







1.概述
二十多年来, 塞普·霍赫赖特 创举 长短期记忆 (LSTM) 架构在许多深度学习突破和实际应用中发挥了重要作用。从生成自然语言到为语音识别系统提供动力,LSTM 一直是人工智能革命背后的驱动力。
然而,即使是 LSTM 的创建者也认识到它们固有的局限性,导致它们无法充分发挥潜力。无法修改存储的信息、内存容量有限以及缺乏并行化等缺点为 Transformer 和其他模型的兴起铺平了道路,以超越 LSTM 来完成更复杂的语言任务。
但在最近的一项进展中,Hochreiter 和他的团队 NXAI 引入了一个新的变体,称为 扩展 LSTM (xLSTM) 解决这些长期存在的问题。最近的一篇研究论文中提出,xLSTM 建立在使 LSTM 如此强大的基本思想之上,同时通过架构创新克服了其关键弱点。
xLSTM 的核心是两个新颖的组件:指数门控和增强型记忆结构。指数门控可以更灵活地控制信息流,使 xLSTM 能够在遇到新上下文时有效地修改决策。同时,与传统标量 LSTM 相比,矩阵存储器的引入大大增加了存储容量。
但增强功能还不止于此。通过利用从大型语言模型借用的技术(例如并行性和块的残差堆叠),xLSTM 可以有效地扩展到数十亿个参数。这释放了它们对极长序列和上下文窗口进行建模的潜力——这是复杂语言理解的关键功能。
Hochreiter 最新创作的意义是巨大的。想象一下虚拟助手可以在长达数小时的对话中可靠地跟踪上下文。或者在广泛的数据训练后能够更稳健地推广到新领域的语言模型。应用程序遍及 LSTM 产生影响的各个领域——聊天机器人、翻译、语音接口、程序分析等等——但现在 xLSTM 的突破性功能得到了增强。
在这份深入的技术指南中,我们将深入了解 xLSTM 的架构细节,评估其新颖的组件,如标量和矩阵 LSTM、指数门控机制、内存结构等。您将从实验结果中获得见解,这些实验结果展示了 xLSTM 相对于最先进的架构(例如 Transformer 和最新的循环模型)的令人印象深刻的性能提升。
2. LSTM 的局限性
在我们深入了解 xLSTM 的世界之前,有必要了解传统 LSTM 架构所面临的限制。这些限制一直是 xLSTM 和其他替代方法发展背后的驱动力。
