供了根据不同数据特征和用例优化搜索的灵活性。 十亿级向量支持对于处理 LLM 应用程序中的大型数据集至关重要。 混合搜索将向量搜索与传统关键词搜索相结合,提高检索准确率。 最后,云原生功能可确保云环境中的无缝集成、可扩展性和管理。 表5详细比较了五个开源向量数据库:Weaviate、Faiss、Chroma、Qdrant 和 Milvus。

我们的评估表明,Milvus 在评估的数据库中脱颖而出,成为最全面的解决方案,满足所有基本标准并优于其他开源选项。
3.4、检索方法
给定用户查询,检索模块根据查询与文档之间的相似度从预先构建的语料库中选择top-k相关文档。 然后,生成模型使用这些文档来制定对查询的适当响应。 然而,由于表达不佳和缺乏语义信息[6],原始查询往往表现不佳,对检索过程产生负面影响。 为了解决这些问题,我们使用 3.2 节中推荐的 LLM-Embedder 作为查询和文档编码器评估了三种查询转换方法:
- 查询重写:查询重写可细化查询以更好地匹配相关文档。 受重写-检索-读取框架[9]的启发,我们提示 LLM 重写查询以提高性能。
- 查询分解:这种方法涉及根据原始查询派生的子问题来检索文档,这对于理解和处理来说更加复杂。
- 伪文档生成:这种方法根据用户查询生成假设文档,并使用假设答案的嵌入来检索相似文档。 一个值得注意的工具是 HyDE [10]。
最近的研究,例如[44],表明将基于词汇的搜索与向量搜索相结合可以显着提高性能。 在本研究中,我们使用 BM25 进行稀疏检索,并使用 Contriever [45](一种无监督对比编码器)进行密集检索,作为基于 Thakur 等人 [46] 的两个稳健基线。
3.4.1、不同检索方法的结果
我们评估了不同搜索方法在 TREC DL 2019 和 2020 文章排名数据集上的性能。 表6中的结果表明,监督方法明显优于无监督方法。 结合 HyDE 和混合搜索,LLM-Embedder 取得了最高分。 然而,查询重写和查询分解并没有有效地提高检索性能。 考虑到最佳性能和可容忍的延迟,我们建议使用使用 HyDE 的混合搜索作为默认检索方法。 考虑到效率,混合搜索结合了稀疏检索(BM25)和密集检索(原始嵌入),并以相对较低的延迟实现了显着的性能。

每种方法的最佳结果均以粗体显示,第二个则用下划线显示。
3.4.2、具有不同文档和查询串联的 HyDE
表 7 显示了不同串联策略对使用 HyDE 的假设文档和查询的影响。 将多个伪文档与原始查询连接起来可以显着提高检索性能,但代价是增加延迟,这表明检索有效性和效率之间需要权衡。 然而,不加选择地增加假设文档的数量并不会产生显着的好处,并且会大大增加延迟,这表明使用单个假设文档就足够了。

3.4.3、稀疏检索上不同权重的混合搜索
表8展示了混合搜索中不同α值的影响,其中α控制稀疏检索和密集检索组件之间的权重。 相关性得分计算如下:
其中 、
分别是稀疏检索和密集检索的归一化相关性得分,
是总检索得分。
我们评估了五个不同的 α 值以确定它们对性能的影响。 结果表明,α值为0.3时性能最佳,说明适当调整α可以在一定程度上提高检索效果。 因此,我们选择α=0.3进行检索和主要实验。 其他实施细节参见附录A.2。

3.5、重新排序方法
初始检索后,采用重新排序阶段来增强检索到的文档的相关性,确保最相关的信息出现在列表的顶部。 此阶段使用更精确和更耗时的方法来有效地重新排序文档,增加查询与排名靠前的文档之间的相似性。
我们在重新排名模块中考虑两种方法:DLM 重排序(利用分类)和TILDE 重排序(重点关注查询可能性)。 这些方法分别优先考虑性能和效率。
- DLM 重排序:此方法利用深度语言模型 (DLM) [25,26,27] 进行重新排名。 这些模型经过微调,可将文档与查询的相关性分类为“真”或“假”。 在微调期间,模型使用连接的查询和文档输入进行训练,并按相关性进行标记。 在推理时,文档根据“真实”标记的概率进行排名。
- TILDE 重排序:TILDE [28, 29] 通过预测模型词汇表中的标记概率来独立计算每个查询项的可能性。 通过对查询标记的预先计算的日志概率求和来对文档进行评分,从而允许在推理时快速重新排名。 TILDEv2 通过仅索引文档存在的标记、使用 NCE 损失和扩展文档来改进这一点,从而提高效率并减少索引大小。
我们的实验是在 MS MARCO Passage 排名数据集 [47] 上进行的,这是一个用于机器阅读理解的大规模数据集。 我们使用模型 monoT5、monoBERT、RankLLaMA 和 TILDEv2,遵循并修改 PyGaggle [26] 和 TILDE [28] 提供的实现。 重排序结果如表9所示。 我们推荐 monoT5 作为平衡性能和效率的综合方法。 RankLLaMA 适合实现最佳性能,而 TILDEv2 适合在固定集合上获得最快体验。 有关实验设置和结果的详细信息请参见附录A.3。

