






 本文详细解释了模型量化的原因,包括减少存储开销、提高计算效率和能源利用,重点介绍了后量化在推理阶段的应用,以及不同精度量化类型(如FP16、INT8)的选择和比较。文章还展示了PyTorch中的量化支持,包括动态量化和静态量化方法,以及量化对模型精度的影响和挑战。
本文详细解释了模型量化的原因,包括减少存储开销、提高计算效率和能源利用,重点介绍了后量化在推理阶段的应用,以及不同精度量化类型(如FP16、INT8)的选择和比较。文章还展示了PyTorch中的量化支持,包括动态量化和静态量化方法,以及量化对模型精度的影响和挑战。
一、引言:为什么要对模型进行量化?
xdm在尝试运行Llama-Chat-7B推理时的时候,是不是也容易遇到OOM的问题?(笔者最近在使用丐版colab运行Llama-Chat-7B,这个模型模型大小为13G,要求的显存也在13G左右,丐版无法承受)
为了解决这个应用LLM的实际问题(即LLM对显存的占用大,在高并发的环境下/资源并不丰富的情况下,可能会导致服务崩溃),最常用的手段就是对LLM进行低精度的量化,从而节省显存和带宽。
为什么要对模型进行量化,即以下三点:
-
更少的存储开销和带宽需求。即使用更少的bit存储数据,有效减少应用对存储资源的依赖;
-
更快的计算速度。即对大多数处理器而言,整型运算的速度一般(但不总是)要比浮点运算更快一些;
-
更低的能耗、更低的芯片占用面积
在什么时候对模型进行量化:
- 后量化:量化又可以分为后量化(PTQ)、训练时量化(Mixed Precision)、量化感知训练(QAT)。后量化相比于训练时量化,是一种更加高效的对于预训练模型部署的加速方式。
(本文章主要对推理时的模型量化(后量化)进行详解,并不涉及训练时的混合精度)
本篇文章详解了推理时不同精度的量化手段、实现方法,同时对比了不同精度量化的实现效果,对此部分内容感兴趣的xdm继续看下去吧!
二、什么是模型量化?
2.1 不同的数值格式
在计算机中存储数字的一些众所周知的格式有 float32 (FP32)、float16 或(FP16)、int8、bfloat16。这些格式中的每一种都会消耗不同的内存块。例如,float32 为符号分配 1 位,为指数分配 8 位,为尾数分配 23 位:
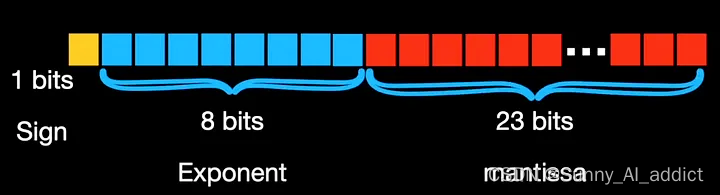
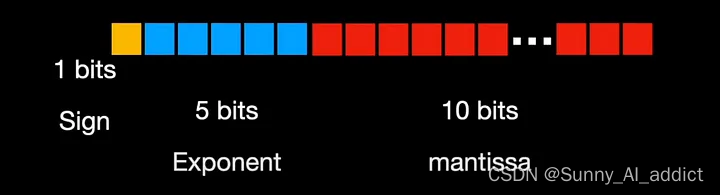
类似地,float16 或 FP16 为符号分配 1 位,但为指数分配 5 位,为尾数分配 10 位:
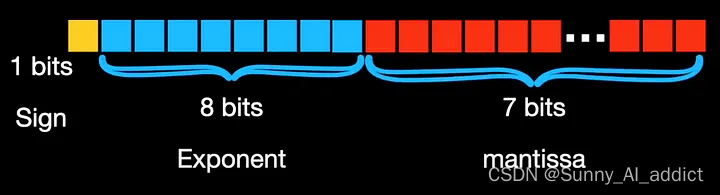
BF16 为指数分配 8 位,为尾数分配 7 位:
(关于更详细的数值类型介绍,请参考深度学习模型权重数值精度FP32,FP16,INT8数值类型区别_fp32模型-CSDN博客)
对于量化位数,可以有很多种选择。大体可分为:
- FP16量化:比较保险的做法,大多数情况下可以不丢失太多精度的情况下有明显的性能提升。因为都是浮点,相对来说容易
- INT8量化:是比较常见的,也是相对成熟的。相关的研究很多,各种主流框架也基本都支持。
- INT8位以下:目前而言学界相对玩得多些,工业界有少量支持,但还没有太成熟。8位以下主要是4,2和1位(因为位数为2的幂次性能会更好,也更容易实现;llama.cpp项目就可以量化为8、4 位整数);如果精度低至1位,也就是二值化,那可以用位运算进行计算。这对处理器而言是很友好的。
2.2 模型量化的定义
简而言之,所谓的模型量化就是将浮点存储/运算转换为整型存储/运算的一种模型压缩技术。简单直白点讲,即原来表示一个权重需要使用float32/float16表示,量化后只需要使用int8来表示就可以啦,仅仅这一个操作,我们就可以获得接近4倍的网络加速。
