








大模型技术论文不断,每个月总会新增上千篇。本专栏精选论文重点解读,主题还是围绕着行业实践和工程量产。若在某个环节出现卡点,可以回到大模型必备腔调重新阅读。而最新科技(Mamba,xLSTM,KAN)则提供了大模型领域最新技术跟踪。若对于如果构建生成级别的AI架构则可以关注AI架构设计专栏。技术宅麻烦死磕LLM背后的基础模型。
Picovoice首席执行官Alireza Kenarsari指出,“picoLLM是Picovoice 深度学习研究人员和量产工程师共同努力的成果。前者研究出X 位量化算法,而后者构建了跨平台的LLM 推理引擎。目的还是在于将LLM遍及到任何设备且将控制权交还给企业”。
picoLLM Inference可以免费使用,没有任何使用限制。无论是在概念验证上,还是为数百万用户提供服务。只需几行代码即可部署。
注:其余的产品线有非商用免费版,也有收费版

认识量化(Quantization)
大模型有个基本的指标就是模型参数规模,客观而言参数规模越大,效果越佳,但是所需的内存越多。例如,要部署 7.7GB 大小的Mistral 7B,需要GPU的VRAM大小要超过8GB才能在GPU完全加载。因此意味着运行更大规模的模型将需要具有更大规格的硬件,从而增加成本。
量化是一种压缩技术,将高精度值映射到低精度值。对于任意的大模型,这意味着它们的权重和激活精度会被调整,肯定会对影响模型的能力。在实际的运用过程中发现,某些情况下虽然明显的减低精度,然而却又能获得和原来不相上下的结果。
量化通过降低内存带宽需求和提高缓存利用率来提高性能,不同精度级别的量化过程能够更多的设备上运行大模型。
