







简介
通过模仿人脑的处理机制建立接近(乃至超越)人类智能的机器,一直是人们的一个朴素理念
(1) 符号主义(Symbolism),又称逻辑主义、心理学派或计算机学派,是指通过分析人类智能的功能,后用计算机来实现
这些功能的一类方法.
• 符号主义有两个基本假设:
Ø a)信息可以用符号来表示;
Ø b)符号可以通过显式的规则 (比如逻辑运算)来操作.
• 人类的认知过程可以看作符号操作过程.
Ø 在人工智能的推理期和知识期,符号主义的方法比较盛行,并取得了大量的成果.
• (2) 连接主义(Connectionism),又称仿生学派或生理学派,是认知科学领域中的一类信息处理的方法和理论.
Ø 在认知科学领域,人类的认知过程可以看作一种信息处理过程.连接主义认为人类的认知过程是由大量简单神经元构成 的神经网络中的信息处理过程,而不是符号运算.
主要结构是大量简单处理单元组成的互联网络
非线性、分布式、并行化、局部性计算和自适应性等特征
“神经网络是由具有适应性的简单单元组成的广泛并行互联的网络, 它的组织能够模拟生物神经系统对真实世界物体所作出的反应”
由大量的神经元以及它们之间的有向连接构成:
• 神经元的激活规则
Ø 主要是指神经元输入到输出之间的映射关系,一般为非线性函数。
• 网络的拓扑结构
Ø 不同神经元之间的连接关系。
• 学习算法
Ø 通过训练数据来学习神经网络的参数。
神经网络是一种大规模的并行分布式处理器,天然具有存储并使用经验知识的能力.
• 从两个方面上模拟大脑:
Ø (1)网络 获取的知识是通过学习来获取的;
Ø (2)内部神经元的连接强度, 即突触权重,用于储存获取的知识.
早期的突破来自麦卡洛克(McCulloch)与皮茨(Pitts),他们于1943年首次提
出了单个神经元的McCulloch-Pitts计算模型,此模型作为构建人工神经网
络的基础单元一直沿用至今。
•**输入:**来自其他n嘅神经元传递过来的输入信号
•**处理:**输入信号通过带权重的连接进行传递,神经元接收到总输入值将和神经元的阈值进行比较
**输出:**通过激活函数的处理来得到输出
典型的激活函数
•理想的激活函数是阶跃函数,0表示抑制神经元,1表示激活神经元
典型例子:sgn(x)
•阶跃函数具有不连续、不光滑的性质,更常用的是Sigmoid函数
S
i
g
m
o
i
d
(
x
)
=
1
1
+
e
−
x
Sigmoid(x) = \frac{1}{1+e^{-x}}
Sigmoid(x)=1+e−x1
感知器(Perceptron)
Ø 模拟生物神经元行为的机器,有与生物神经元相对应的部件,由两层神经元组成, 输入层接受外界输入信号传递给输出层, 输出层是M-P神经元
(阈值逻辑单元)
Ø 结构包括权重(突触)、偏置(阈值)及激活函数(细胞体),输出为+1或-1。
罗森布拉特(Frank Rosenblatt)在1958年利用McCulloch-Pitts模型建立了
首个神经网络模型“感知机”,成功应用于线性可分的模式识别问题求解
,后续还研制了用硬件实现感知机原理的神经计算机,从而开创了模仿大
脑神经系统的人工智能联结主义学派。
• 感知机能够容易地实现逻辑与、或、非运算
与运算
x 1 ∧ x 2 x_1\land x_2 x1∧x2 让 w 1 = w 2 = 1 , θ = 0 , y = f ( 1 ⋅ x 1 + 1 ⋅ x 2 − 2 ) w_1=w_2 = 1,\theta = 0,y=f(1\cdot x_1 + 1\cdot x_2-2) w1=w2=1,θ=0,y=f(1⋅x1+1⋅x2−2)仅在 x 1 = x 2 = 1 x_1=x_2 = 1 x1=x2=1的时候 y = 1 y=1 y=1
x 1 ∨ x 2 x_1\lor x_2 x1∨x2 让 w 1 = w 2 = 1 , θ = 0.5 , y = f ( 1 ⋅ x 1 + 1 ⋅ x 2 − 0.5 ) w_1=w_2 = 1,\theta = 0.5,y=f(1\cdot x_1 + 1\cdot x_2-0.5) w1=w2=1,θ=0.5,y=f(1⋅x1+1⋅x2−0.5)仅在 x 1 = 1 或 x 2 = 1 x_1=1或x_2 = 1 x1=1或x2=1的时候 y = 1 y=1 y=1
