






文章目录
一、摘要

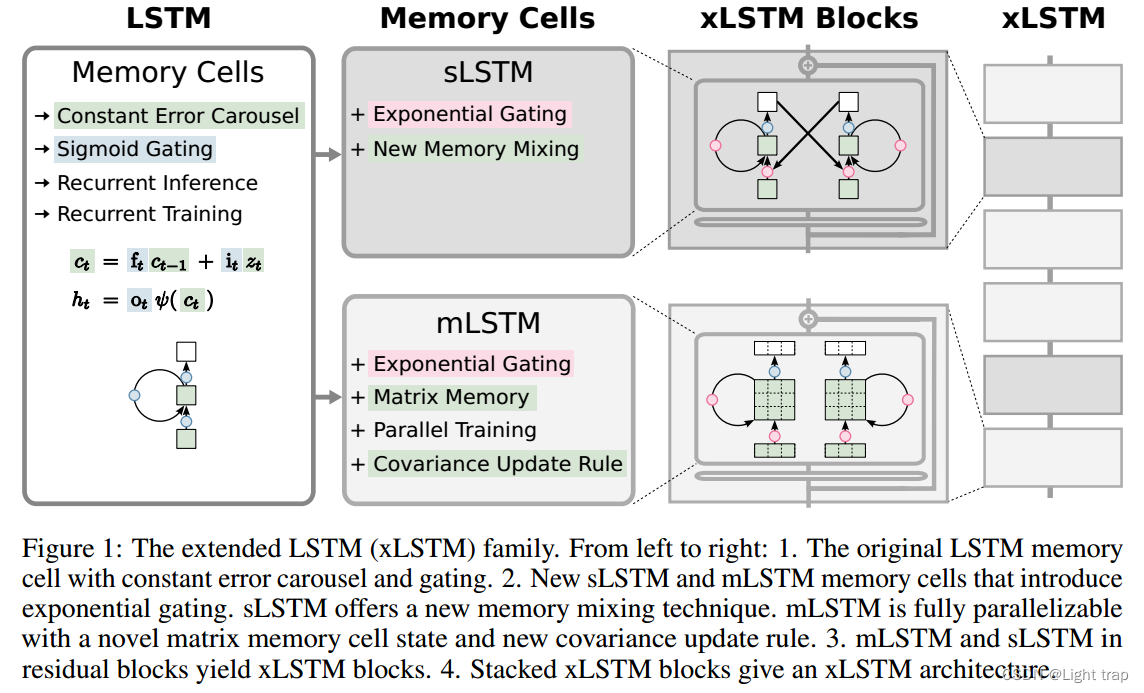
xLSTM——新型递归神经网络架构,旨在解决传统LSTM的局限性,并提高其在语言建模等任务中的性能。
二、传统LSTM的局限
- 无法修订存储决策
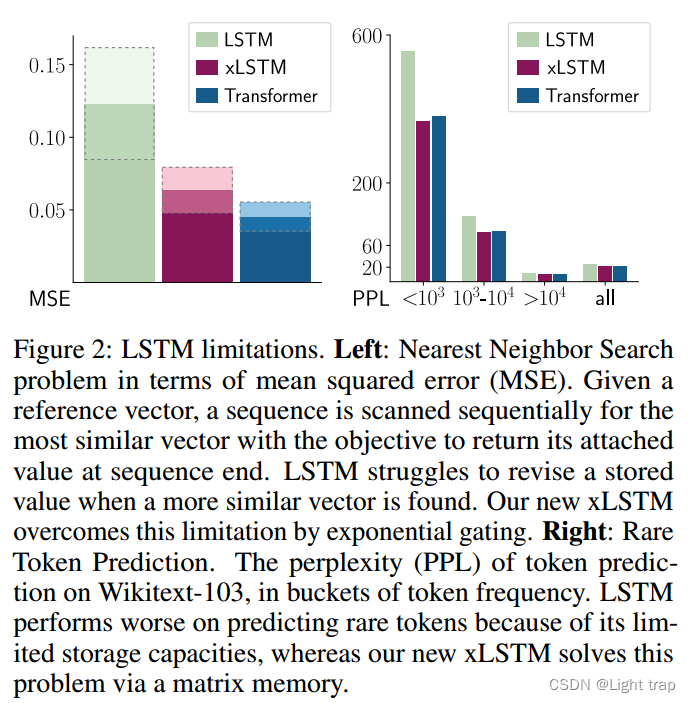
通过最近邻搜索问题来说明这一限制(见附录 B):给定一个参考向量,必须按顺序扫描序列,以找到最相似的向量,以便在序列末尾提供。图2的左侧面板显示了该任务的均方误差。当找到一个更相似的向量时,LSTM 在修订存储值时遇到困难,而我们的新 xLSTM 通过指数门控修复了这个限制。
- 有限的存储容量
信息必须压缩到标量单元状态中,文章通过稀有标记预测来说明这一限制。在图2的右侧面板中,给出了对 Wikite-103(Merity et al., 2017)上的标记预测的困惑度,针对不同标记频率的块(buckets)。由于其有限的存储容量,LSTM 在稀有标记上表现较差。新 xLSTM 通过矩阵存储解决了这个问题。
- 由于记忆混合导致缺乏并行性
从一个时间步到下一个时间步的隐藏状态之间的隐藏-隐藏连接,强制要求LSTM进行顺序处理,影响了其在大规模数据处理中的效率。
三、扩展的LSTM
3.1 LSTM
