










Paper 链接:XLNet: Generalized Autoregressive Pretraining for Language Understanding
Abstract
与基于自回归语言建模(AR LM)的预训练语言建模方法相比,基于降噪自编码的预训练方法具有良好的双向上下文建模能力。然而,由于Bert需要 mask 一部分输入,忽略了被 mask 位置之间的依赖关系,因此出现预训练和微调效果的差异(pretrain-finetune discrepancy)。针对这些优缺点,我们提出了XLNet,这是一种广义的自回归预训练方法: (1)通过最大化所有可能的因式分解顺序的对数似然,学习双向语境信息;(2)通过自回归公式克服了BERT的局限性。此外,XLNet还将来自Transformer-XL(最先进的自回归模型)的思想集成到该预训练工作中。从经验上看,XLNet在20项任务中表现优于BERT,并且在18项任务中取得了最先进的结果,包括问题回答、自然语言推理、情感分析和文档排序。
AR 与 AE 两大阵营

自回归语言模型(AutoRegressive LM)
在 ELMO/BERT 出来之前,大家通常讲的语言模型其实是根据上文内容预测下一个可能跟随的单词,就是常说的自左向右的语言模型任务,或者反过来也行(就是根据下文预测前面的单词)。这种类型的 LM 被称为自回归语言模型。GPT 就是典型的自回归语言模型。ELMO 尽管看上去利用了上文,也利用了下文,但是本质上仍然是自回归 LM,这个跟模型具体怎么实现有关系。ELMO 是分别做了两个方向的自回归 LM(从左到右以及从右到左两个方向的语言模型),然后把 LSTM 的两个方向的隐状态拼接到一起,来体现双向语言模型这个事情的。所以其本质上仍然是自回归语言模型
给定文本序列
x
=
[
x
1
,
…
,
x
T
]
\mathbf {x}=[x_1,…,x_T]
x=[x1,…,xT],语言模型的目标是调整参数使得训练数据上的似然函数最大:
$
m
a
x
θ
log
p
θ
(
x
)
=
∑
t
=
1
T
log
p
θ
(
x
t
∣
x
<
t
)
=
∑
t
=
1
T
log
exp
(
h
θ
(
x
1
:
t
−
1
)
T
e
(
x
t
)
)
∑
x
′
exp
(
h
θ
(
x
1
:
t
−
1
)
T
e
(
x
′
)
)
\underset{\theta}{max}\; \log p_\theta(\mathbf{x})=\sum_{t=1}^T \log p_\theta(x_t \vert \mathbf{x}_{<t})=\sum_{t=1}^T \log \frac{\exp(h_\theta(\mathbf{x}_{1:t-1})^T e(x_t))}{\sum_{x'}\exp(h_\theta(\mathbf{x}_{1:t-1})^T e(x'))}
θmaxlogpθ(x)=t=1∑Tlogpθ(xt∣x<t)=t=1∑Tlog∑x′exp(hθ(x1:t−1)Te(x′))exp(hθ(x1:t−1)Te(xt))
记号 x < t \mathbf {x}_{<t} x<t 表示 t t t 时刻之前的所有 x x x ,也就是 x 1 : t − 1 \mathbf {x}_{1:t-1} x1:t−1 。 h θ ( x 1 : t − 1 ) h_\theta (\mathbf {x}_{1:t-1}) hθ(x1:t−1) 是 RNN 或者 Transformer(注:Transformer 也可以用于语言模型,比如在 OpenAI GPT)编码的 t 时刻之前的隐状态。 e ( x ) e(x) e(x) 是词 x x x 的 embedding
自回归语言模型的缺点是无法同时利用上下文的信息,貌似 ELMO 这种双向都做,然后拼接看上去能够解决这个问题,但其实融合方法过于简单,所以效果其实并不是太好。它的优点跟下游 NLP 任务有关,比如生成类 NLP 任务,比如文本摘要,机器翻译等,在实际生成内容的时候,就是从左向右的,自回归语言模型天然匹配这个过程。而 Bert 这种 DAE(Denoise AutoEncoder)模式,在生成类 NLP 任务中,面临训练过程和应用过程不一致的问题,导致生成类的 NLP 任务到目前为止都做不太好。
