







1 前言
在之前的博客 《行业分析---揭开新工业革命序幕的英伟达》中已经隆重介绍过英伟达,也算是AI时代一家伟大的公司。
作为 CES2025 正式揭幕的活动,黄仁勋的主题演讲从一开始就点燃所有观众。英伟达CEO宣布推出“Project Digits”,号称全球最小的个人AI超级计算机,将于5月左右上市,并且推出了新版本的显卡RT5090。
2 英伟达的主场
2.1 Project Digits
Project Digits配备了最新的GB10 Grace Blackwell超级芯片,包含了英伟达Blackwell GPU(具有最新一代CUDA核心和第五代Tensor Cores),它可以运行复杂的AI模型,可处理多达2000亿个参数的AI模型。
Project Digits不仅在硬件配置上令人瞩目,每台设备均标配128GB统一内存及最高4TB的NVMe高速存储,确保了数据处理与存储的高效性。用户可通过简单连接两台 Project Digits,构建一个更为强大的计算集群,轻松应对4050亿参数级别的超大型模型。


在实际测试中,Project Digits展现出了恐怖的实力。依托最新的Nvidia AI Enterprise软件套件,用户可以在该平台上进行AI模型的开发、测试及部署工作,极大地简化了整个工作流程。尤为重要的是,如此强大的本地计算能力赋予了用户即时验证模型效能的能力,显著缩短了模型迭代周期,让高性能触手可及,为AI技术的快速发展注入了强劲动力。
2.2 RTX5090 系列
英伟达在 CES 2025 上正式发布了下一代 RTX Blackwell GPU 系列,共包括四款型号:
-
RTX 5090,售价 $1,999
-
RTX 5080,售价 $999
-
RTX 5070 Ti,售价 $749
-
RTX 5070,售价 $549
其中,RTX 5090 和 RTX 5080 将于 1 月 30 日发售,RTX 5070 Ti 和 RTX 5070 将于 2 月发布。RTX 50 系列采用全新的 Founders Edition 设计,配备双向流通风扇以及 GDDR7 显存,所有型号均支持 PCIe Gen 5 和 DisplayPort 2.1b 接口,可驱动高达 8K/165Hz 的显示输出。

