






[2502.12524] YOLOv12: Attention-Centric Real-Time Object DetectorsAbstract page for arXiv paper 2502.12524: YOLOv12: Attention-Centric Real-Time Object Detectors
https://arxiv.org/abs/2502.12524文章提出了一个以注意力为中心的YOLO框架——YOLOv12,平衡了性能和速度。
目录
📌文章针对目前存在的问题:
YOLO 系列模型因其在速度和精度之间的平衡而成为实时目标检测的主流方法。然而,尽管注意力机制(如 Transformer)在建模能力上优于 CNN,YOLO 的架构仍主要基于 CNN,原因在于注意力机制在计算复杂度和内存访问效率上的劣势,导致其推理速度不及 CNN。 那么在加入注意力机制以后如何能解决这些问题呢,文章给出了一些解决方案!
✨论文的主要贡献:
- 提出了一个以注意力为核心的YOLO框架,即YOLOv12
- 在不依赖于预训练等额外技术的情况下,YOLOv12以更快的推理速度和更高的检测精度获得了最先进的结果,展示了其潜力
🏓YOLOV12主要包括三个关键的模块:
- 提出了一个简单但高效的区域注意力模块(area attention module,A2),能够保持较大的感受野,而且还能降低注意力机制的计算复杂度,从而提高了速度
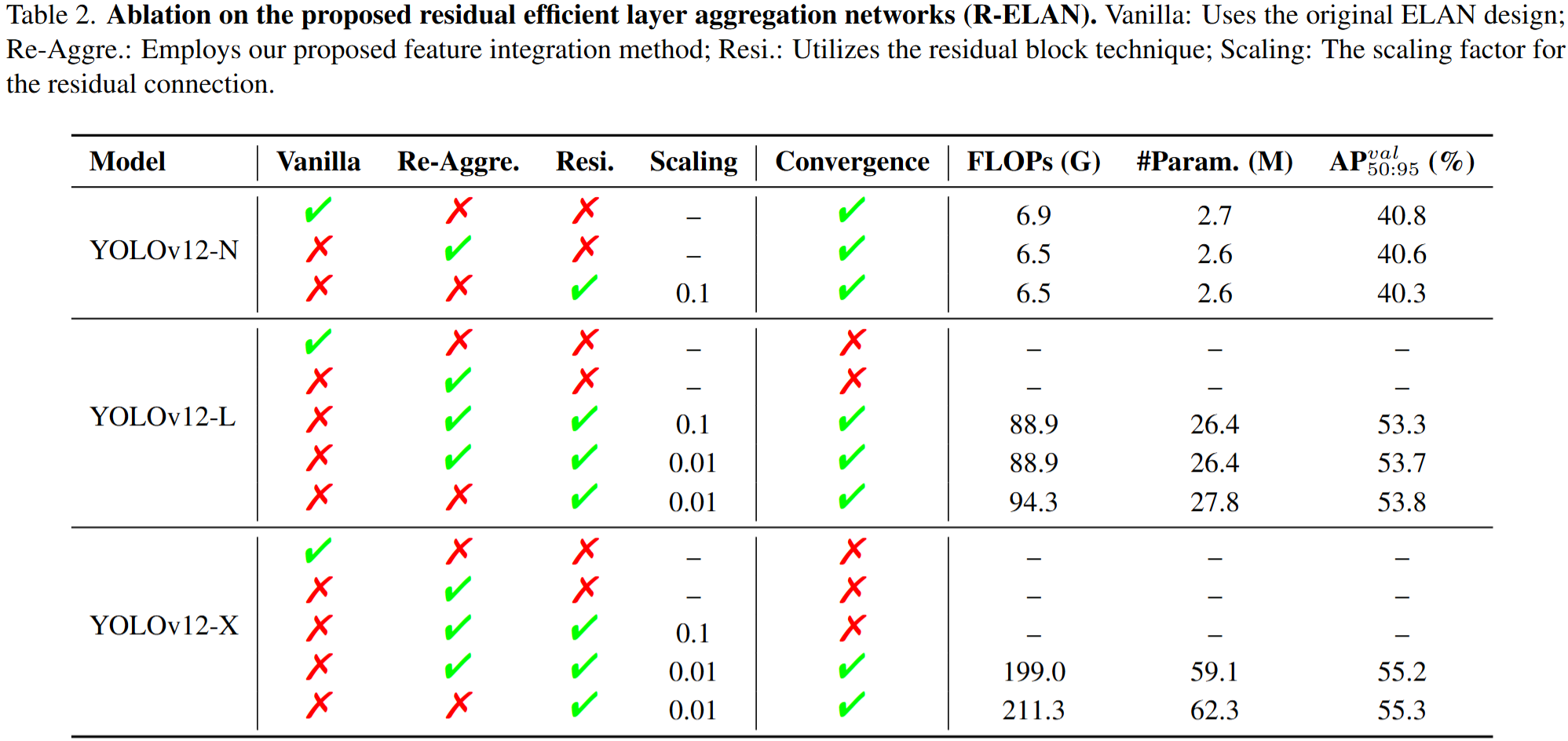
