







Autograd
Pytorch中神经网络包中最核心的是autograd包,autograd包为所有在tensor上的运算提供了自动求导的支持,这是一个逐步运行的框架,也就意味着后向传播过程是按照你的代码定义的,并且单个循环可以不同
- autograd.Variable 是autograd中最核心的类,它包装了一个Tensor,并且几乎支持所有在其上定义的操作。一旦完成了你的运算,你可以调用 .backward()来自动计算出所有的梯度。
- 如果Variable是标量(即它保存一个元素数据),则不需要指定任何参数backward(),但是如果它具有更多元素,则需要指定一个grad_output 作为匹配形状的张量的参数。
- Function也对autograd的实现非常重要。
Variable 和Function数是相互关联的,并建立一个非循环图,从而编码完整的计算过程。每个变量都有一个.grad_fn属性引用创建变量的函数(除了用户创建的变量,它们的grad_fn是None)。
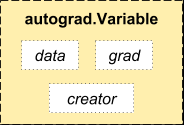
- Variable 中有三个属性:data,grad以及creator。
访问原始的 tensor使用属性.data; 而Variable的梯度则集中于 .grad; .creator反映了创建者,标识了是否由用户使用.Variable直接创建
- 代码示例(均在jupyter notebook中运行)
x = torch.randn(3,4,requires_grad = Ture)
x
tensor([[ 0.9811, -0.2472, 0.7087, 0.4421],
[ 0.1673, 0.4379, -0.6533, 0.1763],
[ 0.1237, -1.2269, 0.4307, -0.7825]], requires_grad=True)
指定.requires_grads为True,autograd就会开始跟踪上面的所有运算
b = torch.randn(3,4,requires_grad = Ture)
t = x + b
y = t.sum()
y
tensor(8.3622, grad_fn=< SumBackward0>)
y是变量Variable x进行sum操作求来的,但是这个时候y.grad是没有返回值的,因为没有使用y进行别的操作
y.backward()
b.grad
tensor([[1., 1., 1., 1.],
[1., 1., 1., 1.],
[1., 1., 1., 1.]])
x.requires_grad,b.requires_grad,t.requires_grad
(True, True, True) ; 因为开始的时候指定了X的requires_grad = Ture,
线性回归模型示例
import torch
import torch.nn as nn
import numpy as np
class LinearRegressionModel(nn.Module):
def __init__(self,input_dim,output_dim):
super(LinearRegressionModel,self).__init__()
self.Linear = nn.Linear(input_dim,output_dim)
def forward(self,x):
out = self.Linear(x)
return out
input_dim = 1
output_dim = 1
model = LinearRegressionModel(input_dim,output_dim)
device = torch.device("cuda:0" if torch.cuda.is_available() else "CPU")
model.to(device)
criterion = nn.MSELoss() #定义损失函数
learning_rate = 0.01 #指定学习率
optimizer = torch.optim.SGD(model.parameters(),lr = learning_rate) #指定优化器
epochs = 1000 #训练次数
for epoch in range(epochs):
epoch += 1
inputs = torch.from_numpy(x_train).to(device) #转array格式为 tensor
labels = torch.from_numpy(y_train).to(device)
optimizer.zero_grad() #梯度清零
outputs = model(inputs) #前向传播
loss = criterion(outputs,labels) #计算损失
loss.backward() #反向传播
optimizer.step() #更新权重参数
if epoch % 50 == 0:
print('epoch {},loss {}'.format(epoch, loss.item()))















 1358
1358











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