- 无法修改存储决策:LSTM 的主要限制之一是当遇到更相似的向量时,它很难修改存储的值。这可能会导致需要动态更新存储信息的任务性能不佳。
- 存储容量有限:LSTM 将信息压缩为标量单元状态,这可能会限制它们有效存储和检索复杂数据模式的能力,特别是在处理稀有标记或远程依赖性时。
- 缺乏 并行性: LSTM 中的内存混合机制涉及时间步之间的隐藏连接,强制顺序处理,阻碍计算的并行化并限制可扩展性。
这些限制为 Transformer 和其他在某些方面超越 LSTM 的架构的出现铺平了道路,特别是在扩展到更大的模型时。
3.xLSTM 架构
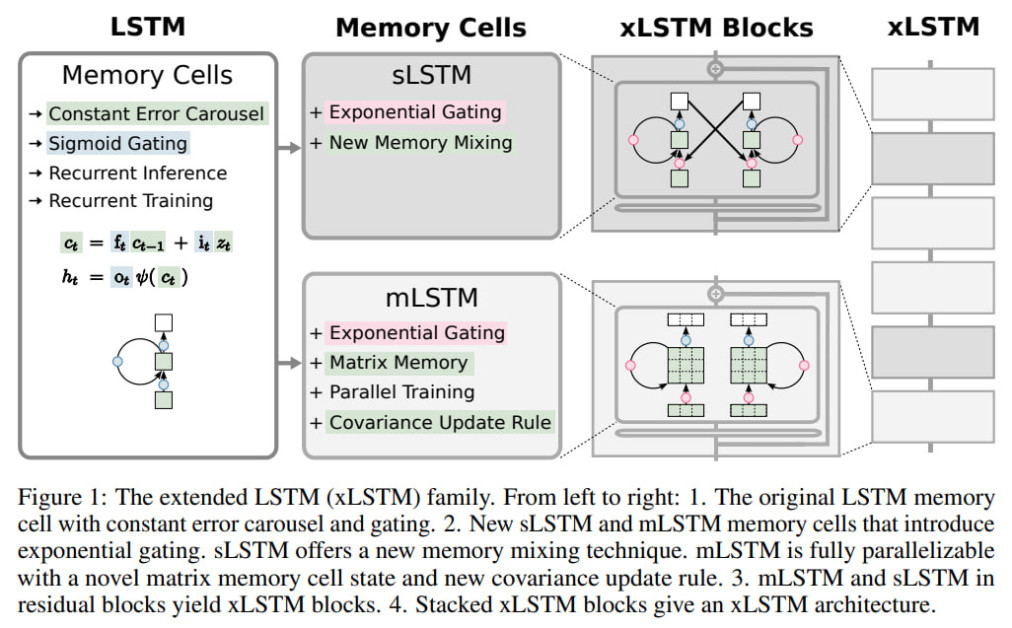
扩展 LSTM (xLSTM) 系列
xLSTM 的核心在于对传统 LSTM 框架的两个主要修改:指数门控和新颖的内存结构。这些增强功能引入了 LSTM 的两种新变体,称为 sLSTM(标量 LSTM)和 mLSTM(矩阵 LSTM)。
- . 长短期记忆网络:具有指数门控和内存混合的标量 LSTM
- 指数门控:sLSTM 结合了输入门和遗忘门的指数激活函数,可以更灵活地控制信息流。
- 标准化和稳定化:为了防止数值不稳定,sLSTM 引入了标准化器状态,用于跟踪输入门和未来忘记门的乘积。
- 内存混合:sLSTM 支持多个存储单元,并允许通过循环连接进行内存混合,从而实现复杂模式的提取和状态跟踪功能。
- . 毫升STM:具有增强存储能力的 Matrix LSTM
- 矩阵内存:mLSTM 使用矩阵存储器代替标量存储器单元,增加其存储容量并能够更有效地检索信息。
- 协方差更新规则:受双向关联存储器 (BAM) 启发,mLSTM 采用协方差更新规则来高效存储和检索键值对。
- 并行性:通过放弃内存混合,mLSTM 实现了完全并行性,从而能够在现代硬件加速器上进行高效计算。
sLSTM 和 mLSTM 这两个变体可以集成到残差块架构中,形成 xLSTM 块。通过剩余堆叠这些 xLSTM 块,研究人员可以构建针对特定任务和应用领域定制的强大 xLSTM 架构。
4.数学
传统 LSTM:
最初的 LSTM 架构引入了恒定误差轮播和门控机制来克服循环神经网络中的梯度消失问题。