LLMs通常使用全精度(float32)或半精度(float16)的浮点数进行训练。一个float16有16位,即2个字节。因此在 FP16上训练参数规模为1B的大模型则至少需要2GB的内存,这还不包括训练过程中的优化器内存、激活内存和梯度内存。
量化其实就是想找到一种方法,将FP32权重的值的范围([最小值,最大值])表示为较低精度的值,例如FP16甚至INT4(整数 4 位)的数据类型。典型的情况是从FP32到INT8。
下图为一个具体的例子,将FP16格式的数组量化为INT8的过程,当然最后可以从INT8再次还原为FP16。这样一来原来模型的存储大小就被有效的降低了。
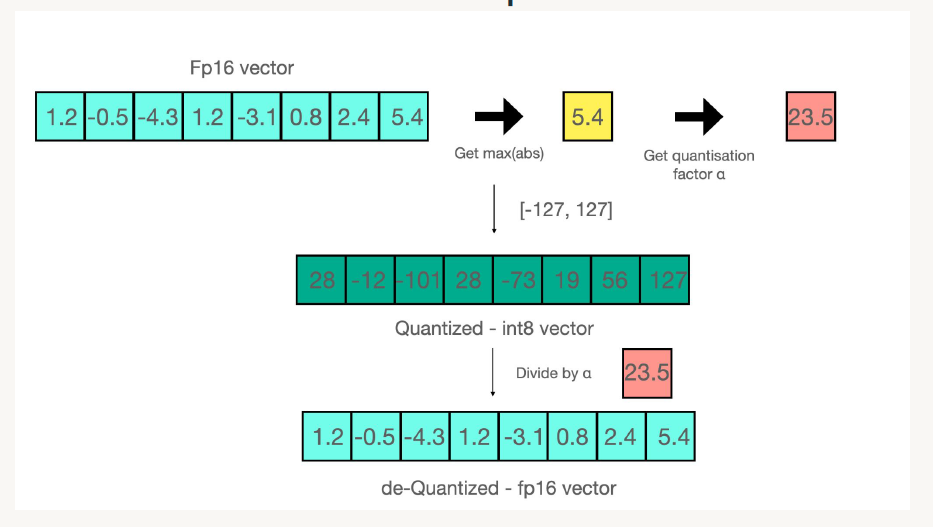
其实换个思路来讲,就是将数轴进行压缩。这里的难题在于如何的量化才能降低存储开销,但是又能表达出原来的意思。
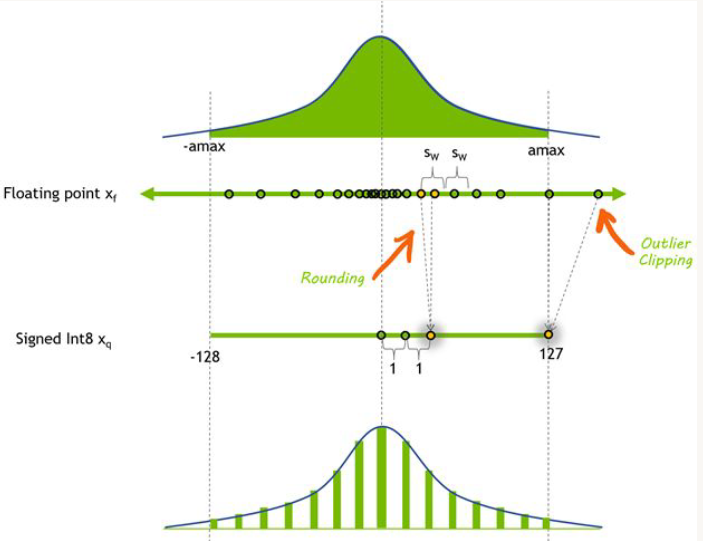
目前有不少的量化思路,均匀量化是模型量化中常用的一种技术,用于降低深度学习模型中权重和激活的精度。在量化过程中将值的范围划分为固定数量的等距区间,然后将每个值映射到最近区间的中心。此过程有助于减少表示每个值所需的位数。
与更复杂的量化技术相比,均匀量化的主要优势之一是其简单易用。然而,均匀量化可能并不总是能捕捉到数据分布的细微差别。想象一下原始参数的取值在[3.5, 3.9],若都被量化到4,的确会导致潜在的信息丢失和性能下降。