- CEC( constant error carousel ):引入了标量内存单元作为一个中心处理和存储单元,通过恒定误差旋转(cell state)避免了梯度消失。内存单元包含三个门(蓝色):输入门、输出门和遗忘门。
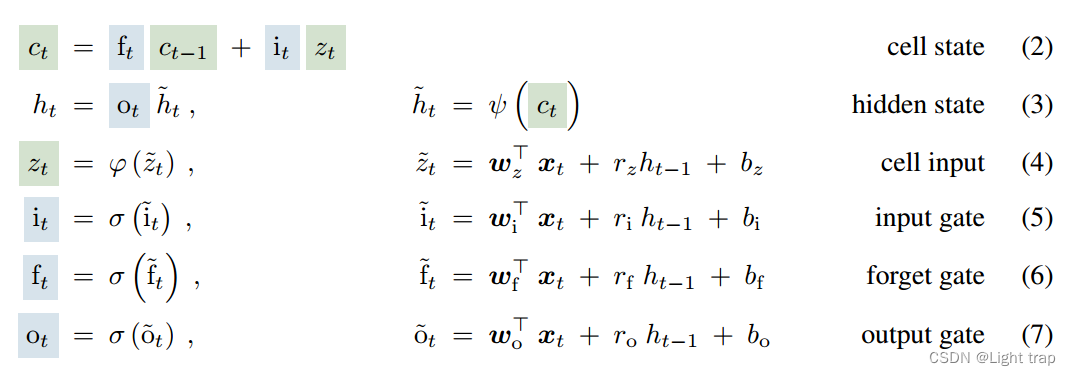
3.2 sLSTM
- 指数门控(红色):引入指数激活函数到输入和遗忘门中——更有效地更新其内部状态,赋予LSTM修改存储决策的能力。
- 归一化和稳定化:引入normalizer state,将输入门与所有未来遗忘门的乘积相加——能够更好地处理信息流,特别是在需要修订存储决策的场景中。
- stabilizer state:指数激活函数可能导致较大的值,从而导致溢出。因此,用一个额外的状态mt来稳定门控信号
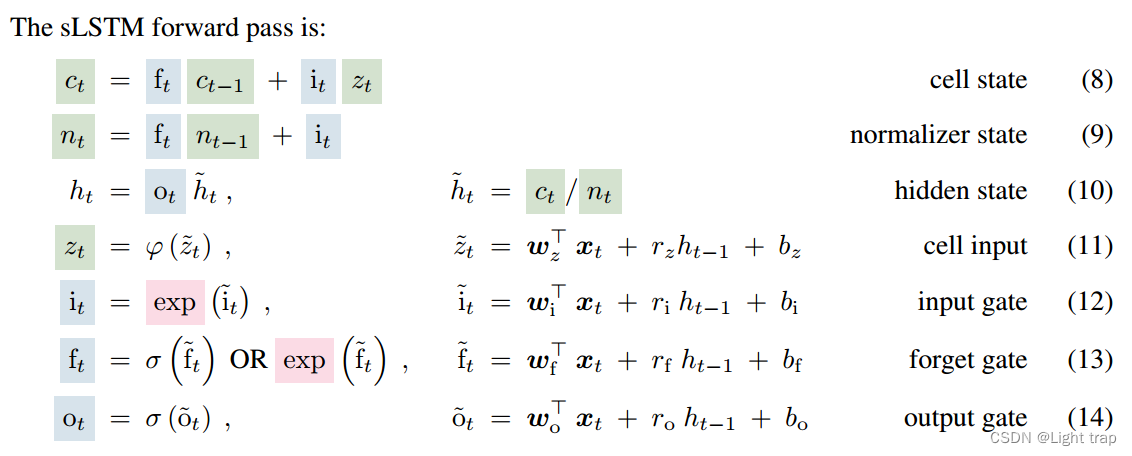
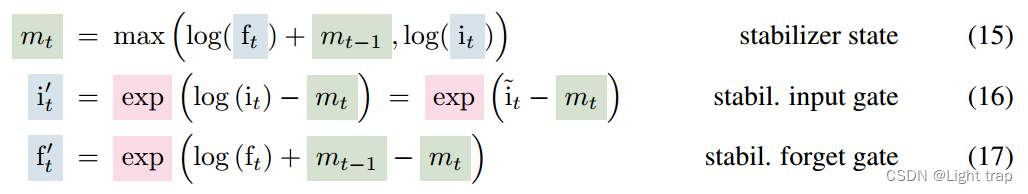
- New Memory Mixing:sLSTM 可以像原始的 LSTM 一样具有多个内存单元(见附录 A.2)。多个内存单元通过从隐藏状态向量 h 到内存单元输入 z 和门 i、f、o 的递归连接 rz、ri、rf、ro 实现内存混合。新的sLSTM可以有多个头,每个头内的内存混合,但不能跨头。sLSTM头的引入和指数门控的结合为存储器混合提供了一种新的方法。