三、量化类型
模型量化就是建立一种浮点数据和整型数据间的映射关系,使得以较小的精度损失代价获得了较大的收益,要弄懂模型量化的原理就是要弄懂这种数据映射关系,这种数据映射可以是线性的,也可以是非线性的。
3.1 线性量化
根据数据映射关系,可以分为线性量化和非线形量化
常见的线性量化过程可以用以下数学表达式来表示:
- q:原始的float32数值;
- Z:float32数值的偏移量,又叫Zero Point;
- S:float32的缩放因子,又叫Scale;
- Round(⋅) :四舍五入近似取整的数学函数,除了四舍五入,使用向上或者向下取整也可以;
- r:量化后的整数值;
根据参数 Z 是否为零又可以将线性量化分为两类——对称量化和非对称量化。
3.1.1 对称量化
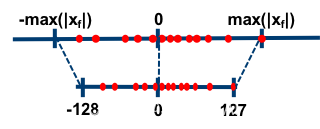
所谓的对称量化,即使用一个映射公式将输入数据映射到[-128,127]的范围内,如下图所示。
图中-max(|Xf|)表示的是输入数据的最小值,max(|Xf|)表示输入数据的最大值。
对称量化的一个核心即零点的处理,映射公式需要保证原始的输入数据中的零点通过映射公式后仍然对应[-128,127]区间的零点。
在对称量化中,r 是用有符号的整型数值(int8)来表示的,此时 Z=0,且 q=0时恰好有r=0。在对称量化中,我们可以取Z=0,S的取值可以使用如下的公式,也可以采用其它的公式:
(其中,n 是用来表示该数值的位宽,x 是数据集的总体样本 )
因计算机内部用补码表示,其表示范围不是关于0对称的。因此对于对称量化,会将整型值域最小值去掉,如8位有符号整型表示范围[-128, 127],截取后变成[-127, 127]。这样整型值域才是直正的对称,否则会产生偏差。
在实际应用中,如果模型权重的分布通常是关于0对称的高斯分布,那比较适用用对称量化。
3.1.2 非对称量化
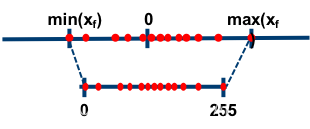
如上图所示,所谓的非对称量化,即使用一个映射公式将输入数据映射到[0,255](非零对称)的范围内,图中min(Xf)表示的是输入数据的最小值,max(Xf)表示输入数据的最大值。
在非对称量化中,我们可以取Z=min(x),S的取值可以使用如下的公式,也可以采用其它的公式:
相比而言,非对称量化优点是能够更充分利用比特位,因为对于对称量化而言,碰到dynamic range关于0两边严重不对称的话(比如经过ReLU后的activation),会比较低效。但这也是有代价的,即计算更加复杂。
而ReLU后的激活值是没有负数的,因此适用于非对称量化。另外,如果非对称量化中整个值域都落在正区间,那就可以用无符号整型表示,否则用有符号整型。
3.2 非线形量化
线性量化会导致有更多的信息丢失,因为一般来说,神经网络训练中的动态值中肯定有些区域点密集、有些稀疏。相应地,有均匀量化就有非均匀量化(非线形量化)。
非线形量化是指量化等级间不等长,如log quantization。再高级一点,那就是通过学习来得到更大自由度的映射(可通过查找表表示)。
相较于先行量化,非线形量化能达到更高的准确率,但它的缺点是不利于硬件加速。
(想了解更多关于非线性量化的内容,请参考x x)
3.3 逐层量化、逐组量化和逐通道量化
根据量化的粒度(共享量化参数的范围)可以分为逐层量化、逐组量化和逐通道量化
- 全局量化:即整个网络使用相同的量化参数。一般来说,对于8位量化,全局量化参数影响不明显,但到更低精度,就会对准确率有较大影响
- 逐层量化(per-layer):以一个层为单位,整个layer的权重共用一组缩放因子S和偏移量Z;
- 逐组量化以组为单位(per-group):每个group使用一组S和Z;