对于每个查询,BM25检索到的前1000个候选段落都会重新排名。延迟以每次查询的秒数来衡量。
3.6、文档重新打包
后续流程的性能(例如LLM回复生成)可能会受到所提供的订单文件的影响。 为了解决这个问题,我们在重新排序后的工作流程中加入了一个紧凑的重新打包模块,具有三种重新打包方法:“forward”,“reverse”和“sides” 。 “forward”方法通过重新排序阶段的相关性分数降序来重新打包文档,而“reverse”方法则按升序排列它们。 受Liu等人[48]的启发,他们认为当相关信息被放置在输入的头部或尾部时,可以实现最佳性能,我们还包括一个“sides”选项。
由于重新打包方法主要影响后续模块,因此我们在第4节通过与其他模块的组合测试来选择最佳的重新打包方法。 在本节中,我们选择“sides”方法作为默认的重新打包方法。
3.7、总结
检索结果可能包含冗余或不必要的信息,可能会阻止 LLM 生成准确的响应。 此外,长提示会减慢推理过程。 因此,总结检索到的文档的有效方法在 RAG 管道中至关重要。
总结任务可以是提取性或抽象性。 提取方法将文本分割成句子,然后根据重要性对其进行评分和排名。 抽象压缩器合成来自多个文档的信息以重新措辞并生成有凝聚力的摘要。 这些任务可以是基于查询的或非基于查询的。 在本文中,当 RAG 检索与查询相关的信息时,我们只关注基于查询的方法。
- Recomp: Recomp [23] 具有提取和抽象的压缩器。 提取压缩器选择有用的句子,而抽象压缩器则合成来自多个文档的信息。
- LongLLMLingua: LongLLMLingua [49] 通过关注与查询相关的关键信息来改进LLMLingua。
- Selective Context :选择性上下文通过识别和删除输入上下文中的冗余信息来提高 LLM 效率。 它使用基本因果语言模型计算的自信息来评估词汇单元的信息量。 该方法是非基于查询的,允许在基于查询和非基于查询的方法之间进行比较。
我们在三个基准数据集上评估这些方法:NQ、TriviaQA 和 HotpotQA。 不同汇总方法的对比结果如表10所示。 我们推荐Recomp,因为它具有出色的性能。 LongLLMLingua 表现不佳,但表现出更好的泛化能力,因为它没有在这些实验数据集上进行训练。 因此,我们将其视为一种替代方法。 附录A.4中提供了关于非基于查询的方法的其他实现细节和讨论。
3.8、生成器微调
在本节中,我们重点关注对生成器的微调,同时将检索器的微调留给未来的探索。 我们的目标是研究微调的影响,特别是相关或不相关上下文对生成器性能的影响。
形式上,我们将 x 表示为输入到 RAG 系统的查询,将 𝒟 表示为该输入的上下文。 生成器的微调损失是真实输出y的负对数似然。
为了探索微调的影响,特别是相关和不相关的上下文,我们将 定义为与查询相关的上下文,将
定义为随机检索的上下文。 我们通过改变 𝒟 的组成来训练模型,如下所示:
:增强上下文由查询相关文档组成,表示为
。
:上下文包含一个随机采样的文档,表示为
。
:增强上下文包括相关文档和随机选择的文档,表示为
。
:增强上下文由查询相关文档的两个副本组成,表示为
。
我们将未微调的基本 LM 生成器表示为,将相应 𝒟 下微调的模型表示为
。 我们在几个 QA 和阅读理解数据集上微调了我们的模型。

由于 QA 任务答案相对较短,因此使用真实覆盖率作为我们的评估指标。 我们选择 Llama-2-7B [50] 作为基本模型。 与训练类似,我们使用、
、
和
评估验证集上的所有训练模型,其中
表示不检索的推理。 图3展示了我们的主要结果。 使用相关文档和随机文档 (
) 混合训练的模型在提供黄金上下文或混合上下文时表现最佳。 这表明在训练期间混合相关上下文和随机上下文可以增强生成器对不相关信息的鲁棒性,同时确保有效利用相关上下文。 因此,我们将训练过程中使用少量相关且随机选择的文档进行增强的做法认定为最佳方法。 详细的数据集信息、超参数和实验结果可以在附录A.5中找到。
4、搜索最佳 RAG 实践
在下一节中,我们将研究实施 RAG 的最佳实践。 首先,我们对每个模块使用章节3中确定的默认实践。 按照图1所示的工作流程,我们依次优化各个模块并在备选方案中选择最有效的选项。 这个迭代过程一直持续到我们确定实现最终汇总模块的最佳方法为止。 基于第 3.8 节,我们使用 Llama2-7B-Chat 模型进行微调,其中每个查询都通过一些随机选择的相关文档作为生成器进行增强。 我们使用 Milvus 构建了一个向量数据库,其中包含 10 万条英文维基百科文本和 4 万条医学数据。 我们还调查了删除查询分类、重新排名和摘要模块的影响,以评估它们的贡献。
4.1、综合评价