¬ x 1 , 令 w 1 = − 0.6 , w 2 = 0 , θ = − 0.5. 则当 x 1 = 1 , y = 0 , x 1 = 0 , y = 1 \lnot x_1,令w_1=-0.6, w_2=0,\theta = -0.5.则当x_1=1,y=0,x_1 = 0,y=1 ¬x1,令w1=−0.6,w2=0,θ=−0.5.则当x1=1,y=0,x1=0,y=1

给定训练之,权重
w
i
(
i
=
1
,
2
…
…
n
)
w_i(i=1,2……n)
wi(i=1,2……n)与阈值\theta可以通过学习得到
c
o
s
t
=
−
∑
i
∈
M
y
i
(
∑
j
=
0
M
w
j
x
i
,
j
)
cost = -\sum_{i\in M}y_i(\sum^M_{j=0}w_jx_{i,j})
cost=−i∈M∑yi(j=0∑Mwjxi,j)
对训练样例
(
x
,
y
)
(x,y)
(x,y),若当前感知机的输出
y
^
\hat{y}
y^则感知机权重调整规则为
w
i
←
w
i
+
Δ
w
i
w_i\leftarrow w_i+\Delta w_i
wi←wi+Δwi
Δ
w
i
=
η
(
y
−
y
^
)
x
i
\Delta w_i = \eta(y-\hat{y})x_i
Δwi=η(y−y^)xi
其中
η
∈
(
0
,
1
)
\eta\in(0,1)
η∈(0,1)为学习率


l 若两类模式线性可分, 则感知机的学习过程一定会收敛;否感知机的学习过程将会发生震荡
l 单层神经网路不能解决非线性问题, 多层网络的训练算法尚无希望. 这个论断导致神经网络进入低谷
多层感知器
l 单层感知机的学习能力非常有限, 只能解决线性可分问题
l 与、或、非问题是线性可分的, 因此感知机学习过程能够求得适当的权值向量. 而异或问题不是线性可分的, 感知机学习不能求得合适解
l 对于非线性可分问题, 如何求解?
• 输出层与输入层之间的一层神经元, 被称之为隐层或隐含层, 隐含层和输出层神经元都是具有激活函数的功能神经元
前馈神经网络(全连接神经网络、多层感知器)
Ø 各神经元分别属于不同的层,层内无连接。
Ø 相邻两层之间的神经元全部两两连接。
Ø 整个网络中无反馈,信号从输入层向输出层单向传播,可用一个有向无环图表示。
激活函数的性质
• 连续并可导(允许少数点上不可导)的非线性函数。
Ø 可导的激活函数可以直接利用数值优化的方法来学习网络参数。
• 激活函数及其导函数要尽可能的简单
Ø 有利于提高网络计算效率。
• 激活函数的导函数的值域要在一个合适的区间内
Ø 不能太大也不能太小,否则会影响训练的效率和稳定性。
• 单调递增
(误差)反向传播算法
最成功、最常用的神经网络算法,可被用于多种任务(不仅限于分类)
神经网络是一个复杂的复合函数
t
=
f
5
(
f
4
(
f
3
(
f
2
(
f
(
x
)
)
)
)
)
→
∂
y
∂
x
=
∂
f
∂
x
∂
f
2
∂
f
∂
f
3
∂
f
2
∂
f
4
∂
f
3
∂
f
5
∂
f
4
t=f^5(f^4(f^3(f^2(f(x))))) \rightarrow \frac{\partial y}{\partial x} = \frac{\partial f}{\partial x}\frac{\partial f^2}{\partial f}\frac{\partial f^3}{\partial f^2}\frac{\partial f^4}{\partial f^3}\frac{\partial f^5}{\partial f^4}
t=f5(f4(f3(f2(f(x)))))→∂x∂y=∂x∂f∂f∂f2∂f2∂f3∂f3∂f4∂f4∂f5
链式法则(Chain Rule)是在微积分中求复合函数导数的一种常用方法。

Why is the backpropagation algorithm efficient?