- 引入了残差高效层聚合网络(residual efficient layer aggregation networks,R-ELAN)来解决由注意力引入的优化挑战(主要就是大尺度模型的问题)
- 升级了传统的注意力中心架构,将MLP的比例从4调整到1.2去平衡注意力和前馈网络之间的计算以获得更好的性能,减少堆叠块的深度以促进优化,并尽可能使用卷积算子来利用它们的计算效率(MLP ratio:在Transformer结构中,MLP通常指的是每个Transformer Block里的前馈神经网络部分。MLP ratio一般指的是MLP隐藏层的宽度与输入宽度的比例。例如,输入维度是d,MLP隐藏层宽度是4d,则MLP ratio为4。)
文章的Related Work是按照YOLO版本迭代的顺序写的,描述了每个版本做了哪些事情。同时,也介绍了RT-DETR和注意力相关的内容,这里不再赘述。
🪔文章分析了注意力机制比CNN速度慢的原因主要有以下两点:
- self-attention的计算复杂度随输入序列长度L呈二次增长的。比如,对于一个长度为L,特征维数为d的输入序列来说,由于每个ken都关注其他token,因此计算注意力矩阵需要
次操作。而CNN中的卷积操作在空间和时间尺度上呈线性缩放的,需要
次,其中k是卷积核大小,比L小。所以就导致自注意力在计算上变得难以实现,特别是对于高分辨率图像或长序列等大输入。