- 附录 A.2:基于 Greff 等人(2015)的标准 LSTM 内存单元更新规则,在时间步 t 将标量单元状态公式扩展为单元状态向量,类似地,sLSTM 也可以向量化为多个单元:
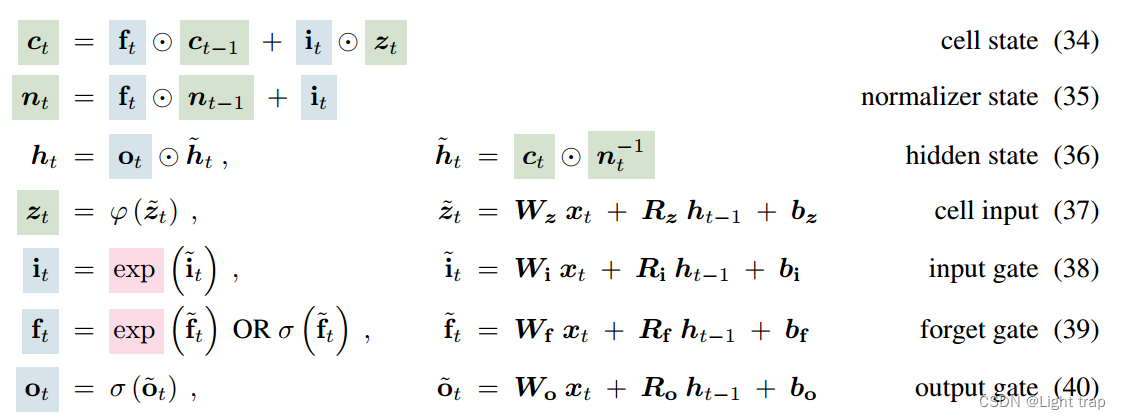
3.3 mLSTM
- 矩阵记忆:将 LSTM 内存单元从标量 c ∈ R 增加到矩阵 C ∈ R^(d×d),使用矩阵来存储和检索信息——矩阵乘法增强存储容量,解决了LSTM在处理稀有标记预测时的局限性。
- 协方差更新规则:使用协方差矩阵来更新记忆单元。
存储键-值对的协方差更新规则: C t = C t − 1 + v t k t ⊤ C_t =C_{t-1}+v_tk_{t}^{⊤} \, Ct=Ct−1+vtkt⊤
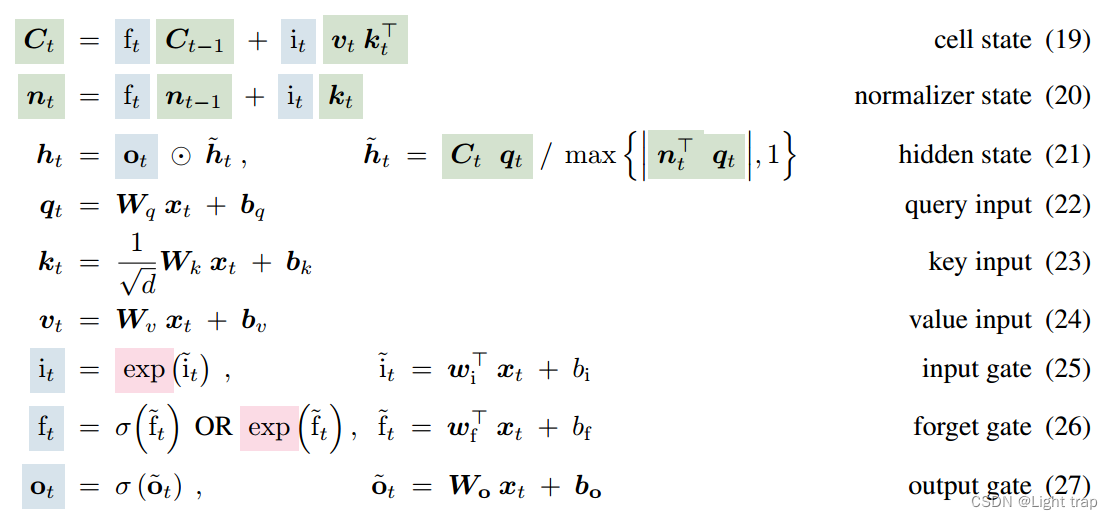
mLSTM可以像原始的 LSTM 一样具有多个内存单元。对于 mLSTM,因为没有内存混合,多个头部和多个单元是等价的,这种递归可以重新表述为并行版本。
这两种新的记忆单元都通过指数门控来增强LSTM的功能。此外,mLSTM放弃了记忆混合,从而实现了并行化处理,而sLSTM则保留了记忆混合,但通过引入头部来形成新的记忆混合方式。
