







索引对象
简单索引对象
pandas中,索引对象负责管理轴标签和其它元数据,Series和DataFrame的索引实际上都是Index对象。Series类和DataFrame类对象的index属性返回的就是索引对象,

Index对象形式上很像一个numpy的array,但是Index对象是不能修改的,下面这种试图直接修改Index对象的方式一定会报错,

不可修改的属性非常重要,因为不可修改,所以在多个数据结构之间能够安全共享,

Index类是最笼统的索引类,向下继承的还有多种Index类的子类,

索引对象简单运算
Index对象形式上像数组,但是不可改变。不可变的这一特性类似于Python内置类型的元组和集合。相应的运算也与集合类似,能够参与逻辑运算,

此外,不同索引对象之间的运算也与元组和集合很相近,

append和concat方法
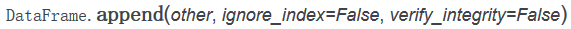
其中ignore_index如果为True,则不会使用之前的索引;如果verify_integrity为True,当出现重复索引时会报出ValueError的异常。
# -*- coding: utf-8 -*-
import pandas as pd
df = pd.DataFrame([[1, 2], [3, 4]], columns=list('AB')) #返回 A B
# 0 1 2
# 1 3 4
df2 = pd.DataFrame([[5, 6], [7, 8]], columns=list('AB'))
df.append(df2) #返回 A B 默认情况下会保留原来索引
# 0 1 2
# 1 3 4
# 0 5 6
# 1 7 8
# 如果 ignore_index=True
df.append(df2, ignore_index=True) #返回 A B 索引会自动顺延
# 0 1 2
# 1 3 4
# 2 5 6
# 3 7 8
但是在拼接DataFrame的时候,append方法的效率并不高,官方文档中推荐的方法是concat方法,
df = pd.DataFrame(columns=['A'])
pd.concat([pd.DataFrame([i], columns=['A']) for i in range(5)], ignore_index=True)
#返回 A
# 0 0
# 1 1
# 2 2
# 3 3
# 4 4
# 上面的concat实例理解为,
df1 = pd.DataFrame([1], columns=['A'])
df2 = pd.DataFrame([2], columns=['A'])
df3 = pd.DataFrame([3], columns=['A'])
df4 = pd.DataFrame([4], columns=['A'])
df5 = pd.DataFrame([5], columns=['A'])
pd.concat([df1,df2,df3,df4,df5])
difference、intersection和 union方法

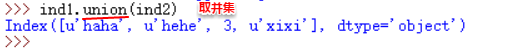
delete和insert方法
两个方法的一般使用格式,
# delete方法
Index.delete(loc)
# insert方法
Index.insert(loc, item)