Ø Reuses computation from the forward pass in the backward pass
Ø Reuses partial derivatives throughout the backward pass (but only if the algorithm reuses shared computation in the forward pass)

具体操作
给定训练集
D
=
{
(
x
1
,
y
1
)
,
…
…
(
x
m
,
y
m
)
}
D = \{(x_1,y_1),……(x_m,y_m)\}
D={(x1,y1),……(xm,ym)}
输入d维特征向量
输出l个输出值
隐层:假定使用q个隐层神经元
假定功能单元都是用
S
i
g
m
o
i
d
Sigmoid
Sigmoid函数

对于训练的一个例子
(
x
k
,
y
k
)
(x_k,y_k)
(xk,yk),假定实际输出为
y
k
^
=
(
y
^
1
k
…
…
y
^
l
k
)
\hat{y_k} = (\hat{y}_1^k……\hat{y}_l^k)
yk^=(y^1k……y^lk)
y
^
j
k
=
f
(
β
j
−
θ
j
)
\hat{y}^k_j=f(\beta_j-\theta_j)
y^jk=f(βj−θj)
通过学习确定参数数目
(
d
+
l
+
1
)
q
+
l
(d+l+1)q+l
(d+l+1)q+l
BP是一个迭代学习算法,每一轮坐如下误差修正
v
←
v
+
Δ
v
v\leftarrow v + \Delta v
v←v+Δv
以
w
h
i
w_{hi}
whi作为例子
对于误差
E
k
E_k
Ek给定学习率
η
\eta
η有
Δ
w
h
j
=
−
η
∂
E
k
∂
w
h
i
\Delta w_{hj}=-\eta\frac{\partial E_k}{\partial w_{hi}}
Δwhj=−η∂whi∂Ek
注意到
w
h
i
w_{hi}
whi先影响
β
j
\beta_j
βj
再影响到
y
^
j
k
\hat{y}^k_j
y^jk,然后再影响到
E
k
E_k
Ek,有
∂
E
k
∂
w
h
i
=
∂
E
k
∂
y
^
j
k
∂
y
^
j
k
∂
β
j
∂
β
j
∂
w
h
i
\frac{\partial E_k}{\partial w_{hi}} = \frac{\partial E_k}{\partial \hat{y}^k_j}\frac{\partial \hat{y}^k_j}{\partial \beta_j}\frac{\partial \beta_j}{\partial w_{hi}}
∂whi∂Ek=∂y^jk∂Ek∂βj∂y^jk∂whi∂βj

类似的
Δ
θ
j
=
−
η
g
j
Δ
v
i
j
=
η
e
h
x
i
Δ
γ
h
=
−
η
e
h
\Delta\theta_j = -\eta g_j \\ \Delta v_{ij} = \eta e_h x_i\\ \Delta \gamma_h = -\eta e_h
