







看这篇阅读笔记之前,可以看一下以下这篇前言,不仅从performance方面分析了XLNet的效果,也从算力和时间消耗方面分析该工作:一份有趣的 XLNet 阅读笔记前言
摘要(Abstract)
与基于自回归语言建模(AR LM)的预训练语言建模方法相比,基于降噪自编码的预训练方法具有良好的双向上下文建模能力。然而,由于依赖于使用Masked tokens 破坏输入,BERT忽略了掩码位置之间的依赖关系,并出现了pretrain-finetune 差异。针对这些优缺点,我们提出了XLNet,这是一种广义的自回归预训练方法: (1)通过最大化因子分解顺序所有排列的期望可能性来实现双向上下文的学习,(2)通过自回归公式克服了BERT的局限性。此外,XLNet还将来自Transformer-XL(最先进的自回归模型)的思想集成到该预训练工作中。从经验上看,XLNet在20项任务中表现优于BERT,并且在18项任务中取得了最先进的结果,包括问题回答、自然语言推理、情感分析和文档排序。
引言(Introduction)
无监督表示学习在自然语言处理领域非常成功[7,19,24,25,10]。通常,这些方法首先在大规模标记的文本语料库上预先训练神经网络,然后对下游任务的模型或表示进行微调。在这个共享的高层次思想下,文献中探讨了不同的无监督预训练目标。其中,自回归(AR)语言建模和自动编码(AE)是两个最成功的预训练目标.
AR语言建模试图用自回归模型估计文本语料库的概率分布[7,24,25]。具体地,给定文本序列 ,AR语言建模将可能性分解为前向乘积
或后向乘积
。训练参数模型(例如,神经网络)以模拟每个条件分布。由于AR语言模型仅被训练为编码单向文本(向前或向后),因此在建模深度双向上下文时无效。相反,下游语言理解任务通常需要双向上下文信息。这导致AR语言建模与有效预训练之间存在差距。
相比之下,基于AE的预训练不执行显式密度估计,而是旨在从输入重构原始数据。一个值得注意的例子是BERT [10],它采用了最先进的预训练方法。给定输入令牌序列,令牌的某一部分被特殊符号[MASK]替换,并且训练模型以从损坏的版本恢复原始令牌。由于密度估计不是目标的一部分,因此允许BERT利用双向上下文进行重建。作为一个直接的好处,这关闭了AR语言建模中的双向信息差距,从而提高了性能。然而,在训练期间,BERT在预训练时使用的[MASK]等人工符号在实际数据中不存在,从而导致预训练的网络差异。此外,由于预测的令牌在输入中重新掩盖,因此BERT无法使用乘积规则对联合概率进行建模,如在语言建模中一样。换句话说,BERT假设预测的tokens与给定的未掩盖的tokens相互独立,由于高阶,远程依赖在自然语言中是普遍存在的,因此过度调整[9]。
与现有语言预训练目标的利弊相比,在这项工作中,我们提出了一种广义的自回归方法,它利用了AR语言建模和AE的优点,同时避免了它们的局限性。
首先,不再像传统的AR模型那样使用固定的前向或后向分解顺序,XLNet最大化了序列的预期对数似然性分解顺序的所有可能排列。由于置换操作,每个位置的上下文可以包含来自左侧和右侧的令牌。在期望中,每个位置学习利用来自所有位置的上下文信息,即捕获双向上下文。
其次,作为通用AR语言模型,XLNet不依赖于数据损坏。因此,XLNet不会受到BERT受到的预训练 - 微调差异的影响。同时,自回归目标还提供了一种自然的方式来使用乘积规则来分解预测的令牌的联合概率,从而消除了在BERT中做出的独立性假设。
除了新的预训练目标外,XLNet还改进了预训练的架构设计。
XLNet将Transformer-XL [9]的分段循环机制和相对编码方案集成到预训练中,从而凭经验改进了性能,特别是对于涉及较长文本序列的任务。
将Transformer(-XL)架构简单地应用于基于排列的语言建模不起作用,因为分解顺序是任意的并且目标是不明确的。作为解决方案,我们建议重新参数化Transformer(-XL)网络以消除歧义。
根据实验,XLNet在18个任务上实现了最先进的结果,即7个GLUE语言理解任务,3个阅读理解任务,包括SQUAD和RACE,7个文本分类任务,包括Yelp和IMDB,以及ClueWeb09-B文档排名任务。在一系列公平比较实验中,XLNet在多个基准测试中始终优于BERT [10]。
XLNet本质上是顺序感知的位置编码。 这对于语言理解很重要,因为无序模型被简化为词袋,缺乏基本的表达能力。 上述差异源于动机的根本差异 - 之前的模型旨在通过将“无序”归纳偏差融入模型来改善密度估计,而XLNet的动机是通过启用AR语言模型来学习双向上下文。
模型(Proposed Method)
2.1 背景知识(background)
1) AR language modeling performs pretraining by maximizing the likelihood under the forward autoregressive factorization:
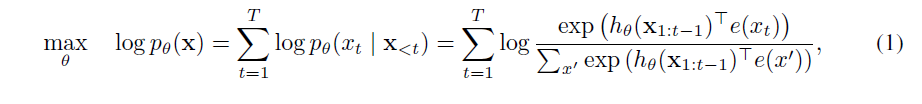
where is a context representation produced by neural models, such as RNNs or Transformers, and e(x) denotes the embedding of x.
2) AE pretrain(BERT)
BERT is based on denoising auto-encoding. Specifically, for a text sequence x, BERT first constructs a corrupted version by randomly setting a portion (e.g. 15%) of tokens in x to a special symbol [MASK]. Let the masked tokens be
. The training objective is to reconstruct
from
:
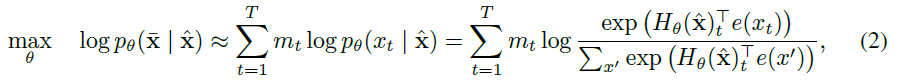
where indicates
is masked, and H is a Transformer that maps a length-T text sequence x into a sequence of hidden vectors
. The pros and cons of the two pretraining objectives are compared in the following aspects:

2.2 objective:Premutation Language Modeling(PLM)

根据上面提到的AR与AE各有优缺点,如何综合他们各自的优点,规避两者的缺点,借用NADE的思想实现,提出了PLM:
PLM 目标不仅保留了AR模型的优点,而且允许模型捕获双向上下文。具体来说,对于长度为T的序列x,有T!种有效的自回归因子分解的不同顺序。直观地说,如果模型参数在所有因子分解顺序中共享,那么预期模型将学会从两边的所有位置收集信息。
为了实现PLM,假设长度为T的文本的所有因式分解顺序集合 ,该集合中每一个元素是一种order
, 然后假设这一种order中有:
.
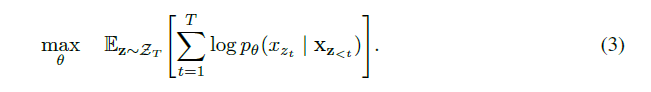
2.3 Architecture:Two-Stream Self-Attention fot Target-Aware Representation

(3)式在transformer中, , where
denotes the hidden representation of
.
但是上面的表示并没有你考虑位置因素,则引入考虑了相对位置的函数:
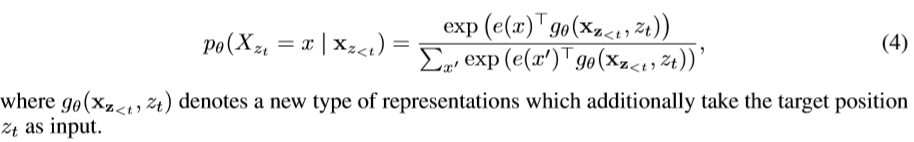
接下来讲解Two-stream Self-Attention:(直接post原文,这样更直观)

因为收敛慢,所以Partial Prediction:While the permutation language modeling objective (3) has several benefits, it is a much more challenging optimization problem due to the permutation and causes slow convergence in preliminary experiments. To reduce the optimization difficulty, we choose to only predict the last tokens in a factorization order. Formally, we split z into a non-target subsequence z and a target subsequence
, where c is the cutting point. The objective is to maximize the log-likelihood of the target subsequence conditioned on the non-target subsequence, i.e.,

2.4 Incorporating Ideas from Transformer-XL

2.5 Modeling Multiple Segments
当有多个片段时,两两选择作为现有模型的输入,需要外部加入一个判断是否是来自于同一个内容的判别编码。
2.6 Discussion and Analysis(基于一个例子比较BERT和XLNet)
Example: [New, York, is, a, city] and suppose [New,York] as the prediction targets.XLNet factorization order [is, a, city, New, York]
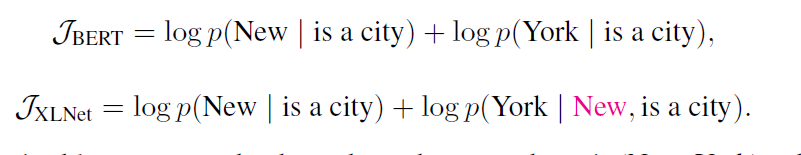

总之这一部分的实验证明:XLNet并没有独立性假设,但是BERT假设了待预测词(Mask)是相互独立的。
Experiments
1. RACE(阅读理解任务)

2.SQuAD1.1 和 SQuAD2.0 数据集(阅读理解任务)

3. 7个文本分类任务(文本分类)

4.9个GLUE 语言理解任务(语言理解任务)

5.文档排序任务(document ranking task)

另外做了一些消融实验证明有些成分加入的必要性:

conclusions
XLNet is a generalized AR pretraining method that uses a permutation language modeling objective to combine the advantages of AR and AE methods. The neural architecture of XLNet is developed to work seamlessly with the AR objective, including integrating Transformer-XL and careful design of the two-stream attention mechanism. XLNet achieves state-of-the-art results various tasks with substantial improvement. In the future, we envision applications of XLNet to a wider set of tasks such as vision and reinforcement learning.
XLNet是一种广义的AR预训练方法,它利用 permutation language modeling(PLM)的目标,结合AR方法和AE方法的优点。XLNet的神经结构被开发成与AR目标无缝工作,包括集成Transformer-XL和精心设计的两流注意机制( two-stream attention mechanism)。XLNet实现了最先进的结果,大大改进了各种任务。在未来,我们将XLNet应用于更广泛的任务,如视觉和强化学习。















 603
603











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