我们在各种 NLP 任务和数据集上进行了广泛的实验,以评估 RAG 系统的性能。 具体来说:(1)常识推理; (2)事实核查; (3) 开放域质量检查; (4) 多跳QA; (5) 医学质量保证。 有关任务及其对应数据集的更多详细信息,请参阅附录A.6。 此外,我们使用 RAGA [51] 中推荐的指标,对从这些数据集中提取的子集评估了 RAG 功能,包括忠实性、上下文相关性、答案相关性和答案正确性。 此外,我们通过计算检索到的文档和黄金文档之间的余弦相似度来测量检索相似度。
我们使用准确性作为常识推理、事实检查和医学质量保证任务的评估指标。 对于开放域 QA 和多跳 QA,我们采用了 Token 级 F1 分数和精确匹配 (EM) 分数。 最终的 RAG 分数是通过对上述五种 RAG 能力进行平均来计算的。 我们遵循 Trivedi 等人 [52] 并从每个数据集中对最多 500 个示例进行二次采样。

框线内的模块正在研究以确定最佳方法。下划线的方法代表所选的实施方案。‘Avg’(平均分)是根据所有任务的准确率、期望最大化(EM)和RAG分数计算的,而平均延迟是以每查询秒数来衡量的。最佳分数以粗体突出显示。
4.2、结果与分析
根据表4.1中的实验结果,得出以下关键结论:
- 查询分类模块: 该模块被引用并有助于提高有效性和效率,使总体得分平均从 0.428 提高到 0.443,并将延迟时间从 16.41 减少每次查询 11.58 秒。
- 检索模块: 虽然“Hybrid with HyDE”方法获得了最高的 RAG 分数 0.58,但它的计算成本相当高,每个查询需要 11.71 秒。 因此,建议使用“混合”或“原始”方法,因为它们可以减少延迟,同时保持可比较的性能。
- 重新排序模块: 缺乏重新排名模块导致性能明显下降,凸显了其必要性。 MonoT5 获得了最高的平均分数,证实了其在增强检索文档的相关性方面的功效。 这表明重新排名在提高生成响应的质量方面发挥着关键作用。
- 重新打包模块: 反向配置表现出卓越的性能,获得了 0.560 的 RAG 分数。 这表明将更相关的上下文放置在更靠近查询的位置会带来最佳结果。
- 总结模块: 尽管通过删除汇总模块可以以更低的延迟获得可比较的结果,但 Recomp 展示了卓越的性能。 尽管如此,Recomp 仍然是首选,因为它能够解决生成器的最大长度限制。 在时间敏感的应用程序中,删除摘要可以有效减少响应时间。
实验结果表明,每个模块对 RAG 系统的整体性能都有独特的贡献。 查询分类模块提高了准确性并减少了延迟,而检索和重新排序模块则显著提高了系统处理各种查询的能力。 重新打包和汇总模块进一步细化系统的输出,确保跨不同任务的高质量响应。
5、讨论
5.1、实施 RAG 的最佳实践
根据我们的实验结果,我们提出了两种不同的方法或实践来实施 RAG 系统,每种方法或实践都是为了满足特定要求而定制的:一种侧重于性能最大化,另一种侧重于在效率和功效之间取得平衡。
最佳性能实践: 为了获得最高性能,建议合并查询分类模块,使用“Hybrid with HyDE”方法进行检索,使用monoT5进行重新排序,选择Reverse进行重新打包,并利用Recomp进行摘要。 尽管采用了计算密集型过程,但此配置产生了最高平均分数 0.483。
平衡效率实践: 为了达到性能和效率的平衡,建议加入查询分类模块,检索采用Hybrid方法,重排序采用TILDEv2,重打包采用Reverse,摘要采用Recomp。 鉴于检索模块占据系统中的大部分处理时间,在保持其他模块不变的情况下过渡到混合方法可以大大减少延迟,同时保持可比较的性能。
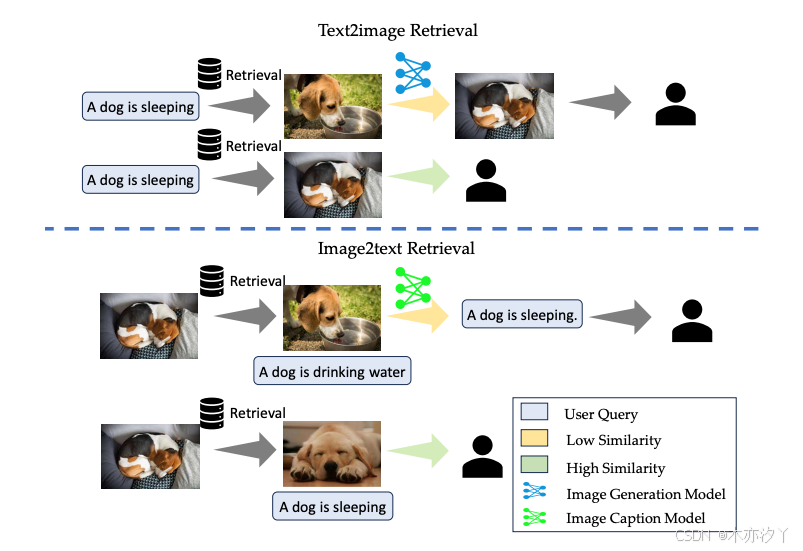
上半部分说明了文本到图像的检索过程。 最初,使用文本查询来查找数据库中相似度最高的图像。 如果发现相似度较高,则直接返回图像。 如果没有,则采用图像生成模型来创建并返回适当的图像。
下半部分演示了图像到文本的检索过程。 在这里,将用户提供的图像与数据库中的图像进行匹配,以找到最高的相似度。 如果识别出高度相似性,则返回匹配图像的预存储标题。 否则,图像字幕模型会生成并返回新的字幕。
5.2、多模式扩展
我们已将 RAG 扩展到多模态应用。 具体来说,我们将文本到图像和图像到文本检索功能合并到系统中,并以大量配对图像和文本描述作为检索源。 如图4所示,当用户查询与存储图像的文本描述(即“检索即生成”策略)很好地结合时,text2image功能可以加速图像生成过程,而image2text功能当用户提供图像并参与有关输入图像的对话时,它就会发挥作用。 这些多模式 RAG 功能具有以下优势:
- 接地气:检索方法提供来自经过验证的多模态材料的信息,从而确保真实性和特异性。 相比之下,动态生成依赖于模型来生成新内容,这有时会导致事实错误或不准确。