Δθj=−ηgjΔvij=ηehxiΔγh=−ηeh


神经网络样例
#include "bits/stdc++.h"
using namespace std;
double mseLoss(double x, double target) {
return 0.5 * (x - target) * (x - target);
}
struct NeuralNetwork {
vector<double*> values, caches;
vector<double**> weights;
};
void standardize(double **data, int dataSize, int featureSize) {
for (int j = 0; j <= featureSize; ++j) {
double mean = 0;
for (int i = 0; i < dataSize; ++i)
mean += data[i][j] / dataSize;
double variance = 0;
for (int i = 0; i < dataSize; ++i)
variance += (data[i][j] - mean) * (data[i][j] - mean) / (dataSize - 1);
for (int i = 0; i < dataSize; ++i)
data[i][j] = (data[i][j] - mean) / sqrt(variance);
}
}
pair<vector<double*>, vector<double*>> make_dataset(int dataSize, int featureNum) {
double **data = (double**)malloc(dataSize * sizeof(double*));
for (int i = 0; i < dataSize; ++i) {
data[i] = (double*)malloc((featureNum + 2) * sizeof(double));
data[i][0] = 0;
for (int j = 0; j <= featureNum; ++j)
scanf("%lf", &data[i][j]);
}
standardize(data, dataSize, featureNum);
for (int i = 0; i < dataSize; ++i) {
data[i][featureNum + 1] = data[i][featureNum];
data[i][featureNum] = 1; // 偏置项
}
int trainSize = 0.8 * dataSize;
vector<int> index(dataSize);
for (int i = 0; i < dataSize; ++i)
index[i] = i;
random_shuffle(index.begin(), index.end());
vector<double*> train, valid;
for (int i = 0; i < trainSize; ++i)