- 在注意力机制的计算过程中,与CNN相比,其内存访问模式效率较低。注意力机制在计算时,需要从内存中读取数据的模式不如CNN那样高效。CNN倾向于读取内存中相邻的数据块,这很适合现代计算机的缓存架构,速度快。而注意力机制可能需要跳跃式地读取内存中分散的数据,这使得缓存难以发挥作用,导致实际计算速度受限于内存访问速度,因此效率相对较低。
🥇第一个关键改进——Area Attention
目的是要去解决计算的复杂性,文章指出下图中前三个注意力机制将特征映射划分为窗口可能会带来开销或减少感受野,从而影响速度和准确性。Area attention是将分辨率为的特征图分成大小为
或者是
,这样做可以消除窗口分区。文章中将
设置为4,只有当resize分辨率为640时,注意力机制的计算会减少一半;当输入分辨率增加时,只增加
(指的是token的数量)。

🥈第二个关键改进——R-ELAN
YOLOv7提出的Efficient layer aggregation networks (ELAN)目的是改善特征聚合,特征聚合指的是将来自网络不同部分或不同处理路径的特征信息有效地结合起来,以产生更丰富、更强大的特征表示。他的工作流程可以理解为:输入特征先经过一个1x1卷积(过渡层),该1x1卷积的输出被分割成多条路径,其中一条路径会经过一系列复杂的模块进行深度特征提取,所有路径(包括深度处理过的和未深度处理过的)的输出在通道维度上拼接起来,拼接后的特征再经过一个1x1卷积,以调整通道维度并进一步融合特征。但是这种体系结构可能引入不稳定性。作者认为这样的设计会导致梯度阻塞,并且缺乏从输入到输出的剩余连接。围绕注意力构建网络,会带来额外的优化挑战。