另一方面,非均匀量化允许量化步距不均匀分布,从而能更准确和更灵活。量化过程由离散量化水平 (Xi) 和相应的量化步骤 (∆i) 定义。当实数落在特定的量化步骤范围 (∆i, ∆i+1) 内时,量化器将其分配到相应的量化级别 (Xi)。非均匀量化方法(如对数分布)侧重于以指数而不是线性方式调整量化步骤和水平,这可以通过有效捕获重要值区域来提高准确性。
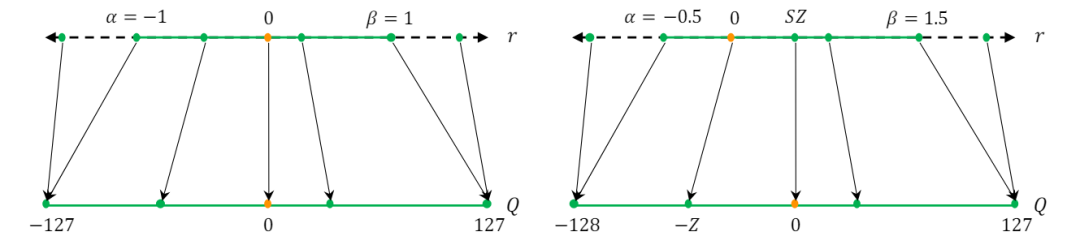
左图为对称量化,右图为非对称量化

微调中的量化
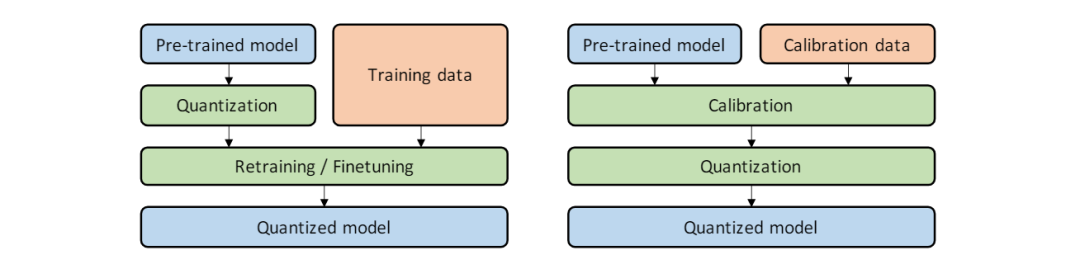
左图为QAT,右图为PTQ,两者的区别在于量化的位置。
PTQ是一种流行的技术,模型参数(通常以FP32等高精度格式存储)被转换为较低位精度的INT8。此转换过程允许在计算资源有限的硬件(如移动设备和嵌入式系统)上更高效地部署模型。PTQ 可以应用于神经网络的权重和激活,从而减小模型大小并提高推理速度,而不会显着降低准确性。
QAT具有在部署期间将应用的量化效应的意识。当对训练模型进行量化时,可能会导致模型参数出现扰动,从而可能导致模型偏离训练期间以浮点精度实现的收敛点。
为了解决这个问题,QAT使用量化参数重新训练神经网络模型,使模型能够收敛到损失减少的点。在QAT期间,在浮点对量化模型执行正向和后向传递,而模型参数在每次梯度更新后进行量化,类似于预测梯度下降。在浮点权重更新后执行投影对于防止零梯度或高误差梯度至关重要,尤其是在低精度场景中。
在QAT的反向传播过程中,处理不可微分的量化算子是一个挑战。一种常用方法是使用直通估计器 (STE) 通过将量化算子视为恒等函数来近似量化算子的梯度。

picoLLM