3.4 xLSTM
3.4.1 post up-projection
带有后向投影(post up-projection)的残差块(类似于Transformer),它在原始空间中非线性地总结过去,然后线性映射到高维空间,应用非线性激活函数,然后线性映射回原始空间。对于 xLSTM 块中的sLSTM块,主要使用后向投影残差块。
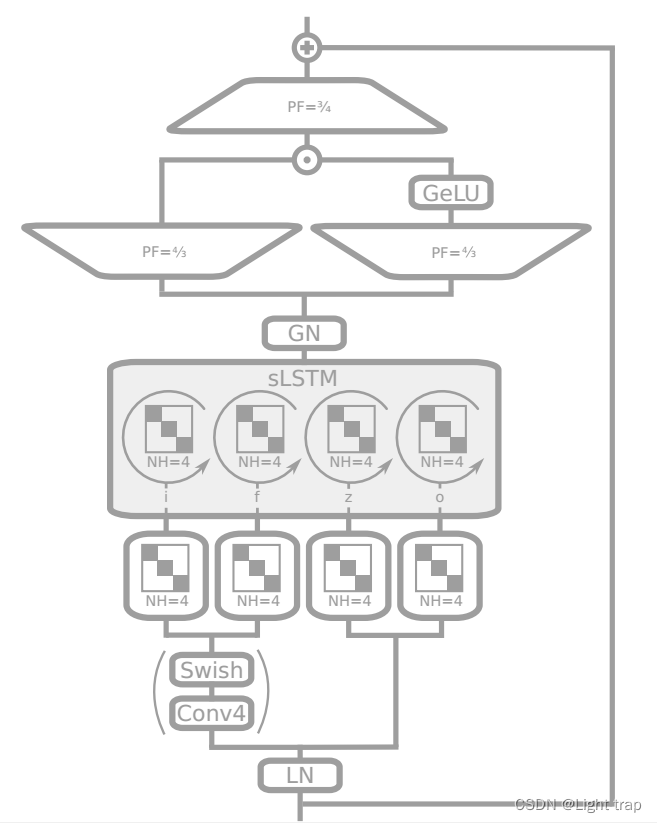
- 嵌入在 pre-LayerNorm 残差结构中。
- 输入门i和遗忘门f:可选择是否经过窗口大小为 4 的因果卷积和Swish激活函数。
S w i s h ( x ) = x ∗ S i g m o i d ( x ) Swish(x)=x∗Sigmoid(x) Swish(x)=x∗Sigmoid(x) - 对于所有门控信号 i、f、o,以及单元更新 z,通过一个具有四个对角块或 “头” (Head)的块对角线性层。这些对角块与来自上一个隐藏状态的递归门 pre-activations 相一致,对应于一个具有四个头的 sLSTM,用圆形箭头表示。
- 得到的隐藏状态通过一个 GroupNorm 层—— 每个头部都进行 LayerNorm。
- 最后,使用门控MLP对输出进行上下投影,使用GeLU激活函数和投影因子4/3来匹配参数。