- 逐通道量化则以通道为单位(per-channel):每个channel单独使用一组S和Z;
当 group=1 时,逐组量化与逐层量化等价;当 group=num_head时,逐组量化逐通道量化等价。
3.3 权重量化、权重激活量化
根据需要量化的参数可以分类两类:权重量化和权重激活量化。
- 权重量化:即仅仅需要对网络中的权重执行量化操作。由于网络的权重一般都保存下来了,因而我们可以提前根据权重获得相应的量化参数S和Z。量化weight可达到减少模型大小和memory footprint等目的;但是由于仅仅对权重执行了量化,这种量化方法的压缩力度不是很大。
- 权重激活量化:即不仅对网络中的权重进行量化,还对激活值进行量化。实际中激活往往是占内存使用的大头,因此量化激活不仅可以大大减少memory footprint。更重要的是,结合权重的量化可以充分利用整数计算获得性能提升;但由于激活层的范围通常不容易提前获得,因而需要在网络推理的过程中进行计算或者根据模型进行大致的预测。
3.4 在线量化和离线量化
根据激活值的量化实时性与否,可以分为动态量化和静态量化。
- 动态量化:激活值的S和Z在实际推断过程中根据实际的激活值动态计算
- 静态量化:提前确定好激活值的S和Z;由于不需要动态计算量化参数,通常离线量化的推断速度更快些
对于静态量化通常,通过以下的三种方法来确定相关的量化参数。:
- MinMax:是使用最简单也是较为常用的一种采样方法。基本思想是直接从FP32张量中选取最大值和最小值来确定实际的动态范围
- 指数平滑法:即将校准数据集送入模型,收集每个量化层的输出特征图,计算每个batch的S和Z值,并通过指数平滑法来更新S和Z
- 直方图截断法:即在计算量化参数Z和S的过程中,由于有的特征图会出现偏离较远的奇异值,导致max非常大,所以可以通过直方图截取的形式,比如抛弃最大的前1%数据,以前1%分界点的数值作为max计算量化参数
- KL散度校准法:即通过计算KL散度(也称为相对熵,用以描述两个分布之间的差异)来评估量化前后的两个分布之间存在的差异,搜索并选取KL散度最小的量化参数Z和S作为最终的结果。Tensorflow中就采用了这种方法
四、Pytorch量化支持
在Pytorch中,有三种类型的量化支持,即上述的动态量化、静态量化,以及量化感知训练。
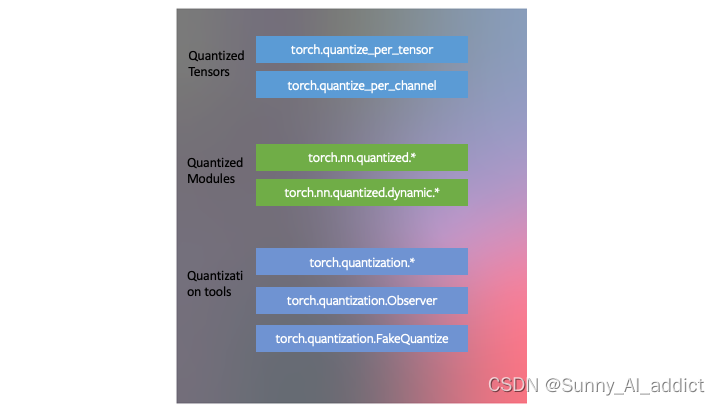
PyTorch支持:
- 具有与quantized tensor相对应的数据类型,它们共享tensor的许多特征
- 通用操作的量化模块,作为torch.nn.quantized和torch.nn.quantized.dynamic命名空间的一部分
- 量化与PyTorch的其他部分兼容:量化模型是可跟踪和可脚本化的。对于服务器端和移动后端,量化方法实际上是相同的。可以很容易地在模型中混合量子化和浮点运算。
- 浮点张量到quantized tensor的映射可以用用户定义的observer/fake-quantization模块进行定制。
4.1 后训练动态量化实现
PyTorch支持的最简单的量化方法是动态量化。这涉及将weight转为INT8,对activation的转换是动态的。activation从内存读写时是以浮点形式的,但会在计算前进行量化,因此计算是以INT8精度来进行。
在PyTorch中有一个简单的动态量化API:torch.quantization.quantize_dynamic,接受一个模型,以及其他几个参数,并产生一个量子化模型,其使用的代码很简单,以下是一个应用案例:
import torch.quantization
quantized_model = torch.quantization.quantize_dynamic(model, {torch.nn.Linear}, dtype=torch.qint8)