- 效率:检索方法通常更有效,特别是当答案已存在于存储的材料中时。 相反,生成方法可能需要更多的计算资源来生成新内容,特别是对于图像或冗长的文本。
- 可维护性:生成模型通常需要仔细微调才能适应新应用程序。 相比之下,基于检索的方法可以通过简单地扩大检索源的规模和提高检索源的质量来改进以满足新的需求。
我们计划扩大该策略的应用范围,以包括其他模态,例如视频和语音,同时还探索高效且有效的跨模态检索技术。
6、结论
在本研究中,我们的目标是确定实施检索增强生成的最佳实践,以提高大型语言模型生成的内容的质量和可靠性。 我们系统地评估了 RAG 框架内每个模块的一系列潜在解决方案,并为每个模块推荐了最有效的方法。 此外,我们引入了 RAG 系统的综合评估基准,并进行了广泛的实验,以确定各种替代方案中的最佳实践。 我们的研究结果不仅有助于更深入地理解检索增强生成系统,而且为未来的研究奠定了基础。
局限性
我们评估了微调 LLM 生成器的各种方法的影响。 先前的研究已经证明了联合训练检索器和生成器的可行性。 我们希望在未来探索这种可能性。 在本研究中,我们采用模块化设计原则来简化对最佳 RAG 实现的搜索,从而降低复杂性。 由于构建向量数据库和进行实验相关的成本高昂,我们的评估仅限于调查分块模块内代表性分块技术的有效性和影响。 进一步探索不同分块技术对整个 RAG 系统的影响将会很有趣。 虽然我们已经讨论了 RAG 在 NLP 领域的应用并将其范围扩展到图像生成,但未来探索的一个诱人途径是将这项研究扩展到语音和视频等其他模式。
致谢
作者衷心感谢匿名审稿人提出的宝贵意见。 该工作得到国家自然科学基金项目(No. 62076068).
参考
[1] Long Ouyang, Jeff Wu, Xu Jiang, Diogo Almeida, Carroll L. Wainwright, Pamela Mishkin, Chong Zhang, Sandhini Agarwal, Katarina Slama, Alex Ray, John Schulman, Jacob Hilton, Fraser Kelton, Luke Miller, Maddie Simens, Amanda Askell, Peter Welinder, Paul Christiano, Jan Leike, and Ryan Lowe. Training language models to follow instructions with human feedback. In Proceedings of the Conference on Neural Information Processing Systems (NeurIPS 2022), 2022.
[2] Rafael Rafailov, Archit Sharma, Eric Mitchell, Stefano Ermon, Christopher D Manning, and Chelsea Finn. Direct preference optimization: Your language model is secretly a reward model. arXiv preprint arXiv:2305.18290, 2023.
[3] Yao Zhao, Rishabh Joshi, Tianqi Liu, Misha Khalman, Mohammad Saleh, and Peter J Liu. SLICHF: Sequence likelihood calibration with human feedback. arXiv preprint arXiv:2305.10425,2023.
[4] Zheng Yuan, Hongyi Yuan, Chuanqi Tan, Wei Wang, Songfang Huang, and Fei Huang. RRHF: Rank responses to align language models with human feedback without tears. arXiv preprint arXiv:2304.05302, 2023.
[5] Wenhao Liu, Xiaohua Wang, Muling Wu, Tianlong Li, Changze Lv, Zixuan Ling, Jianhao Zhu, Cenyuan Zhang, Xiaoqing Zheng, and Xuanjing Huang. Aligning large language models with human preferences through representation engineering. arXiv preprint arXiv:2312.15997, 2023.