train.push_back(data[index[i]]);
for (int i = trainSize; i < dataSize; ++i)
valid.push_back(data[index[i]]);
return make_pair(train, valid);
}
NeuralNetwork initNeuralNetwork() {
uniform_real_distribution<> random{-1, 1};
default_random_engine eng{0};
NeuralNetwork network{};
double **weight = (double**)malloc(14 * sizeof(double*));
for (int i = 0; i < 14; ++i) {
weight[i] = (double*)malloc(3 * sizeof(double));
for (int j = 0; j < 3; ++j)
weight[i][j] = random(eng);
}
network.weights.push_back(weight);
weight = (double**)malloc(3 * sizeof(double*));
for (int i = 0; i < 3; ++i) {
weight[i] = (double*)malloc(sizeof(double));
for (int j = 0; j < 1; ++j)
weight[i][j] = random(eng);
}
network.weights.push_back(weight);
return network;
}
// 你的代码会被嵌入在这
double evaluate(NeuralNetwork &network, vector<double*> &valid, int featureNum) {
double loss = 0;
for (int i = 0; i < valid.size(); ++i) {
double output = forward(network, valid[i]);
loss += mseLoss(output, valid[i][featureNum + 1]);
}
return loss / valid.size();
}
int main() {
int dataSize, featureNum;
scanf("%d%d", &dataSize, &featureNum);
auto pair = make_dataset(dataSize, featureNum);
auto train = pair.first, valid = pair.second;
uniform_int_distribution<int> random{0, (int)train.size() - 1};
default_random_engine eng{0};
auto network = initNeuralNetwork();
for (int i = 0; i < 10000; ++i) {
int idx = random(eng);