为了解决这个问题,文章提出了R-ELAN,R是residual的意思。就是在整个块中引入了从输入到输出的残差连接,缩放因子默认为0.01。这个模块的设计应用transition来调整通道尺寸并产生单个特征映射。这个特征映射通过后面的块进行处理,然后进行连接,形成瓶颈结构,可以在保持原始特征聚合的能力下,还能减少计算成本和参数的使用。
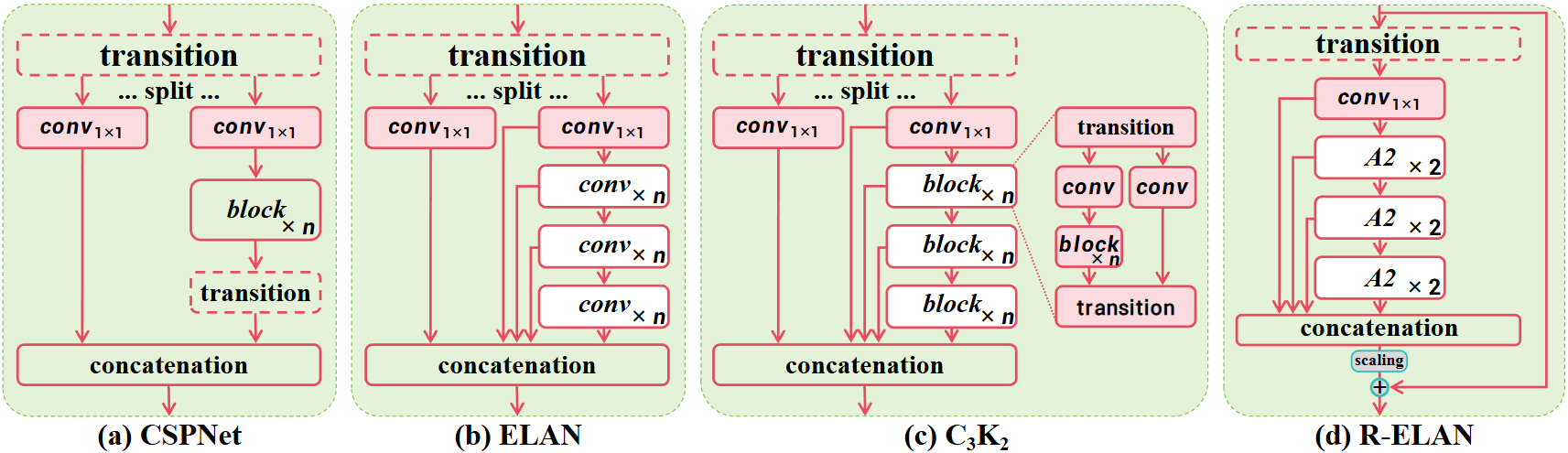
🥉第三个关键改进——架构的升级
YOLOv12主干使用了YOLOv11的前两个阶段,去掉了在主干最后阶段堆叠三个区块的设计,只保留了单个R-ELAN块(用在了主干网络的最后一个阶段),继续使用YOLO经典的分层设计(网络有不同的阶段,每个阶段输出不同尺度的特征图)。除此之外,将MLP的比例从4调整到1.2,采用nn.Conv2d+BN而不是nn.Linear+LN,这样可以充分利用卷积算子的效率。去除了位置编码,引入了7×7的可分离卷积,也就是位置感知器,使注意力机制能够感知到位置信息。通过一个精心设计的7x7可分离卷积,在特征进入注意力机制前进行处理,可以使特征本身就携带足够的局部上下文和相对位置信息。这使得传统的、为序列设计的显式位置编码变得不再必要,并且这种基于卷积的方式更适合图像数据,也更符合YOLO系统高效和卷积密集型的特点。其最终目的是让注意力机制在感知位置信息的同时,保持或提升性能并优化计算。