[6] Yunfan Gao, Yun Xiong, Xinyu Gao, Kangxiang Jia, Jinliu Pan, Yuxi Bi, Yi Dai, Jiawei Sun, and Haofen Wang. Retrieval-augmented generation for large language models: A survey. arXiv preprint arXiv:2312.10997, 2023.
[7] Huayang Li, Yixuan Su, Deng Cai, Yan Wang, and Lemao Liu. A survey on retrieval-augmented text generation. arXiv preprint arXiv:2202.01110, 2022.
[8] Deng Cai, Yan Wang, Lemao Liu, and Shuming Shi. Recent advances in retrieval-augmented text generation. In Proceedings of the 45th international ACM SIGIR conference on research and development in information retrieval, pages 3417–3419, 2022.
[9] Xinbei Ma, Yeyun Gong, Pengcheng He, Hai Zhao, and Nan Duan. Query rewriting for retrieval-augmented large language models. arXiv preprint arXiv:2305.14283, 2023.
[10] Luyu Gao, Xueguang Ma, Jimmy Lin, and Jamie Callan. Precise zero-shot dense retrieval without relevance labels. arXiv preprint arXiv:2212.10496, 2022.
[11] Liang Wang, Nan Yang, Xiaolong Huang, Binxing Jiao, Linjun Yang, Daxin Jiang, Rangan Majumder, and Furu Wei. Text embeddings by weakly-supervised contrastive pre-training. arXiv preprint arXiv:2212.03533, 2022.
[12] Shitao Xiao, Zheng Liu, Peitian Zhang, and Niklas Muennighoff. C-pack: Packaged resources to advance general chinese embedding, 2023.
[13] OpenAI. GPT-4 technical report. CoRR, abs/2303.08774, 2023. doi: 10.48550/ARXIV.2303. 08774. URL https://doi.org/10.48550/arXiv.2303.08774.
[14] Hugo Touvron, Thibaut Lavril, Gautier Izacard, Xavier Martinet, Marie-Anne Lachaux, Timothée Lacroix, Baptiste Rozière, Naman Goyal, Eric Hambro, Faisal Azhar, et al. LLaMA: Open and efficient foundation language models. arXiv preprint arXiv:2302.13971, 2023.
[15] Yue Zhang, Yafu Li, Leyang Cui, Deng Cai, Lemao Liu, Tingchen Fu, Xinting Huang, Enbo Zhao, Yu Zhang, Yulong Chen, et al. Siren’s song in the ai ocean: a survey on hallucination in large language models. arXiv preprint arXiv:2309.01219, 2023.
[16] Xiaohua Wang, Yuliang Yan, Longtao Huang, Xiaoqing Zheng, and Xuan-Jing Huang. Hallucination detection for generative large language models by bayesian sequential estimation. In Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, pages 15361–15371, 2023.
[17] Liang Wang, Nan Yang, and Furu Wei. Query2doc: Query expansion with large language models. arXiv preprint arXiv:2303.07678, 2023.
[18] Gangwoo Kim, Sungdong Kim, Byeongguk Jeon, Joonsuk Park, and Jaewoo Kang. Tree of clarifications: Answering ambiguous questions with retrieval-augmented large language models. arXiv preprint arXiv:2310.14696, 2023.
[19] Jerry Liu. LlamaIndex, 11 2022. URL https://github.com/jerryjliu/llama_index.
[20] Peitian Zhang, Shitao Xiao, Zheng Liu, Zhicheng Dou, and Jian-Yun Nie. Retrieve anything to augment large language models. arXiv preprint arXiv:2310.07554, 2023.
[21] Zehan Li, Xin Zhang, Yanzhao Zhang, Dingkun Long, Pengjun Xie, and Meishan Zhang. Towards general text embeddings with multi-stage contrastive learning. arXiv preprint arXiv:2308.03281, 2023.
[22] Huiqiang Jiang, Qianhui Wu, Chin-Yew Lin, Yuqing Yang, and Lili Qiu. Llmlingua: Compressing prompts for accelerated inference of large language models. arXiv preprint arXiv:2310.05736, 2023.
[23] Fangyuan Xu, Weijia Shi, and Eunsol Choi. Recomp: Improving retrieval-augmented lms with compression and selective augmentation. arXiv preprint arXiv:2310.04408, 2023.
[24] Zhiruo Wang, Jun Araki, Zhengbao Jiang, Md Rizwan Parvez, and Graham Neubig. Learning to filter context for retrieval-augmented generation. arXiv preprint arXiv:2311.08377, 2023.
[25] Rodrigo Nogueira, Wei Yang, Kyunghyun Cho, and Jimmy Lin. Multi-stage document ranking with bert. arXiv preprint arXiv:1910.14424, 2019.
[26] Rodrigo Nogueira, Zhiying Jiang, and Jimmy Lin. Document ranking with a pretrained sequence-to-sequence model. arXiv preprint arXiv:2003.06713, 2020.
[27] Xueguang Ma, Liang Wang, Nan Yang, Furu Wei, and Jimmy Lin. Fine-tuning llama for multi-stage text retrieval. arXiv preprint arXiv:2310.08319, 2023.