picoLLM Compression是Picovoice内部开发的一种新型大型语言模型量化算法。给定一个特定于任务的成本函数,picoLLM Compression 会自动学习跨权重和权重内LLM的最佳位分配策略。而目前现有技术方案都是固定分配。
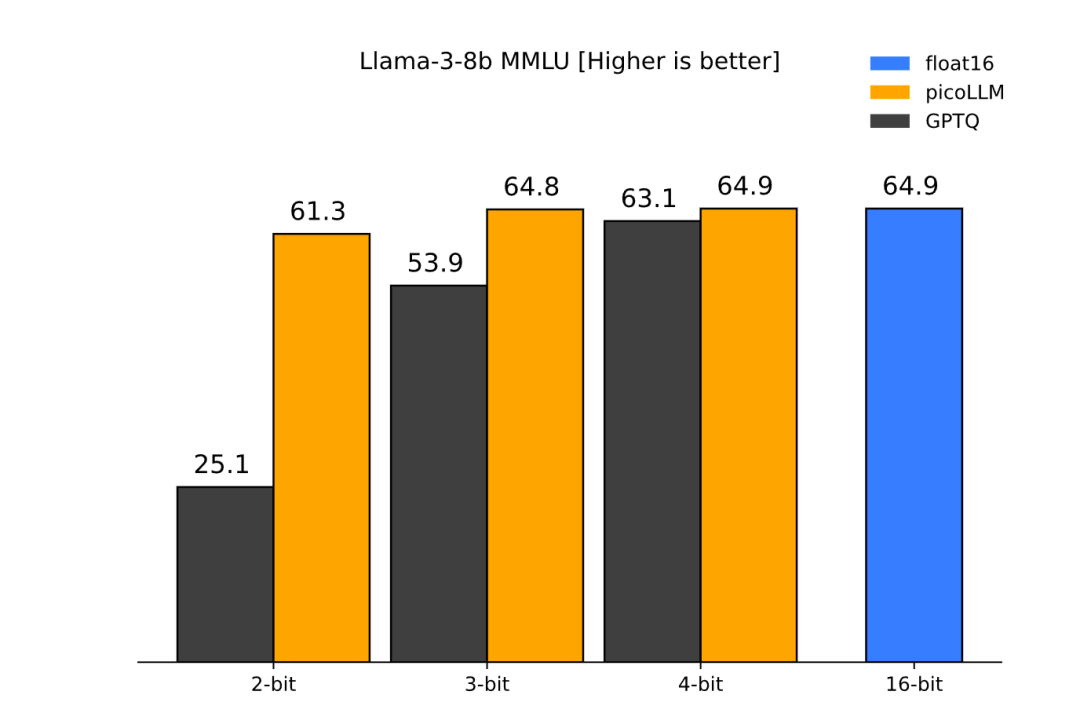
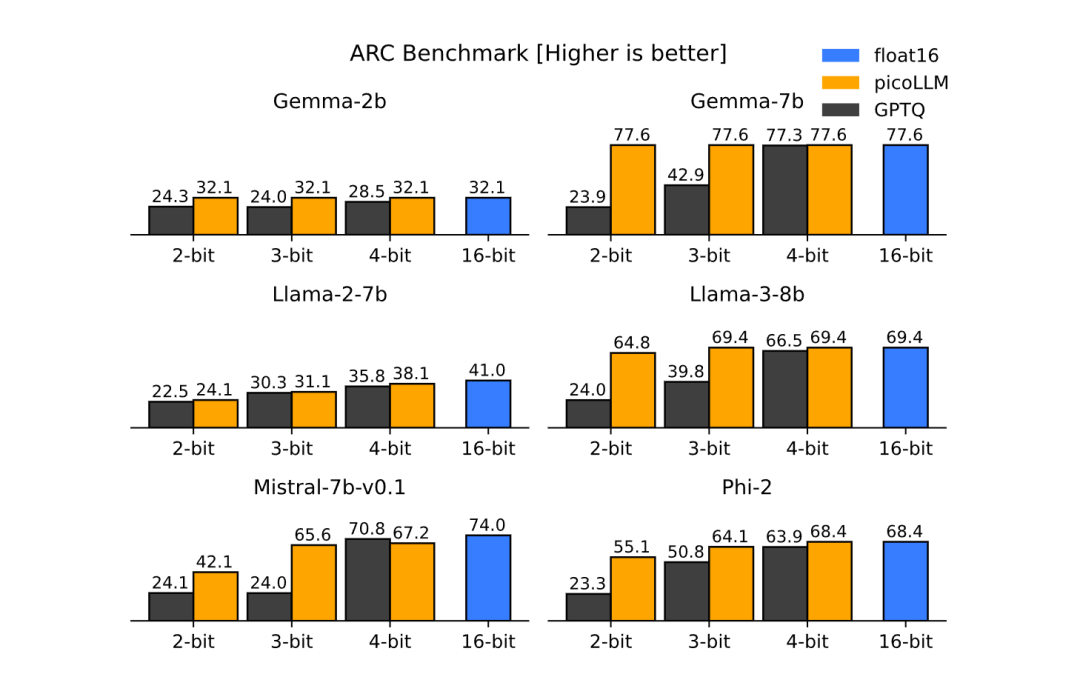
picoLLM提供了一个全面的开源基准测试结果,例如下图,当应用于 Llama-3-8b ,picoLLM在2、3和 4位的量化设置下在MMLU的评测分数中,将采用GPTQ算法的正确率下降消灭于无形之中。随着量化位数的下降,几乎保持坚挺。
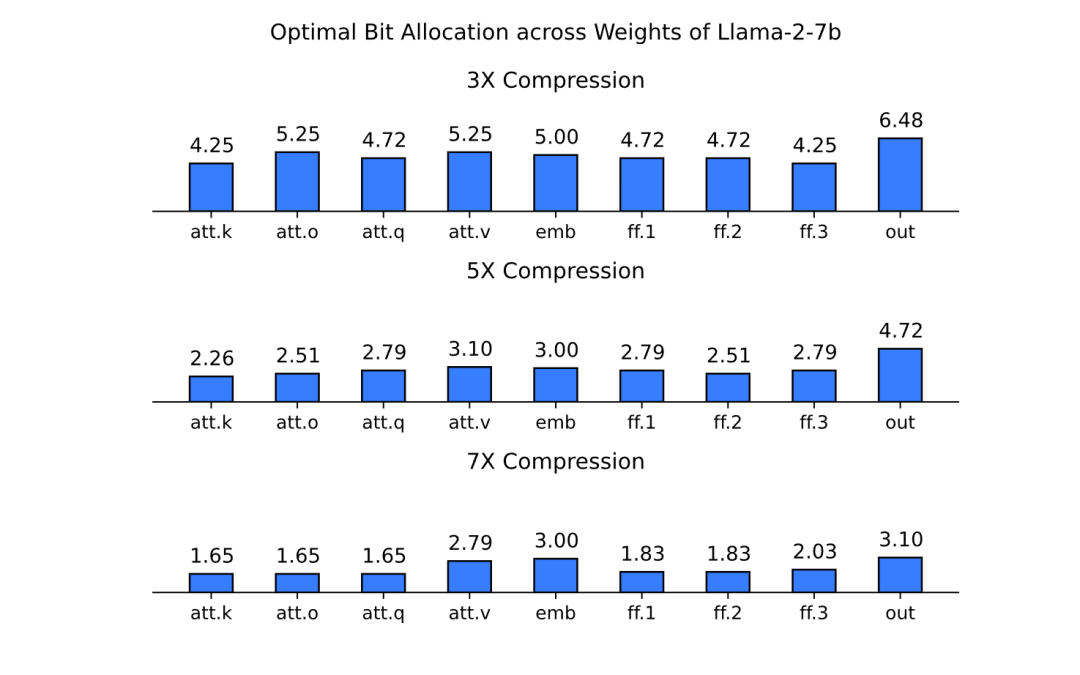
现有方法依赖于跨模型权重的固定位分配。但是,picoLLM 在量化过程中学习最优分配。每个模型最理想的量化位数取决于自身的架构和压缩比。例如,下面的三张图显示了压缩比为 3、5 和 7 时 Llama-2-7b不同组件之间的位最佳分布:
在MMLU (5-shot)任务上采用picoLLM的效果对比。
PicoLLM 框架支持Gemma、Llama、Mistral、Mixtral和Phi系列模型,并在Windows、macOS 和Linux上跨平台运行(包括Raspberry Pi 4和 5 上的Raspberry Pi OS)以及 Android 和 iOS。下次将详细地介绍它的内在原理。















 260
260

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