其中, 可分离卷积(尤其是深度可分离卷积)是一种将标准卷积分解为深度卷积和逐点卷积两步的技术,目的是在大幅降低计算量和参数量的同时,尽可能保持模型的有效性,使得深度学习模型更加轻量和高效。比如,MobileNets、Xception等。
下面两张图分别是深度卷积和逐点卷积:
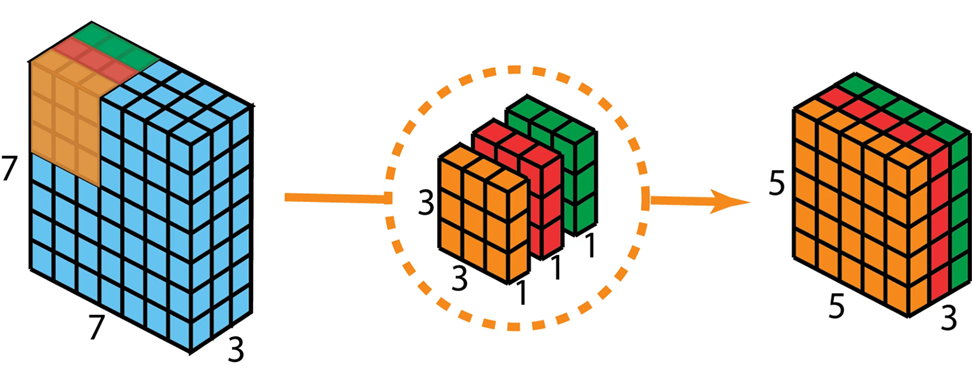
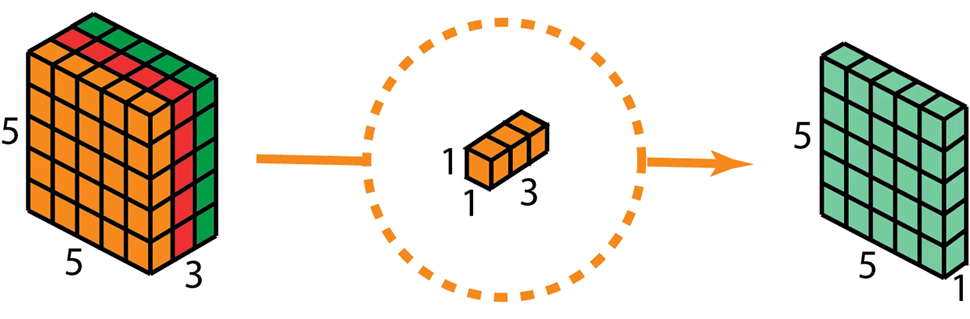
🏆实验部分
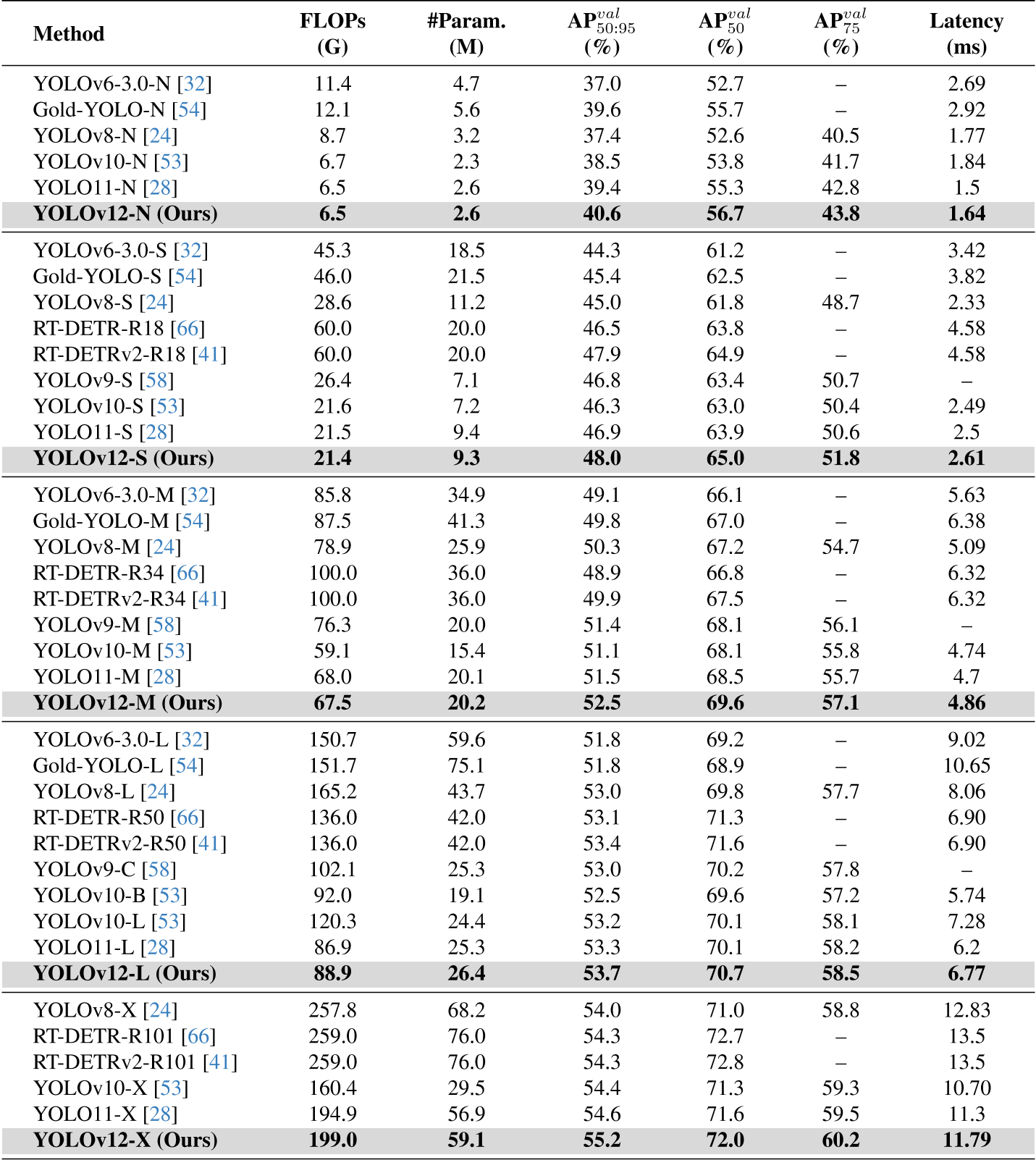
文章在MSCOCO 2017数据集上验证了所提出的方法。YOLOv12系列包括YOLOv12- n、YOLOv12- s、YOLOv12- m、YOLOv12- l和YOLOv12- x。使用SGD优化器对所有模型进行600次epoch的训练,初始学习率为0.01,与YOLOv11(论文采用的baseline)保持一致。采用线性学习率衰减策略,并对前3个周期进行线性预热。在使用TensorRT FP16的T4 GPU上测试所有模型的延迟。
下面方法的对比输入的大小都是640×640的。

下图是关于对R-ELAN的消融实验,主要是针对这个模块内部的一些设定的:
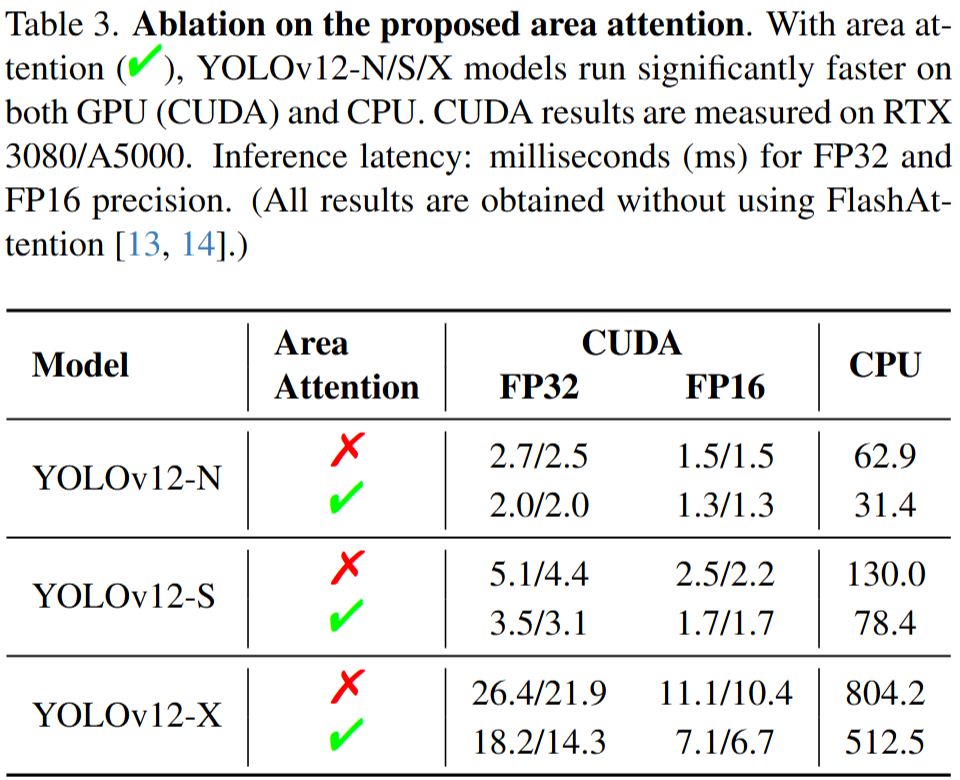
针对Area attention的消融实验,在GPU和CPU上的推理速度相比是很快的,CPU使用的是Intel Core i7-10700K @ 3.80GHz,这个实验没有使用FlasAttention。