[28] Shengyao Zhuang and Guido Zuccon. Tilde: Term independent likelihood model for passage re-ranking. In Proceedings of the 44th International ACM SIGIR Conference on Research and Development in Information Retrieval, pages 1483–1492, 2021.
[29] Shengyao Zhuang and Guido Zuccon. Fast passage re-ranking with contextualized exact term matching and efficient passage expansion. arXiv preprint arXiv:2108.08513, 2021.
[30] Hongyin Luo, Yung-Sung Chuang, Yuan Gong, Tianhua Zhang, Yoon Kim, Xixin Wu, Danny Fox, Helen M. Meng, and James R. Glass. Sail: Search-augmented instruction learning. In Conference on Empirical Methods in Natural Language Processing, 2023. URL https://api.semanticscholar.org/CorpusID:258865283.
[31] Tianjun Zhang, Shishir G. Patil, Naman Jain, Sheng Shen, Matei A. Zaharia, Ion Stoica, and Joseph E. Gonzalez. Raft: Adapting language model to domain specific rag. ArXiv,abs/2403.10131, 2024.
[32] Zihan Liu, Wei Ping, Rajarshi Roy, Peng Xu, Chankyu Lee, Mohammad Shoeybi, and Bryan Catanzaro. Chatqa: Surpassing gpt-4 on conversational qa and rag. 2024. URL https://api.semanticscholar.org/CorpusID:267035133.
[33] Gautier Izacard, Patrick Lewis, Maria Lomeli, Lucas Hosseini, Fabio Petroni, Timo Schick, Jane A. Yu, Armand Joulin, Sebastian Riedel, and Edouard Grave. Few-shot learning with retrieval augmented language models. ArXiv, abs/2208.03299, 2022.
[34] Lingxi Zhang, Yue Yu, Kuan Wang, and Chao Zhang. Arl2: Aligning retrievers for black-box large language models via self-guided adaptive relevance labeling. ArXiv, abs/2402.13542, 2024.
[35] Weijia Shi, Sewon Min, Michihiro Yasunaga, Minjoon Seo, Rich James, Mike Lewis, Luke Zettlemoyer, and Wen-tau Yih. Replug: Retrieval -augmented black-box language models. arXiv preprint arXiv:2301.12652, 2023.
[36] Kelvin Guu, Kenton Lee, Zora Tung, Panupong Pasupat, and Ming-Wei Chang. Realm:Retrieval-augmented language model pre-training. ArXiv, abs/2002.08909, 2020.
[37] Xi Victoria Lin, Xilun Chen, Mingda Chen, Weijia Shi, Maria Lomeli, Rich James, Pedro Rodriguez, Jacob Kahn, Gergely Szilvasy, Mike Lewis, Luke Zettlemoyer, and Scott Yih. Ra-dit: Retrieval-augmented dual instruction tuning. ArXiv, abs/2310.01352, 2023.
[38] Hamed Zamani and Michael Bendersky. Stochastic rag: End-to-end retrieval-augmented generation through expected utility maximization. 2024. URL https://api.semanticscholar.org/CorpusID:269605438.
[39] Yizheng Huang and Jimmy Huang. A survey on retrieval-augmented text generation for large language models. arXiv preprint arXiv:2404.10981, 2024.
[40] Ruochen Zhao, Hailin Chen, Weishi Wang, Fangkai Jiao, Xuan Long Do, Chengwei Qin, Bosheng Ding, Xiaobao Guo, Minzhi Li, Xingxuan Li, et al. Retrieving multimodal information for augmented generation: A survey. arXiv preprint arXiv:2303.10868, 2023.
[41] Penghao Zhao, Hailin Zhang, Qinhan Yu, Zhengren Wang, Yunteng Geng, Fangcheng Fu, Ling Yang, Wentao Zhang, and Bin Cui. Retrieval-augmented generation for ai-generated content: A survey. arXiv preprint arXiv:2402.19473, 2024.
[42] Michael Günther, Jackmin Ong, Isabelle Mohr, Alaeddine Abdessalem, Tanguy Abel, Mohammad Kalim Akram, Susana Guzman, Georgios Mastrapas, Saba Sturua, Bo Wang, et al. Jina embeddings 2: 8192-token general-purpose text embeddings for long documents. arXiv preprint arXiv:2310.19923, 2023.
[43] LlamaIndex. Llamaindex website. https://www.llamaindex.com. Accessed: 2024-06-08.
[44] Kunal Sawarkar, Abhilasha Mangal, and Shivam Raj Solanki. Blended rag: Improving rag (retriever-augmented generation) accuracy with semantic search and hybrid query-based retrievers. arXiv preprint arXiv:2404.07220, 2024.
[45] Gautier Izacard, Mathilde Caron, Lucas Hosseini, Sebastian Riedel, Piotr Bojanowski, Armand Joulin, and Edouard Grave. Unsupervised dense information retrieval with contrastive learning. arXiv preprint arXiv:2112.09118, 2021.