double output = forward(network, train[idx]);
backward(network, output, train[idx][featureNum + 1]);
step(network, 0.01);
}
printf("%lf\n", evaluate(network, valid, featureNum));
return 0;
}
思路
这个ppt写的也太抽象了。。。
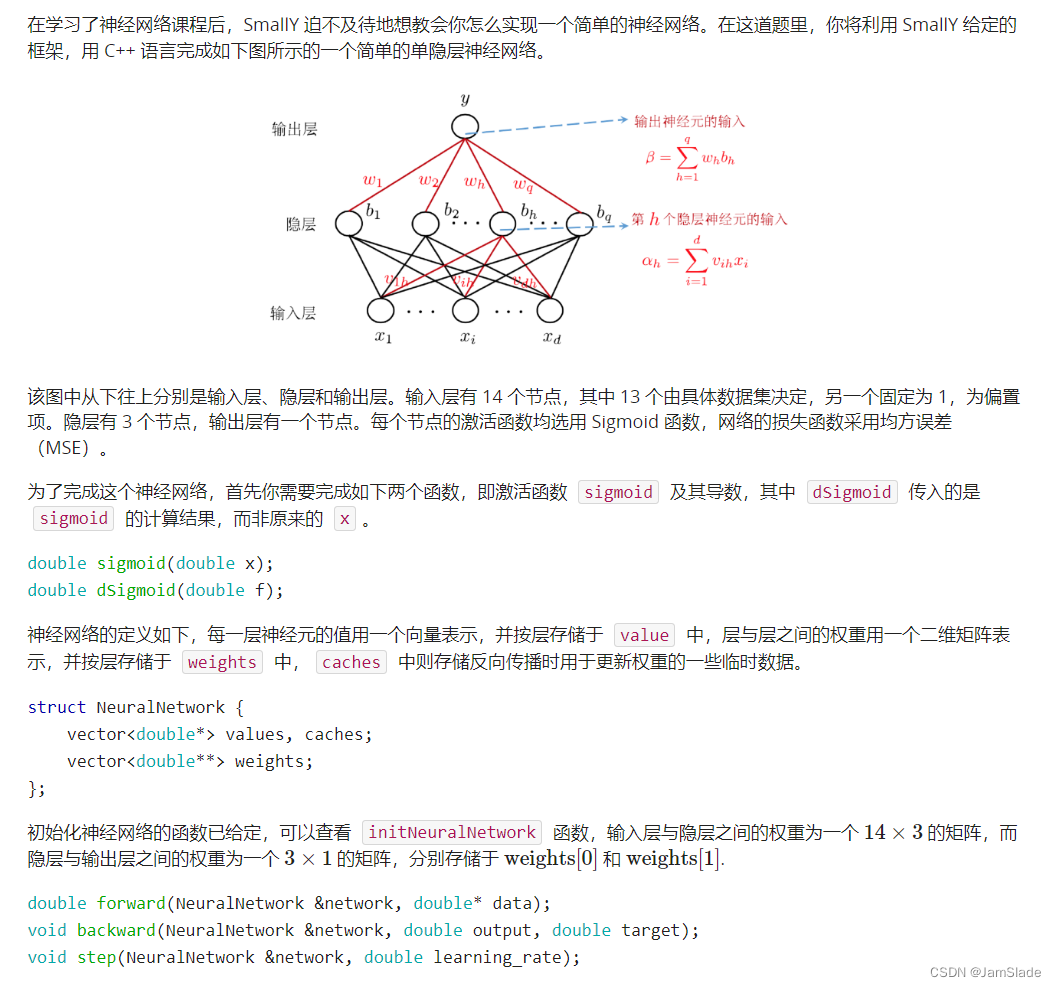
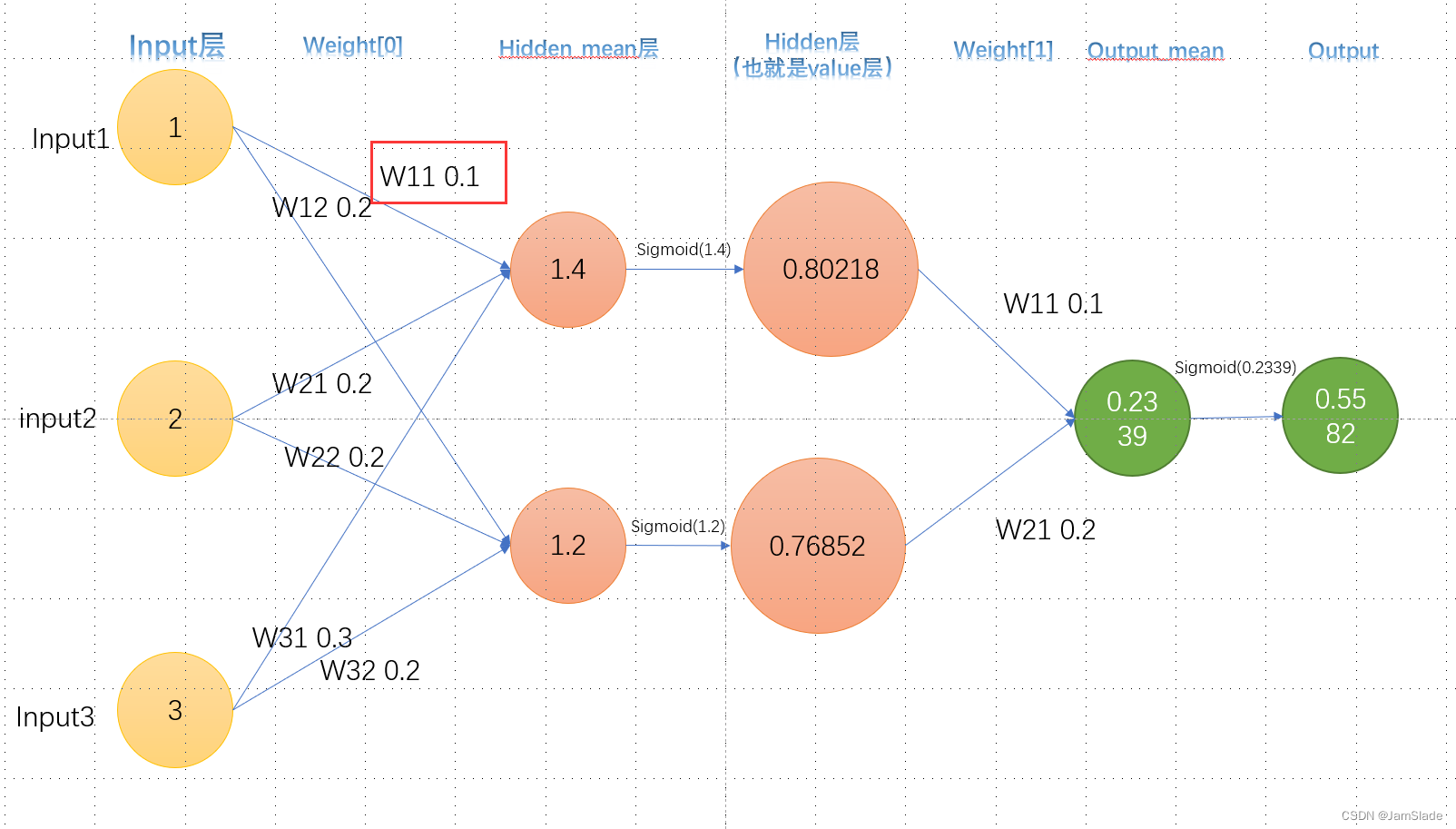
向前
input 加权得到隐藏层的数据
比如input
1
,
2
,
3
1,2,3
1,2,3
隐藏层第一个点权分别是
0.1
,
0.2
,
0.3
0.1,0.2,0.3
0.1,0.2,0.3
第二个点的权是
0.2
,
0.2
,
0.2
0.2,0.2,0.2
0.2,0.2,0.2
于是就有第一个点加权和为
1
×
0.1
+
2
×
0.2
+
3
×
0.3
=
1.4
1\times 0.1 + 2\times 0.2 + 3\times 0.3 = 1.4
1×0.1+2×0.2+3×0.3=1.4
第二个点加权和
1
×
0.2
+
2
×
0.2
+
3
×
0.2
=
1.2
1\times 0.2 + 2\times 0.2 + 3\times 0.2 = 1.2
1×0.2+2×0.2+3×0.2=1.2
第一个点最后的输出要经过sigmoid函数激活
o
u
t
1
=
1
1
+
e
−
1.4
out_1 = \frac{1}{1+e^{-1.4}}
out1=1+e−1.41
同理
o
u
t
2
=
1
1
+
e
−
1.2
out_2 = \frac{1}{1+e^{-1.2}}
out2=1+e−1.21
然后拿这两个输出再进行加权和得到最终的output加权
o
u
t
p
u
t
加权
=
o
u
t
1
×
w
e
i
g
h
t
1
+
o
u
t
p
u
t
2
×
w
e
i
g
h
t
2
output_{加权} = out_1\times weight_1+output_2\times weight_2
output加权=out1×weight1+output2×weight2
o
u
t
p
u
t
f
i
n
a
l
=
o
u
t
1
=
1
1
+
e
o
u
t
p
u
t
加权
output_{final} =out_1 = \frac{1}{1+e^{output_{加权}}}
outputfinal=out1=1+eoutput加权1
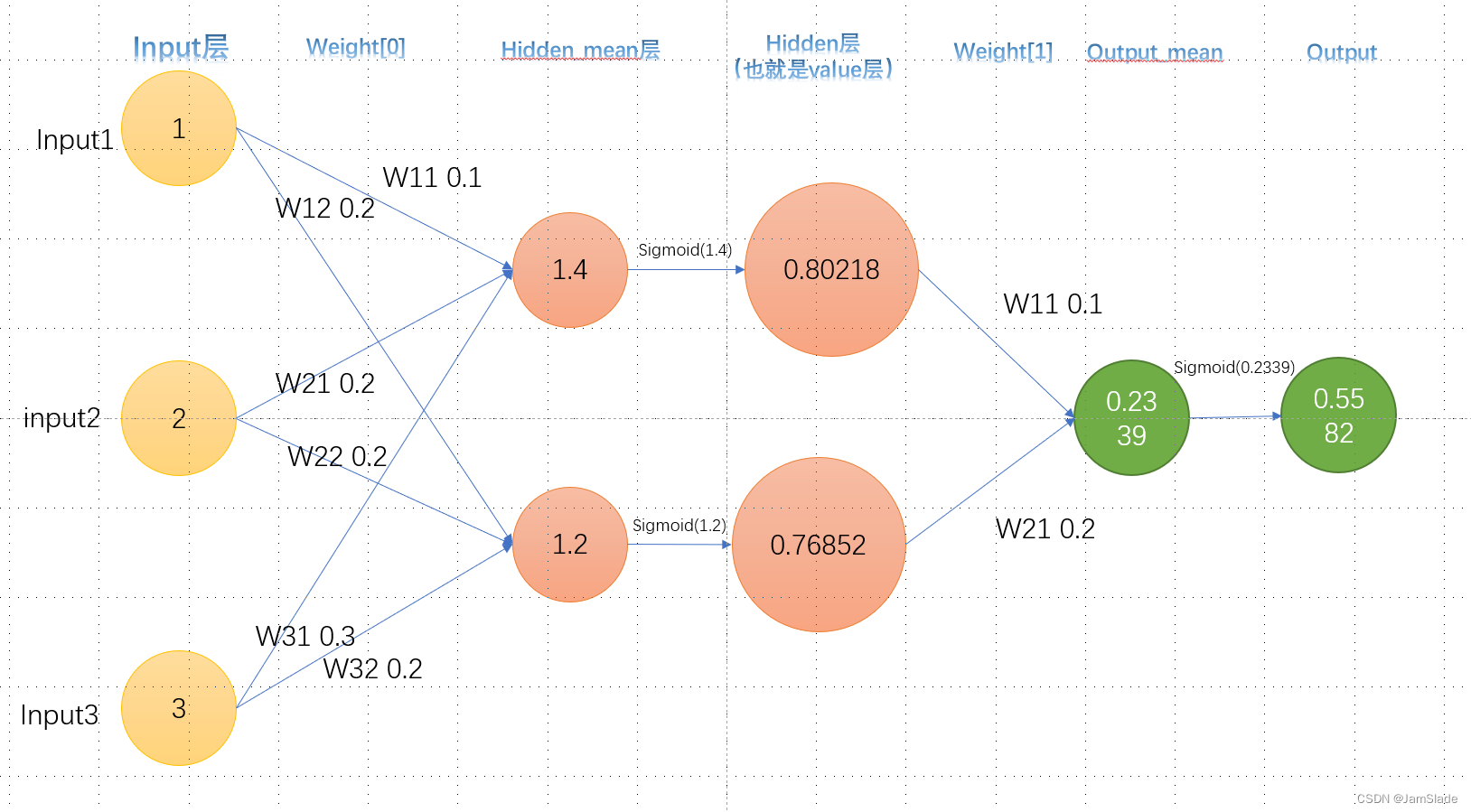
在forward里面,我们需要保留的是input层,hidden层和output层,也就是第一列,第三列和第五列
向后
backward部分由于要找到每个weight 对于output和target的差距的影响
【这里用的是mseLoss函数,就是求output到target距离的一半大小】
要对每个对应的权求微分
如何求呢?