LSTM 中的重复模块 – 来源
LSTM 存储单元更新由以下方程控制:
细胞状态更新:ct = ft ⊙ ct-1 + it ⊙ zt
隐藏状态更新: ht = ot ⊙ tanh(ct)
地点:
- 𝑐𝑡 是此时的细胞状态向量 𝑡t
- 𝑓𝑡 是忘记门向量
- 𝑖𝑡 是输入门向量
- 𝑜𝑡 是输出门向量
- 𝑧𝑡 是由输入门调制的输入
- ⊙ 表示逐元素乘法
门 ft、it 和 ot 控制从单元状态 ct 存储、遗忘和输出哪些信息,从而缓解梯度消失问题。
具有指数门控的 xLSTM:

xLSTM 架构引入了指数门控,可以更灵活地控制信息流。对于标量 xLSTM (sLSTM) 变体:
细胞状态更新:ct = ft ⊙ ct-1 + it ⊙ zt
标准化器状态更新:nt = ft ⊙ nt-1 + it
隐藏状态更新:ht = ot ⊙ (ct / nt)
输入和遗忘门: it = exp(W_i xt + R_i ht-1 + b_i) ft = σ(W_f xt + R_f ht-1 + b_f) OR ft = exp(W_f xt + R_f ht-1 + b_f)
输入 (it) 和遗忘 (ft) 门的指数激活函数以及标准化器状态 nt 可以更有效地控制内存更新和修改存储的信息。
具有矩阵内存的 xLSTM:
对于具有增强存储容量的矩阵 xLSTM (mLSTM) 变体:
细胞状态更新:Ct = ft ⊙ Ct-1 + it ⊙ (vt kt^T)
标准化器状态更新:nt = ft ⊙ nt-1 + it ⊙ kt
隐藏状态更新: ht = ot ⊙ (Ct qt / max(qt^T nt, 1))
地点:
- 𝐶𝑡 是矩阵细胞状态
- 𝑣𝑡 和 𝑘𝑡 是值向量和键向量
- 𝑞𝑡 是用于检索的查询向量
这些关键方程强调了 xLSTM 如何通过指数门控扩展原始 LSTM 公式,以实现更灵活的内存控制和矩阵内存以增强存储能力。这些创新的结合使 xLSTM 能够克服传统 LSTM 的局限性。
5. xLSTM 的主要特性和优势
- . 修改存储决策的能力:得益于指数门控,xLSTM 在遇到更多相关信息时可以有效地修改存储值,克服了传统 LSTM 的重大限制。
- . 增强的存储容量:mLSTM 中的矩阵内存提供了更大的存储容量,使 xLSTM 能够更有效地处理稀有标记、远程依赖性和复杂的数据模式。
- . 并行性:xLSTM 的 mLSTM 变体是完全可并行的,允许在 GPU 等现代硬件加速器上进行高效计算,并可扩展到更大的模型。
- . 内存混合和状态跟踪:xLSTM 的 sLSTM 变体保留了传统 LSTM 的内存混合功能,支持状态跟踪,并使 xLSTM 对于某些任务比 Transformer 和状态空间模型更具表现力。
- . 可扩展性:通过利用现代大型语言模型 (LLM) 的最新技术,xLSTM 可以扩展到数十亿个参数,从而释放语言建模和序列处理任务的新可能性。
6.实验评估:展示 xLSTM 的能力