[46] Nandan Thakur, Nils Reimers, Andreas Rücklé, Abhishek Srivastava, and Iryna Gurevych. Beir: A heterogenous benchmark for zero-shot evaluation of information retrieval models. arXiv preprint arXiv:2104.08663, 2021.
[47] Payal Bajaj, Daniel Campos, Nick Craswell, Li Deng, Jianfeng Gao, Xiaodong Liu, Rangan Majumder, Andrew McNamara, Bhaskar Mitra, Tri Nguyen, et al. Ms marco: A human generated machine reading comprehension dataset. arXiv preprint arXiv:1611.09268, 2016.
[48] Nelson F Liu, Kevin Lin, John Hewitt, Ashwin Paranjape, Michele Bevilacqua, Fabio Petroni, and Percy Liang. Lost in the middle: How language models use long contexts. Transactions of the Association for Computational Linguistics, 12:157–173, 2024.
[49] Huiqiang Jiang, Qianhui Wu, Xufang Luo, Dongsheng Li, Chin-Yew Lin, Yuqing Yang, and Lili Qiu. Longllmlingua: Accelerating and enhancing llms in long context scenarios via prompt compression. arXiv preprint arXiv:2310.06839, 2023.
[50] Hugo Touvron, Louis Martin, Kevin R. Stone, Peter Albert, Amjad Almahairi, Yasmine Babaei, Nikolay Bashlykov, Soumya Batra, Prajjwal Bhargava, Shruti Bhosale, Daniel M. Bikel, Lukas Blecher, Cristian Cantón Ferrer, Moya Chen, Guillem Cucurull, David Esiobu, Jude Fernandes, Jeremy Fu, Wenyin Fu, Brian Fuller, Cynthia Gao, Vedanuj Goswami, Naman Goyal, Anthony S. Hartshorn, Saghar Hosseini, Rui Hou, Hakan Inan, Marcin Kardas, Viktor Kerkez, Madian Khabsa, Isabel M. Kloumann, A. V. Korenev, Punit Singh Koura, Marie-Anne Lachaux, Thibaut Lavril, Jenya Lee, Diana Liskovich, Yinghai Lu, Yuning Mao, Xavier Martinet, Todor Mihaylov, Pushkar Mishra, Igor Molybog, Yixin Nie, Andrew Poulton, Jeremy Reizenstein, Rashi Rungta, Kalyan Saladi, Alan Schelten, Ruan Silva, Eric Michael Smith, R. Subramanian, Xia Tan, Binh Tang, Ross Taylor, Adina Williams, Jian Xiang Kuan, Puxin Xu, Zhengxu Yan, Iliyan Zarov, Yuchen Zhang, Angela Fan, Melanie Kambadur, Sharan Narang, Aurelien Rodriguez, Robert Stojnic, Sergey Edunov, and Thomas Scialom. Llama 2: Open foundation and fine-tuned chat
models. ArXiv, abs/2307.09288, 2023.
[51] ES Shahul, Jithin James, Luis Espinosa Anke, and Steven Schockaert. Ragas: Automated evaluation of retrieval augmented generation. In Conference of the European Chapter of the Association for Computational Linguistics, 2023. URL https://api.semanticscholar.org/CorpusID:263152733.
[52] Harsh Trivedi, Niranjan Balasubramanian, Tushar Khot, and Ashish Sabharwal. Musique: Multihop questions via single-hop question composition. Transactions of the Association for Computational Linguistics, page 539–554, May 2022. doi: 10.1162/tacl_a_00475. URL http://dx.doi.org/10.1162/tacl_a_00475.
[53] Mike Conover, Matt Hayes, Ankit Mathur, Jianwei Xie, Jun Wan, Sam Shah, Ali Ghodsi, Patrick Wendell, Matei Zaharia, and Reynold Xin. Free dolly: Introducing the world’s first truly open instruction-tuned llm, 2023. URL https://www.databricks.com/blog/2023/04/12/dolly-first-open-commercially-viable-instruction-tuned-llm.
[54] Nick Craswell, Bhaskar Mitra, Emine Yilmaz, Daniel Fernando Campos, and Ellen M. Voorhees. Overview of the trec 2019 deep learning track. ArXiv, abs/2003.07820, 2020. URL https://api.semanticscholar.org/CorpusID:253234683.
[55] Nick Craswell, Bhaskar Mitra, Emine Yilmaz, Daniel Fernando Campos, and Ellen M. Voorhees. Overview of the trec 2020 deep learning track. ArXiv, abs/2102.07662, 2021. URL https://api.semanticscholar.org/CorpusID:212737158.
[56] Jimmy Lin, Xueguang Ma, Sheng-Chieh Lin, Jheng-Hong Yang, Ronak Pradeep, and Rodrigo Nogueira. Pyserini: A python toolkit for reproducible information retrieval research with sparse and dense representations. In Proceedings of the 44th International ACM SIGIR Conference on Research and Development in Information Retrieval, pages 2356–2362, 2021.