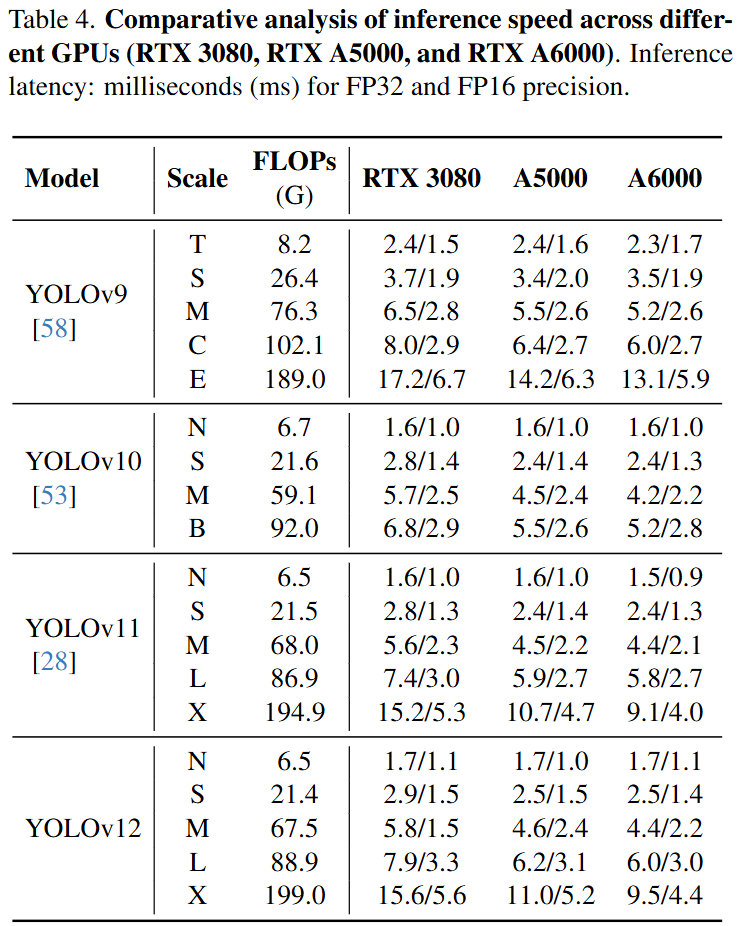
接着比较一下不同的模型在一些GPUs上的速度,所有结果都是在相同的硬件上获得的。
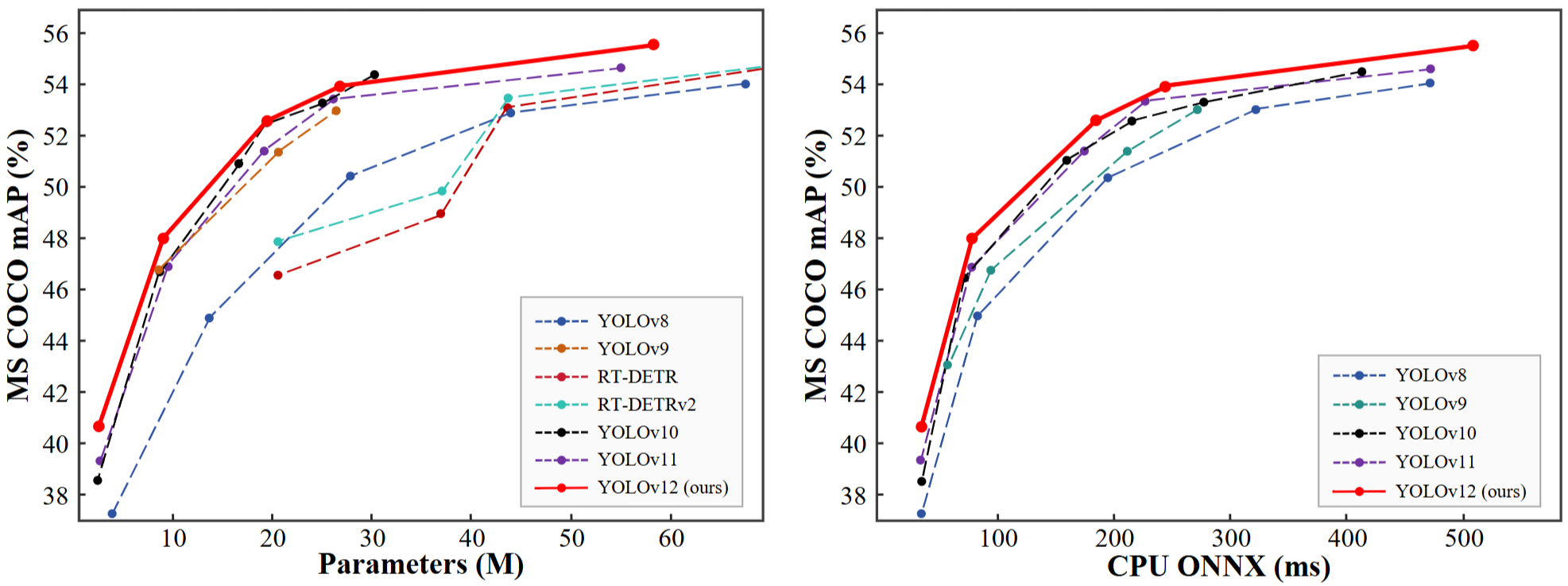
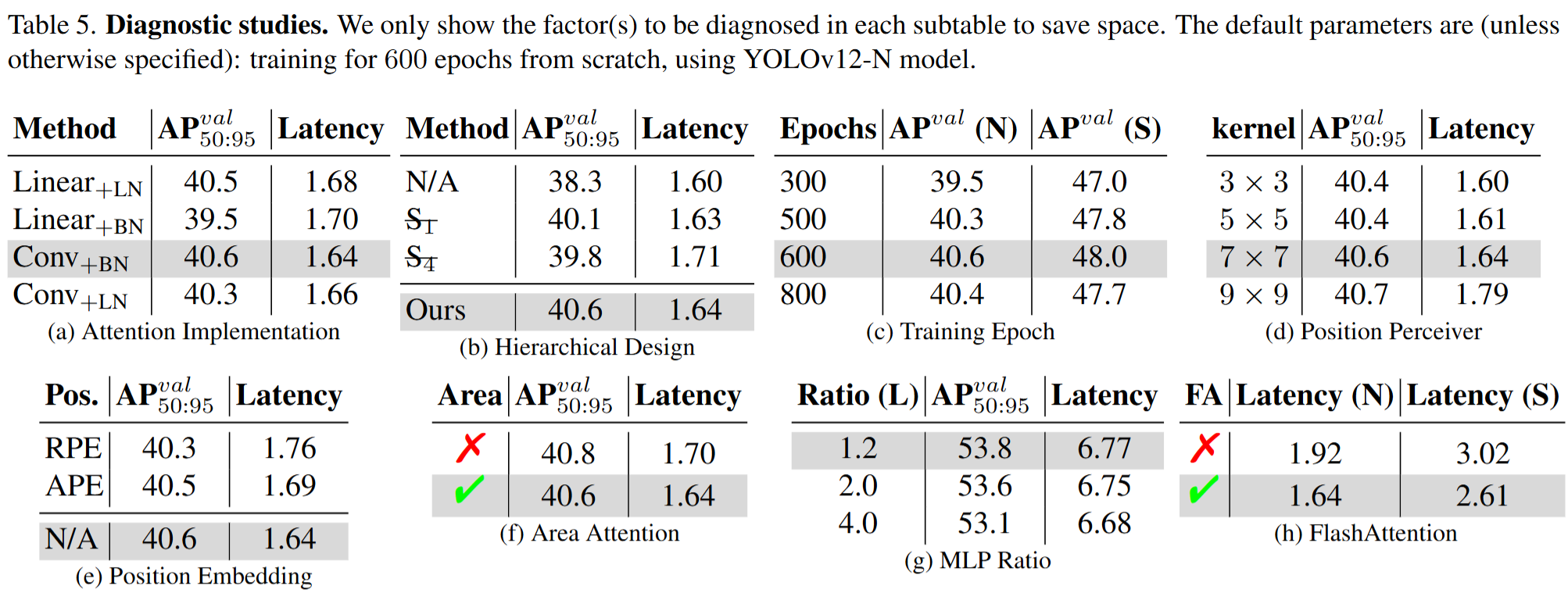
对文章提出一些内容进行如下的诊断,N/A是普通的视觉transformer,是第一阶段,
是第四阶段,上面划了一个横线表示的是省略这一阶段的意思。RPE是相对位置嵌入,APE是绝对位置编码。在Area Attention中默认使用了FlashAttention技术。
下面是几个网络的X模型的热图对比,YOLOv12产生了更清晰的物体轮廓和更精确的前景激活,表明感知能力有所提高。作者的解释是,这种改善来自于Area Attention,它比卷积具有更大的接受野。

这个热图采用的是第三阶段的最后一层,详细请看作者解答:Clarification on CAM-Based Heatmap Generation for Each YOLO Version ? · Issue #74 · sunsmarterjie/yolov12 · GitHubHi, I’ve been reading your paper and I’m intrigued by the CAM-based method you used to generate heatmaps, especially how