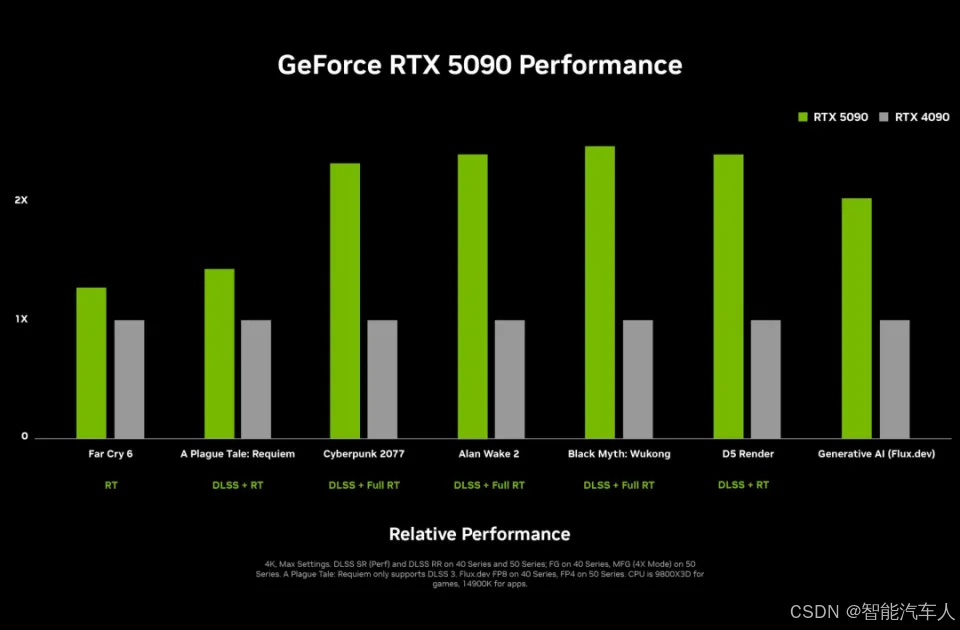
得益于新架构 Blackwell 和 DLSS 4,RTX 5090 的性能比 RTX 4090 快两倍(硬实力)。不过功耗也增加了 125 瓦,但英伟达表示其效率更高,只有在满负荷时才会达到 575 瓦(算力到最后拼的是能源,这句话并不是假话)。RTX 5080 性能也提升比较大,比 RTX 4080 快两倍;黄仁勋表示 RTX 5070 的性能等同于 RTX 4090,但售价仅有 $549。英伟达声称,RTX 5070 Ti 比 RTX 4070 Ti 快两倍,而 RTX 5070 的性能等同于 RTX 4090,售价仅 $549。
2.3 Omniverse+Cosmos
除了 RTX5090 系列显卡,还有英伟达在世界模型领域的进展。在CES演讲中,黄仁勋推出了 Cosmos 的世界基础模型:这些模型能够预测并生成 “物理感知”(physics-aware)的视频,其目的是为了解决当前 AI 模型 “知其然不知其所以然” 的问题。
目前,英伟达发布的 Cosmos 系列模型分为三大类:
-
Nano:用于低延迟和实时应用。
-
Super:用于高性能基线模型。
-
Ultra:用于最大质量和高保真输出。
这些模型参数规模从 40 亿到 140 亿不等,其中 Nano 是最小的模型,Ultra 是最大的。虽然参数越多性能通常越好,但开发者仍然可根据具体应用进行微调,并可通过英伟达的 API 和 NGC 目录、GitHub 以及 Hugging Face AI 开发平台获取。
黄仁勋在演讲中介绍,这些模型基于 9000 万亿个标记(tokens)和 2000 万小时的真实世界人机交互、环境、工业、机器人及驾驶数据训练而成。
回到世界模型本身,有了海量的现实世界视频数据作为支撑,Cosmos WFM 模型能够根据文本或视频帧生成合成数据(当现实数据样本量不够或者质量不高时,使用世界模型生成的数据也许效率更高),这些数据可以用于机器人、自动驾驶汽车等领域的模型训练和开发。

2.4 NVIDIA DRIVE 芯片
NVIDIA DRIVE 是英伟达为自动驾驶汽车设计的端到端平台,涵盖了从感知、规划到控制的完整解决方案。其核心是基于 NVIDIA 的 GPU 和 AI 技术,提供强大的计算能力和软件支持。英伟达推出了多款专为自动驾驶设计的芯片,目前的主要产品如下:
| 类型 | NVIDIA Xavier | NVIDIA Orin | NVIDIA Thor |
| 发布时间 | 2018 年 | 2022 年 | 预计 2025 年 |
| 架构 | 基于 Volta GPU 架构,集成 8 核 Carmel CPU 和深度学习加速器(DLA) | 基于 Ampere GPU 架构,集成 12 核 ARM Cortex-A78AE CPU 和下一代深度学习加速器 | 基于 Hopper GPU 架构 |
| 算力 | 30 TOPS(每秒万亿次操作) | 254 TOPS | 2000 TOPS |
| 功耗 | 30W | 45W(低功耗版本)到 200W(高性能版本) | |
| 应用 | 适用于 L2+ 到 L4 级别的自动驾驶 | 适用于 L4 和 L5 级别的自动驾驶 | 面向下一代自动驾驶和车载计算平台 |
| 特点 | 支持多芯片互联,最高可提供 2000 TOPS 的算力; 支持高精度传感器融合(摄像头、雷达、激光雷达等)。 | 集成 CPU、GPU 和深度学习加速器; 支持多模态传感器处理和实时路径规划。 |
3 总结
英伟达在智能芯片上的布局很多年,在AI时代也取得了令人瞩目的成绩。英伟达在GPU显卡,世界模型,自动驾驶芯片等方面的入场,也表明其希望在自动驾驶或者具身智能涉足更多领域。笔者在之前的博客中,也提到过,英伟达正在组建自动驾驶研发团队,后续的角色和地平线很像,提供算法-软件-硬件一体化的服务。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