G E L U ( x ) = x ∗ P ( X ≤ x ) = x ∗ Φ ( x ) GELU(x)=x∗P({X}\le{x})=x∗\Phi (x) GELU(x)=x∗P(X≤x)=x∗Φ(x)其中 Φ ( x ) \Phi (x) Φ(x)指x的高斯正态分布的累积函数。
3.4.2 pre up-projection
带有前向投影(pre up-projection)的残差块(类似于 SSM),它线性映射到高维空间,然后在高维空间中非线性地总结过去,最后线性映射回原始空间。对于 xLSTM 块中的mLSTM块,主要使用前向投影残差块。
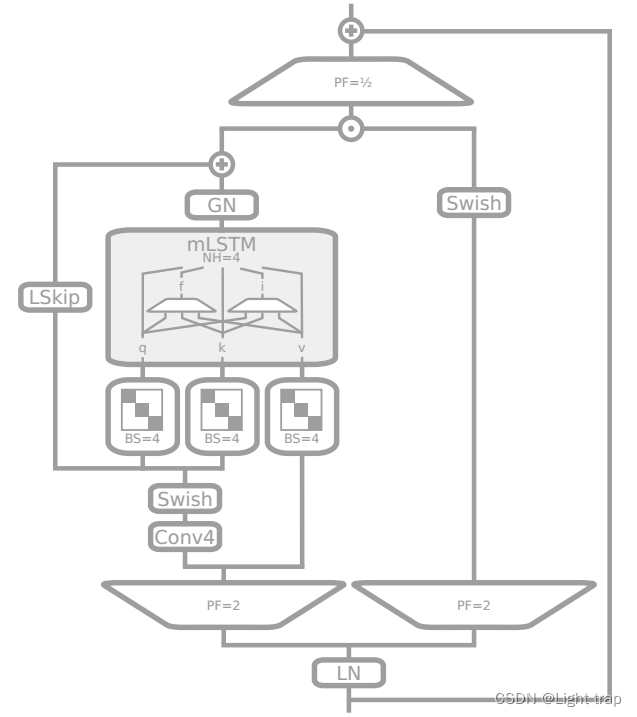
- 嵌入在 pre-LayerNorm 残差结构中。
- 首先对输入进行上投影,投影因子为 2,一次用于外部化输出门,一次作为 mLSTM 单元的输入。
- 经过窗口大小为 4 的因果卷积和Swish激活函数进行可学习的跳跃连接。
- 通过块(Block)大小为 4 的块对角投影矩阵获得输入 q 、 k、v,v 直接馈送,跳过卷积部分。
- mLSTM 序列混合之后,通过 GroupNorm进行输出归一化—— 每个头部都进行 LayerNorm。然后将可学习的跳跃输入添加到结果中。
- 外部输出门对上述结果进行门控。
- 最后进行下投影。