drop方法
drop(item)
使用示例,

is_unique属性
索引值不唯一,但是可能包含不同的数据,此时操作起Series和Dataframe时,就需要注意错删的情况。


索引对象操作进阶
在实际的使用中,对于索引对象的操作远不止上面列出的那些,
重索引 reindex
使用的是reindex方法,这个方法很重要,创建的是一个使用新索引的新对象,reindex方法对于Series和DataFrame都适用。以官方文档中DataFrame的介绍为例,
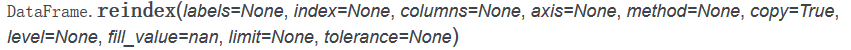
# -*- coding: utf-8 -*-
import pandas as pd
index = ['Firefox', 'Chrome', 'Safari', 'IE10', 'Konqueror']
df = pd.DataFrame({ 'http_status': [200,200,404,404,301],
'response_time': [0.04, 0.02, 0.07, 0.08, 1.0]},
index=index)
# 得到 http_status response_time
# Firefox 200 0.04
# Chrome 200 0.02
# Safari 404 0.07
# IE10 404 0.08
# Konqueror 301 1.00
new_index= ['Safari', 'Iceweasel', 'Comodo Dragon', 'IE10', 'Chrome']
df.reindex(new_index)
#返回 http_status response_time
# Safari 404.0 0.07
# Iceweasel NaN NaN
#Comodo Dragon NaN NaN
# IE10 404.0 0.08
# Chrome 200.0 0.02
# 会保留之前存在的索引,之前不存在的索引会使用缺失值进行替代
# 对缺失值进行填补可配合适用 fill_value方法,fill_value可以是任意类型的值
df.reindex(new_index, fill_value=0)
#返回 http_status response_time
# Safari 404.0 0.07
# Iceweasel 0 0
#Comodo Dragon 0 0
# IE10 404.0 0.08
# Chrome 200.0 0.02
date_index = pd.date_range('1/1/2010', periods=6, freq='D')
df2 = pd.DataFrame({"prices": [100, 101, np.nan, 100, 89, 88]}, index=date_index)
# 返回 prices
# 2010-01-01 100
# 2010-01-02 101
# 2010-01-03 NaN
# 2010-01-04 100
# 2010-01-05 89
# 2010-01-06 88
date_index2 = pd.date_range('12/29/2009', periods=10, freq='D')
df2.reindex(date_index2)
# 返回 prices
# 2009-12-29 NaN
# 2009-12-30 NaN
# 2009-12-31 NaN
# 2010-01-01 100
# 2010-01-02 101
# 2010-01-03 NaN
# 2010-01-04 100
# 2010-01-05 89
# 2010-01-06 88
df2.reindex(date_index2, method='bfill')
# 返回 prices
# 2009-12-29 100
# 2009-12-30 100
# 2009-12-31 100
# 2010-01-01 100
# 2010-01-02 101
# 2010-01-03 100
# 2010-01-04 100
# 2010-01-05 89
# 2010-01-06 88
# 使用columns参数则是替换之前的列名,
df.reindex(columns=['http_status', 'user_agent'])
#返回 http_status user_agent
# Safari 404.0 0.07
# Iceweasel 0 0
#Comodo Dragon 0 0
# IE10 404.0 0.08
# Chrome 200.0 0.02
#如果不使用上面的方式,可以通过axis参数传入 index或columns来指定替换行索引还是列索引
df.reindex(['http_status', 'user_agent'], axis="columns") #结果与上方相同
上面的演示中,除了用指定的值填补缺失值,method参数给出了几个选项,
default: don’t fill gaps
pad / ffill: propagate last valid observation forward to next valid,用前放实测值填补
backfill / bfill: use next valid observation to fill gap,后方的实测值填补
nearest: use nearest valid observations to fill gap,最近的实测值填补
上面的操作都是针对整个DataFrame的索引进行的,pandas模块也同样支持对部分索引进行操作,需要与ix属性配合使用,



之前不存在的列会使用缺失值进行填补。
Series和DataFrame的索引操作
Series索引
Series的一系列操作较为简单,因为Series的结构可以看做是一个一维数组,

Series使用索引对象进行切片,与平时编程语言的切片是不同的,包含头,也包含尾,
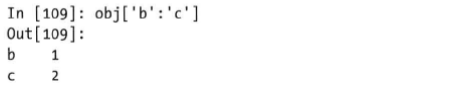
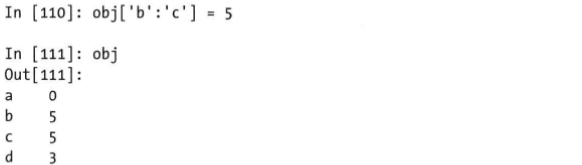
DataFrame索引
DataFrame的索引操作比较复杂,因为有行索引和列索引,

DataFrame的切片操作也涉及到两个维度,

117行代码是选取three这列大于5的全部的行。
通过索引定位(loc、iloc和ix、xs方法)
对上面的三种方法进行区分,首先参考官方文档的说明,

| 方法名 | 说明 |
|---|---|
| loc | 通过行标签索引行数据 |
| iloc | 通过行号索引行数据 |
| ix | 通过行标签或者行号索引行数据(基于loc和iloc 的混合),ix是最为常用的。 |
| xs | 选取单行或单列 |
四个方法中,xs方法由于涉及到行列操作,所以对其进行特别说明,

#现在有个DataFrame df
# A B C
# a 4 5 2
# b 4 0 9
# c 9 7 3
df.xs('a')
# 返回 A 4 axis=0取回的是指定的行
# B 5
# C 2
# Name: a
df.xs('C', axis=1)
# 返回 a 2 axis=1取回的是指定的列
# b 9
# c 3
# Name: C
索引排序(sort_index方法)
使用的是sort_index方法,该方法返回的是已排序的新对象,
Series索引排序
Series索引排序,方式很简单,因为只有一个维度,

DataFrame索引排序
Dataframe索引排序涉及到两个维度,可以使用axis参数进行指定,
| axis参数值 | 排序对象 |
|---|---|
| axis=0 | 行索引排序 |
| axis=1 | 列索引排序 |

sort_index方法默认是升序排列,如果需要降序,可以指定 asending参数为False。
















 2378
2378











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