该研究论文对 xLSTM 进行了全面的实验评估,强调了它在各种任务和基准测试中的表现。以下是一些主要发现:
- . 综合任务和远程竞技场:
- xLSTM 擅长解决需要状态跟踪的形式语言任务,性能优于 Transformer、状态空间模型和其他 RNN 架构。
- 在多查询关联回忆任务中,xLSTM 展示了增强的记忆能力,超越非 Transformer 模型并与 Transformer 的性能相媲美。
- 在 Long Range Arena 基准测试中,xLSTM 表现出了一致的强劲性能,展示了其处理长上下文问题的效率。
- . 语言建模和下游任务:
- 当使用 SlimPajama 数据集的 15B 个 token 进行训练时,xLSTM 在验证困惑度方面优于现有方法,包括 Transformer、状态空间模型和其他 RNN 变体。
- 随着模型缩放到更大的尺寸,xLSTM 继续保持其性能优势,表现出良好的缩放行为。
- 在常识推理和问答等下游任务中,xLSTM 成为各种模型大小的最佳方法,超越了最先进的方法。
- . PALOMA 语言任务的表现:
- 在 PALOMA 语言基准测试的 571 个文本域上进行评估,xLSTM[1:0](sLSTM 变体)在 99.5% 的域中实现了比其他方法更低的困惑度(与 Mamba 相比、与 Llama 相比为 85.1%、与 RWKV 相比为 99.8%) -4。
- . 缩放定律和长度外推:
- 当使用 SlimPajama 的 300B 令牌进行训练时,xLSTM 表现出有利的缩放定律,表明随着模型大小的增加,其性能进一步提高的潜力。
- 在序列长度外推实验中,xLSTM 模型即使对于比训练期间看到的长得多的上下文也能保持较低的困惑度,优于其他方法。
这些实验结果凸显了 xLSTM 的卓越功能,使其成为语言建模任务、序列处理和广泛其他应用的有前途的竞争者。
7. 实际应用和未来方向
xLSTM 的潜在应用涵盖广泛的领域,从自然语言处理和生成到序列建模、时间序列分析等等。以下是 xLSTM 可以产生重大影响的一些令人兴奋的领域:
- . 语言建模和文本生成:凭借增强的存储容量和修改存储信息的能力,xLSTM 可以彻底改变语言建模和文本生成任务,从而实现更加连贯、上下文感知和流畅的文本生成。
- . 机器翻译:xLSTM 的状态跟踪功能在机器翻译任务中可能具有无价的价值,其中维护上下文信息和理解远程依赖关系对于准确翻译至关重要。
- . 语音识别和生成:xLSTM 的并行性和可扩展性使其非常适合语音识别和生成应用,在这些应用中,长序列的高效处理至关重要。
- . 时间序列分析与预测:xLSTM 处理远程依赖性以及有效存储和检索复杂模式的能力可以显着改进跨多个领域(例如金融、天气预报和工业应用)的时间序列分析和预测任务。
- . 强化学习和控制系统:xLSTM 在强化学习和控制系统中的潜力是有前景的,因为其增强的记忆能力和状态跟踪能力可以在复杂环境中实现更智能的决策和控制。
8.架构优化和超参数调整
虽然目前的结果令人鼓舞,但 xLSTM 架构和超参数的微调仍有优化的空间。研究人员可以探索 sLSTM 和 mLSTM 模块的不同组合,改变整体架构中的比率和位置。此外,系统的超参数搜索可以进一步提高性能,特别是对于较大的模型。

硬件感知优化:为了充分利用 xLSTM(尤其是 mLSTM 变体)的并行性,研究人员可以研究针对特定 GPU 架构或其他加速器量身定制的硬件感知优化。这可能涉及优化 CUDA 内核、内存管理策略以及利用专用指令或库来实现高效的矩阵运算。
与其他神经网络组件集成:探索 xLSTM 与其他神经网络组件(例如注意力机制、卷积或自监督学习技术)的集成,可能会产生结合不同方法优势的混合架构。这些混合模型可能会释放新功能并提高更广泛任务的性能。
少样本和迁移学习:探索 xLSTM 在小样本和迁移学习场景中的使用可能是未来研究的一个令人兴奋的途径。通过利用其增强的记忆能力和状态跟踪能力,xLSTM 可以实现更高效的知识转移,并通过有限的训练数据快速适应新任务或领域。
可解释性和可解释性:与许多深度学习模型一样,xLSTM 的内部工作原理可能不透明且难以解释。开发用于解释和解释 xLSTM 决策的技术可以产生更加透明和值得信赖的模型,促进其在关键应用程序中的采用并促进问责制。
高效且可扩展的培训策略:随着模型的规模和复杂性不断增长,高效且可扩展的训练策略变得越来越重要。研究人员可以探索专门为 xLSTM 架构定制的模型并行性、数据并行性和分布式训练方法等技术,从而能够训练更大的模型,并有可能降低计算成本。
这些是 xLSTM 进一步探索的一些潜在的未来研究方向和领域。
9.结论
xLSTM 的推出标志着追求更强大、更高效的语言建模和序列处理架构的一个重要里程碑。通过解决传统 LSTM 的局限性并利用指数门控和矩阵存储结构等新技术,xLSTM 在各种任务和基准测试中表现出了卓越的性能。
然而,旅程并没有就此结束。与任何突破性技术一样,xLSTM 为在现实场景中进一步探索、完善和应用提供了令人兴奋的机会。随着研究人员不断突破可能的界限,我们有望见证自然语言处理和人工智能领域更加令人印象深刻的进步。

















 5405
5405











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