xLSTM的架构通过将这些新变体(sLSTM、mLSTM)集成到残差块模块中,形成了xLSTM块,然后将这些块以残差堆叠的方式构建成完整的xLSTM架构。这种架构不仅提高了性能,还在规模化方面与现有的Transformer和状态空间模型相比具有优势。
四、实验
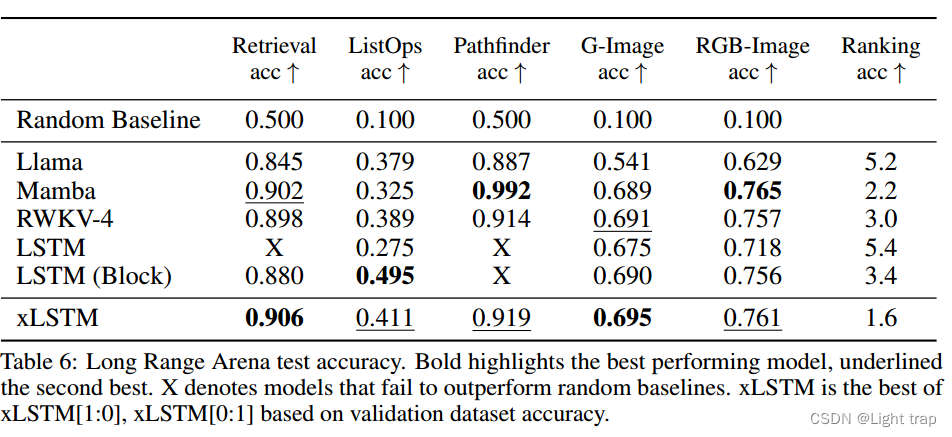
下表在Long Range Arena基准上的实验结果,旨在评估了模型处理长序列的能力。可以发现xLSTM在所有测试任务上均表现出色,显示了其在处理长上下文问题方面的高效性。
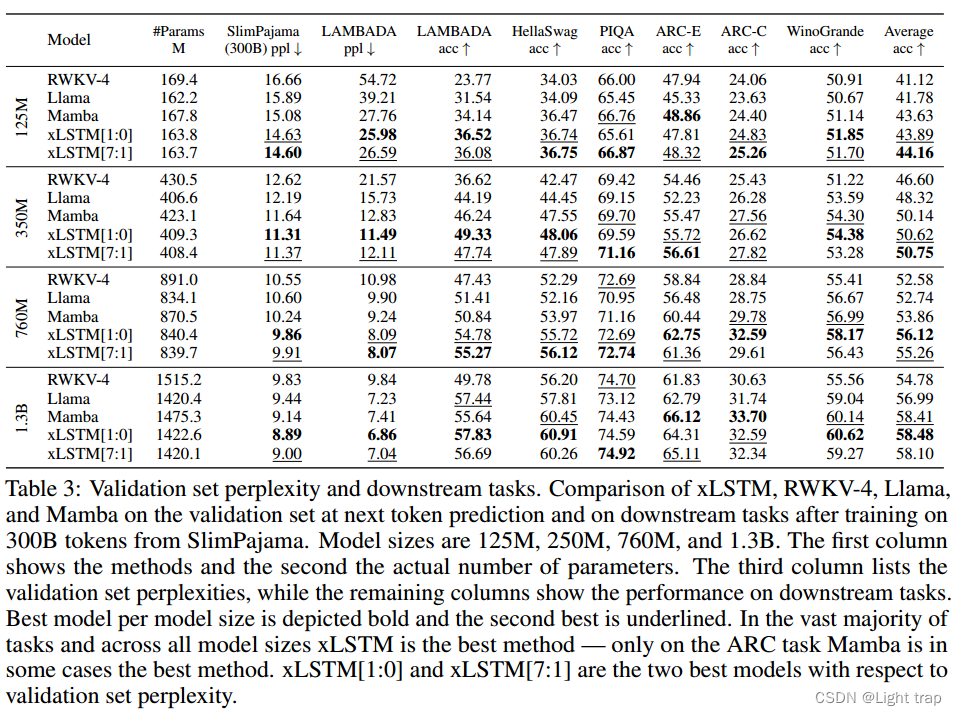
下表展示了,在SlimPajama(300B)数据集上,不同模型尺寸的xLSTM与其他模型在验证集困惑度和下游任务性能上的比较。可以发现xLSTM在不同模型尺寸下,在验证集上的困惑度最低,证明了其在语言建模任务上的优势。
参考
https://zhuanlan.zhihu.com/p/696640517
https://cloud.tencent.com/developer/article/2415986

















 1912
1912

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