我们从近的开始求
hidden层的weight变化
不妨叫这个红色部分的W21为
W
121
:
在
w
e
i
g
h
t
1
下的第
2
个
h
i
d
d
e
n
对第
1
个
o
u
t
p
u
t
W_{121}:在weight1下的第2个hidden对第1个output
W121:在weight1下的第2个hidden对第1个output
我们就是要求
∂
L
o
s
s
∂
W
121
\frac{\partial Loss}{\partial W_{121}}
∂W121∂Loss
Loss是output(在这个图里面就是最后的0.5582)和目标输出的差距
L
o
s
s
=
1
2
(
t
a
r
g
e
t
−
O
)
2
Loss = \frac{1}{2}( target - O)^2
Loss=21(target−O)2
根据链式求导法则我们可以展开
∂
L
o
s
s
∂
W
121
=
∂
L
o
s
s
∂
O
∂
O
∂
O
m
e
a
n
∂
O
m
e
a
n
∂
W
121
\frac{\partial Loss}{\partial W_{121}}=\frac{\partial Loss}{\partial O}\frac{\partial O}{\partial O_{mean}}\frac{\partial O_{mean}}{\partial W_{121}}
∂W121∂Loss=∂O∂Loss∂Omean∂O∂W121∂Omean
这里做如下解释
- Loss就是上文公式,对O求导得到 ( O − t a r g e t ) (O-target) (O−target)
- O就是第五列的输出,而
O
m
e
a
n
O_{ mean}
Omean指的是第四列,实际上就是对
S
i
g
m
o
i
d
(
O
)
Sigmoid(O)
Sigmoid(O)里面对O求导
∂
S
i
g
m
o
i
d
(
O
)
∂
O
=
S
i
g
m
o
i
d
(
O
)
×
(
1
−
S
i
g
m
o
i
d
(
O
)
)
\frac{\partial Sigmoid(O)}{\partial O} = Sigmoid(O)\times(1-Sigmoid(O))
∂O∂Sigmoid(O)=Sigmoid(O)×(1−Sigmoid(O))
3. O m e a n = H 1 × W 111 + H 2 × W 121 O_{mean} = H_1\times W_{111}+H_2\times W_{121} Omean=H1×W111+H2×W121,所以对Weight求导就是H2了
对应MseLoss的导数以及下图的两个部分
这样我们把上面的式子相乘就可以求
∂
L
o
s
s
∂
W
121
\frac{\partial Loss}{\partial W_{121}}
∂W121∂Loss
然后我们对这一个
W
121
W_{121}
W121进行相减操作
W
121
=
W
121
−
η
∂
L
o
s
s
∂
W
121
W_{121} = W_{121}-\eta\frac{\partial Loss}{\partial W_{121}}
W121=W121−η∂W121∂Loss
其中
η
\eta
η是学习速率,自己定义即可
input的weight变化
接下来求
W
011
W_{011}
W011
∂
L
o
s
s
∂
W
011
=
∂
L
o
s
s
∂
H
1
∂
H
1
∂
H
m
e
a
n
∂
H
m
e
a
n
∂
W
011
=
∂
L
o
s
s
∂
O
∂
O
∂
O
m
e
a
n
∂
O
m
e
a
n
∂
H
1
∂
H
1
∂
H
m
e
a
n
∂
H
m
e
a
n
∂
W
011
\left.\begin{aligned}\frac{\partial Loss}{\partial W_{011}} &=\frac{\partial Loss}{\partial H_1}\frac{\partial H_1}{\partial H_{mean}}\frac{\partial H_{mean}}{\partial W_{011}}\\ &=\frac{\partial Loss}{\partial O}\frac{\partial O}{\partial O_{mean}}\frac{\partial O_{mean}}{\partial H_1}\frac{\partial H_1}{\partial H_{mean}}\frac{\partial H_{mean}}{\partial W_{011}} \end{aligned}\right.
∂W011∂Loss=∂H1∂Loss∂Hmean∂H1∂W011∂Hmean=∂O∂Loss∂Omean∂O∂H1∂Omean∂Hmean∂H1∂W011∂Hmean
对应为MseLoss的求导和下图的4个部分

从左到右分别是【可以自己求一下偏导试试】
- o u t p u t − t a g e r t output - tagert output−tagert
- S i g m o i d ( O m e a n ) × ( 1 − S i g m o i d ( O m e a n ) ) Sigmoid(O_{mean})\times(1-Sigmoid(O_{mean})) Sigmoid(Omean)×(1−Sigmoid(Omean))
- W 111 W_{111} W111
- S i g m o i d ( H m e a n ) × ( 1 − S i g m o i d ( H m e a n ) ) Sigmoid(H_{mean})\times(1-Sigmoid(H_{mean})) Sigmoid(Hmean)×(1−Sigmoid(Hmean))
- i n p u t 1 input_1 input1
output不止一种的情况
如果最终输出output不止一个,对于第二种情况来说要求的偏导会稍微麻烦一点可以参考这篇文章
一文弄懂神经网络中的反向传播法——BackPropagation
代码
double sigmoid(double x);
double dSigmoid(double f);
double forward(NeuralNetwork &network, double* data);
void backward(NeuralNetwork &network, double output, double target);
void step(NeuralNetwork &network, double learning_rate);
double sigmoid(double x)
{
return (1/(1+exp(-x)));
}
double dSigmoid(double f)
{
return f*(1-f);
}
double forward(NeuralNetwork &network, double* data)
{
network.values.clear();
double* input = new double[14];
double* sig_hidden = new double[3];
double* sig_output = new double[1];
for(int i = 0; i < 14; i++)
input[i] = data[i];
double** dp = network.weights[0];
for(int i = 0; i < 3; i++)
{
double ave_sum = 0.0;
for(int j = 0; j < 14; j++)
{
ave_sum += dp[j][i] * input[j];
}
sig_hidden[i] = sigmoid(ave_sum);
}
dp = network.weights[1];
for(int i = 0; i < 1; i++)
{
double ave_sum = 0.0;
for(int j = 0; j < 3; j++)
{
ave_sum += dp[j][i] * sig_hidden[j];
}
sig_output[i] = sigmoid(ave_sum);
}
network.values.push_back(input);
network.values.push_back(sig_hidden);
network.values.push_back(sig_output);
return sig_output[0];
}
void backward(NeuralNetwork &network, double output, double target)
{
network.caches.clear();