[57] Tom Kwiatkowski, Jennimaria Palomaki, Olivia Redfield, Michael Collins, Ankur P. Parikh, Chris Alberti, Danielle Epstein, Illia Polosukhin, Jacob Devlin, Kenton Lee, Kristina Toutanova, Llion Jones, Matthew Kelcey, Ming-Wei Chang, Andrew M. Dai, Jakob Uszkoreit, Quoc V. Le, and Slav Petrov. Natural questions: A benchmark for question answering research. Transactions of the Association for Computational Linguistics, 7:453–466, 2019.
[58] Mandar Joshi, Eunsol Choi, Daniel S. Weld, and Luke Zettlemoyer. Triviaqa: A large scale distantly supervised challenge dataset for reading comprehension. ArXiv, abs/1705.03551,2017.
[59] Zhilin Yang, Peng Qi, Saizheng Zhang, Yoshua Bengio, William W Cohen, Ruslan Salakhutdinov, and Christopher D Manning. Hotpotqa: A dataset for diverse, explainable multi-hop question answering. arXiv preprint arXiv:1809.09600, 2018.
[60] Ivan Stelmakh, Yi Luan, Bhuwan Dhingra, and Ming-Wei Chang. Asqa: Factoid questions meet long-form answers. ArXiv, abs/2204.06092, 2022.
[61] Tomáš Kocisk ˇ y, Jonathan Schwarz, Phil Blunsom, Chris Dyer, Karl Moritz Hermann, Gábor Melis, and Edward Grefenstette. The narrativeqa reading comprehension challenge. Transactions of the Association for Computational Linguistics, 6:317–328, 2018.
[62] Pranav Rajpurkar, Jian Zhang, Konstantin Lopyrev, and Percy Liang. Squad: 100,000+ questions for machine comprehension of text. arXiv preprint arXiv:1606.05250, 2016.
[63] Stephanie Lin, Jacob Hilton, and Owain Evans. Truthfulqa: Measuring how models mimic human falsehoods. arXiv preprint arXiv:2109.07958, 2021.
[64] J. Edward Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, and Weizhu Chen. Lora: Low-rank adaptation of large language models. ArXiv, abs/2106.09685, 2021.
[65] Dan Hendrycks, Collin Burns, Steven Basart, Andy Zou, Mantas Mazeika, Dawn Song, and Jacob Steinhardt. Measuring massive multitask language understanding. Cornell University - arXiv,Cornell University - arXiv, Sep 2020.
[66] Peter Clark, Isaac Cowhey, Oren Etzioni, Tushar Khot, Ashish Sabharwal, Carissa Schoenick, and Oyvind Tafjord. Think you have solved question answering? try arc, the ai2 reasoning challenge. ArXiv, abs/1803.05457, 2018. URL https://api.semanticscholar.org/CorpusID:3922816.
[67] Todor Mihaylov, Peter Clark, Tushar Khot, and Ashish Sabharwal. Can a suit of armor conduct electricity? a new dataset for open book question answering. In Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing, Jan 2018. doi:10.18653/v1/d18-1260. URL http://dx.doi.org/10.18653/v1/d18-1260.
[68] James Thorne, Andreas Vlachos, Christos Christodoulopoulos, and Arpit Mittal. Fever: a large-scale dataset for fact extraction and verification. ArXiv, abs/1803.05355, 2018. URL https://api.semanticscholar.org/CorpusID:4711425.
[69] Tianhua Zhang, Hongyin Luo, Yung-Sung Chuang, Wei Fang, Luc Gaitskell, Thomas Hartvigsen, Xixin Wu, Danny Fox, Helen M. Meng, and James R. Glass. Interpretable unified language checking. ArXiv, abs/2304.03728, 2023. URL https://api.semanticscholar.org/CorpusID:258041307.
[70] Jonathan Berant, Andrew Chou, Roy Frostig, and Percy Liang. Semantic parsing on freebase from question-answer pairs. Empirical Methods in Natural Language Processing,Empirical Methods in Natural Language Processing, Oct 2013.
[71] Xanh Ho, A. Nguyen, Saku Sugawara, and Akiko Aizawa. Constructing a multi-hop qa dataset for comprehensive evaluation of reasoning steps. ArXiv, abs/2011.01060, 2020. URL https://api.semanticscholar.org/CorpusID:226236740.
[72] Ofir Press, Muru Zhang, Sewon Min, Ludwig Schmidt, NoahA. Smith, and Mike Lewis. Measuring and narrowing the compositionality gap in language models. Oct 2022.
[73] Qiao Jin, Bhuwan Dhingra, Zhengping Liu, William W. Cohen, and Xinghua Lu. Pubmedqa: A dataset for biomedical research question answering. In Conference on Empirical Methods in Natural Language Processing, 2019. URL https://api.semanticscholar.org/CorpusID:202572622.
[74] Akari Asai, Zeqiu Wu, Yizhong Wang, Avirup Sil, and Hannaneh Hajishirzi. Self-rag: Learning to retrieve, generate, and critique through self-reflection. arXiv preprint arXiv:2310.11511,2023.
附录A实验细节
在本节中,我们为每个模块提供详细的实验设置,涵盖数据集细节、训练参数和任何其他实验结果。
- 略



















 998
998

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