it is applied to different YOLO versions. I have a few questions to better understand the implementation details: He...![]() https://github.com/sunsmarterjie/yolov12/issues/74这是对特征图进行可视化的一个pytorch库——GRAD-CAM!GitHub - jacobgil/pytorch-grad-cam: Advanced AI Explainability for computer vision. Support for CNNs, Vision Transformers, Classification, Object detection, Segmentation, Image similarity and more.Advanced AI Explainability for computer vision. Support for CNNs, Vision Transformers, Classification, Object detection, Segmentation, Image similarity and more. - jacobgil/pytorch-grad-cam
https://github.com/sunsmarterjie/yolov12/issues/74这是对特征图进行可视化的一个pytorch库——GRAD-CAM!GitHub - jacobgil/pytorch-grad-cam: Advanced AI Explainability for computer vision. Support for CNNs, Vision Transformers, Classification, Object detection, Segmentation, Image similarity and more.Advanced AI Explainability for computer vision. Support for CNNs, Vision Transformers, Classification, Object detection, Segmentation, Image similarity and more. - jacobgil/pytorch-grad-cam![]() https://github.com/jacobgil/pytorch-grad-cam
https://github.com/jacobgil/pytorch-grad-cam
这是对一些网络进行详细讲解的内容地址,有兴趣可以去看看!
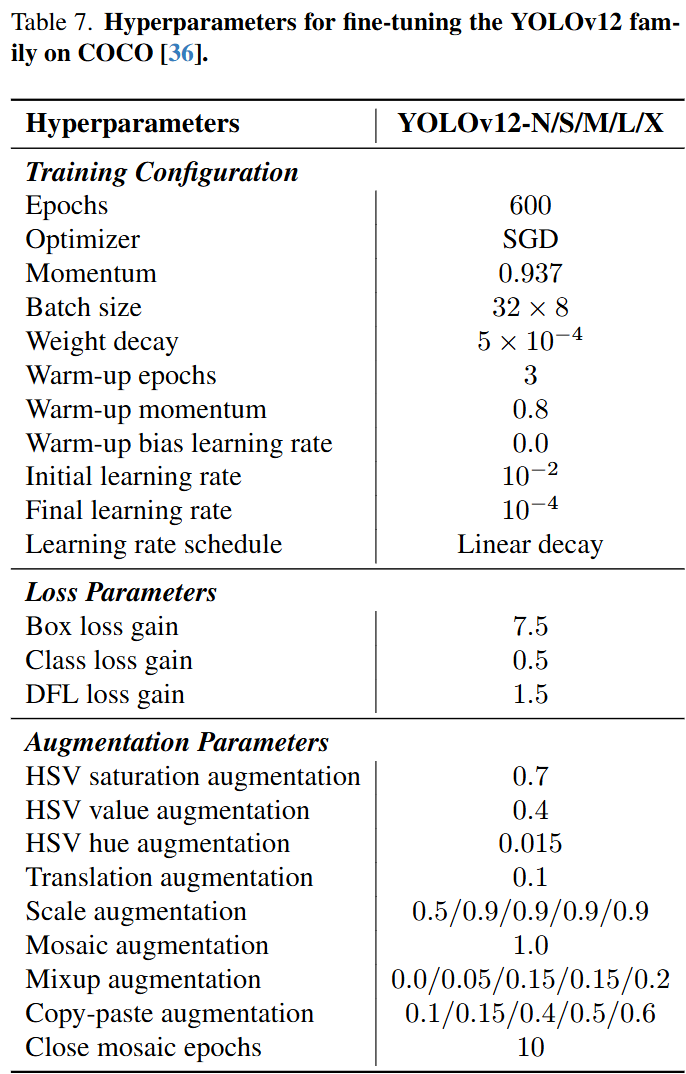
🎑超参数的设定:

















 1178
1178

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