double* pEloss_pOut_pAve = new double[1];
double* pEloss_pOut_pAve_pHid_pAveHid = new double[3];
pEloss_pOut_pAve[0] = (output - target) * dSigmoid(output);
double** dp = network.weights[1];
double* hid = network.values[1];
for(int i = 0; i < 3; i++)
{
pEloss_pOut_pAve_pHid_pAveHid[i] = pEloss_pOut_pAve[0] \
* dp[i][0] * dSigmoid(hid[i]);
}
network.caches.push_back(pEloss_pOut_pAve);
network.caches.push_back(pEloss_pOut_pAve_pHid_pAveHid);
}
void step(NeuralNetwork &network, double learning_rate)
{
for(int i = 0; i < 3; i++)
network.weights[1][i][0] -= learning_rate * network.caches[0][0] * network.values[1][i];
for(int i = 0; i < 13; i++)
for(int j = 0; j < 3; j++)
network.weights[0][i][j] -= learning_rate * network.caches[1][j] * network.values[0][i];
for(int i = 13; i < 14; i++)
for(int j = 0; j < 3; j++)
network.weights[0][i][j] += learning_rate * network.caches[1][j] * network.values[0][i];
// 需要的是针对第13项(偏置项)需要特殊处理一下,把-=变成+=
// 如果不改的话其实单纯调参(修改learning rate)也是可行的
return;
}
细节修改版
#include<bits/stdc++.h>
using namespace std;
struct NeuralNetwork {
vector<double*> values, caches;
vector<double**> weights;
};
double sigmoid(double x);
double dSigmoid(double f);
double forward(NeuralNetwork &network, double* data);
void backward(NeuralNetwork &network, double output, double target);
void step(NeuralNetwork &network, double learning_rate);
double sigmoid(double x)
{
return (1 /(1 + exp(-x)));
}
double dSigmoid(double f)
{
return f*(1-f);
}
double forward(NeuralNetwork &network, double* data)
{
network.values.clear();
double* input = new double[14];
double* sig_hidden = new double[3];
double* sig_out = new double[1];
for(int i = 0; i < 14; i++)
input[i] = data[i];
double** dp = network.weights[0];
for(int j = 0; j < 3; j++)
{
double SUM = 0.0;
for(int i = 0; i < 14; i++)
{
SUM += dp[i][j] * data[i];
}
sig_hidden[j] = sigmoid(SUM);
}
dp = network.weights[1];
for(int j = 0; j < 1; j++)
{
double SUM = 0.0;
for(int i = 0; i < 3; i++)
{
SUM += dp[i][j] * sig_hidden[i];
}
sig_out[0] = sigmoid(SUM);
}
network.values.push_back(input);
network.values.push_back(sig_hidden);
network.values.push_back(sig_out);
return network.values[2][0];
}
void backward(NeuralNetwork &network, double output, double target)
{
network.caches.clear();
double* temp1 = new double[1];
double* temp2 = new double[1];
double* temp3 = new double[3];
double* temp4 = new double[3];
double* temp5 = new double[14];
double* temp__ = new double[3];
// 第一步,获得mseLoss对 output的求导
temp1[1] = network.values[2][0] - target;
// 第二,获取sig_output的导数
temp2[1] = dSigmoid(network.values[2][0]);
//第三,获取sig_output对三个sig_hidden对应的权的求导
for(int i = 0; i < 3; i++)
{
temp3[i] = network.values[1][i];
//也就是sig_hidden
}
//插入一步 获取权
for(int i = 0; i < 3; i++)
{
temp__[i] = network.weights[1][i][0];
//也就是sig_hidden
}
//第四 获取sig_hidden的导数
for(int i = 0; i < 3; i++)
{
temp4[i] = dSigmoid(network.values[1][i]);
//也就是sig_hidden
}
//第五 获取sig_hidden对input对应的权的导数
for(int i = 0; i < 14; i++)
{
temp5[i] = network.values[0][i];
//也就是input
}
network.caches.push_back(temp1);
network.caches.push_back(temp2);
network.caches.push_back(temp__);
network.caches.push_back(temp3);
network.caches.push_back(temp4);
network.caches.push_back(temp5);
}
void step(NeuralNetwork &network, double learning_rate)
{
double** a = network.weights[1];
for(int i = 0; i < 3; i++)
{
for(int j = 0; j < 1; j++)
{
a[i][j] -= learning_rate * network.caches[0][j]\
* network.caches[1][j] * network.caches[2][i];
}
}
a = network.weights[0];
for(int k = 0; k < 14; k++)
for(int i = 0; i < 3; i++)
{
for(int j = 0; j < 1; j++)
{
a[k][i] -= learning_rate * network.caches[0][j]\
* network.caches[1][j] * network.caches[3][i]\
* network.caches[4][i] * network.caches[5][k];
}
}
return;
}
















 2476
2476











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