4.2 后训练静态量化实现
这涉及将weight转为INT8,计算也是用INT8精度进行。区别在于对activation的量化参数是事先通过一些数据来确定而不是动态来确定。这样便可以省下内存访问和动态量化(避免先转成浮点,再量化成整型)的开销,因此性能较后训练动态量化会高一些。
静态量化需要执行额外的步骤:
- 准备模型:通过添加QuantStub和DeQuantStub模块,指定在何处显式量化和反量化激活值;确保不重复使用模块;将需要重新量化的任何操作转换为模块的模式;
- 指定量化方法的配置,例如选择对称或非对称量化、MinMax或L2Norm校准技术、选择per-layer或是per-group量化;
- 插入torch.quantization.prepare()模块来在校准期间观察激活张量;
- 使用校准数据集对模型执行校准操作;
- 使用torch.quantization.convert() 模块来转化模型,具体包括计算并存储每个激活张量要使用的比例和偏差值,并替换关键算子的量化实现等。
根据Pytorch API 的易用性,在预训练模型myModel上执行训练后静态量化的三行代码如下:
# set quantization config for server (x86)
deploymentmyModel.qconfig = torch.quantization.get_default_config('fbgemm')
# insert observers
torch.quantization.prepare(myModel, inplace=True)
# Calibrate the model and collect statistics
# convert to quantized version
torch.quantization.convert(myModel, inplace=True)
五、量化的实现效果
模型量化实现建立在深度网络对噪声具有一定的容忍性上,模型量化相当于对深度网络增加了一定的噪声(量化误差),如果量化位数合适,模型量化基本不会造成较大的精度损失。
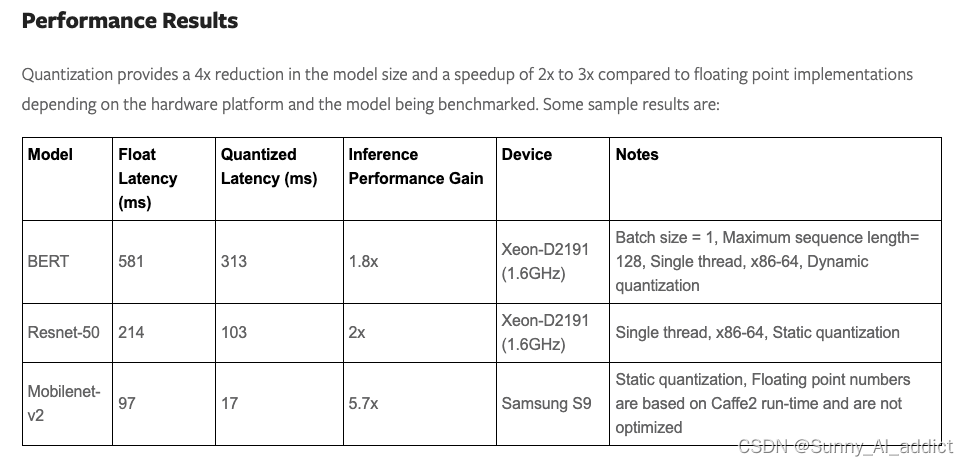
对于何种情况使用何种量化精度、何种量化方式,那就要具体问题具体分析了。
六、总结
所谓的模型量化就是将浮点存储(运算)转换为整型存储(运算)的一种模型压缩技术。随着神经网络大而深的发展方向,该技术可以极大地缩小模型的大小,进而提高模型的运行速度,从而满足工程上的各种需求。
但是,模型量化还是一个亟待研究的领域,其中目前量化的难点包括但不限于:
1、一些特殊层支持的不是很好,量化损失较大。如concat层,当两个不同分布范围差异较大的数据合并到一起后,由于使用同一套量化参数,分布范围小的数据很容易损失精度。
2、模型任务越复杂,模型越小,量化损失越大,量化越难。
3、一些特殊的数据分布难以被量化模型较好的表示。
希望在这个领域,能够有更多更加有效地适合工业界的方法出现~
参考:
https://hackernoon.com/zh/%E6%B7%B1%E5%BA%A6%E7%A5%9E%E7%BB%8F%E7%BD%91%E7%BB%9C%E4%B8%AD%E7%9A%84%E6%A8%A1%E5%9E%8B%E9%87%8F%E5%8C%96https://hub.baai.ac.cn/view/11362
【模型推理】谈谈几种量化策略:MinMax、KLD、ADMM、EQ_51CTO博客_量化策略介绍
Quantization — PyTorch master documentation

















 2008
2008

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