自编码语言模型(AutoEncoder LM)
BERT 通过将序列
x
\mathbf x
x 中随机挑选 15% 的 Token 变成 [MASK] 得到带噪声版本的
x
^
\hat {\mathbf x}
x^ 。假设被 Mask 的原始值为
x
‾
\overline {\mathbf x}
x,那么 BERT 希望尽量根据上下文恢复(猜测)出原始值,也就是:
m
a
x
θ
log
p
θ
(
x
ˉ
∣
x
^
)
≈
∑
t
=
1
T
m
t
log
p
θ
(
x
t
∣
x
^
)
=
∑
t
=
1
T
m
t
log
exp
(
H
θ
(
x
)
t
T
e
(
x
t
)
)
∑
x
′
exp
(
H
θ
(
x
)
t
T
e
(
x
′
)
)
\underset{\theta}{max}\;\log p_\theta(\bar{\mathbf{x}} | \hat{\mathbf{x}}) \approx \sum_{t=1}^Tm_t \log p_\theta(x_t | \hat{\mathbf{x}})=\sum_{t=1}^T m_t \log \frac{\exp(H_\theta(\mathbf{x})_{t}^T e(x_t))}{\sum_{x'}\exp(H_\theta(\mathbf{x})_{t}^T e(x'))}
θmaxlogpθ(xˉ∣x^)≈t=1∑Tmtlogpθ(xt∣x^)=t=1∑Tmtlog∑x′exp(Hθ(x)tTe(x′))exp(Hθ(x)tTe(xt))
上式中,若 m t = 1 m_t=1 mt=1 表示 t t t 时刻是一个 Mask,需要恢复。 H θ \mathit H_\theta Hθ 是一个 Transformer,它把长度为 T T T 的序列 x \mathbf x x 映射为隐状态的序列 H θ ( x ) = [ H θ ( x ) 1 , H θ ( x ) 2 , . . . , H θ ( x ) T ] H_\theta (\mathbf {x})=[H_\theta (\mathbf {x})_1, H_\theta (\mathbf {x})_2, ..., H_\theta (\mathbf {x})_T] Hθ(x)=[Hθ(x)1,Hθ(x)2,...,Hθ(x)T] 。注意:前面的语言模型的 RNN 在 t t t 时刻只能看到之前的时刻,因此记号是 h θ ( x 1 : t − 1 ) h_\theta (\mathbf {x}_{1:t-1}) hθ(x1:t−1) ;而 BERT 的 Transformer(不同与用于语言模型的 Transformer)可以同时看到整个句子的所有 Token,因此记号是 H θ ( x ) H_\theta (\mathbf {x}) Hθ(x)
这种 AE LM 的优缺点正好和 AR LM 反过来,它能比较自然地融入双向语言模型,同时看到被预测单词的上文和下文,这是好处。缺点是啥呢?主要在输入侧引入 [Mask] 标记,导致预训练阶段和 Fine-tuning 阶段不一致的问题,因为 Fine-tuning 阶段是看不到 [Mask] 标记的
XLNet 的出发点就是:能否融合AR LM 和 DAE LM 两者的优点。具体来说就是,站在 AR 的角度,如何引入和双向语言模型等价的效果。
Permutation Language Model
作者们发现,只要在 AR 以及 AE 方式中再加入一个步骤,就能够完美地将两者统一起来,那就是 Permutation

具体实现方式是,通过随机取一句话排列的一种,然后将末尾一定量的词给 “遮掩”(和 BERT 里的直接替换 “[MASK]” 有些不同)掉,最后用 AR 的方式来按照这种排列方式依此预测被 “遮掩” 掉的词
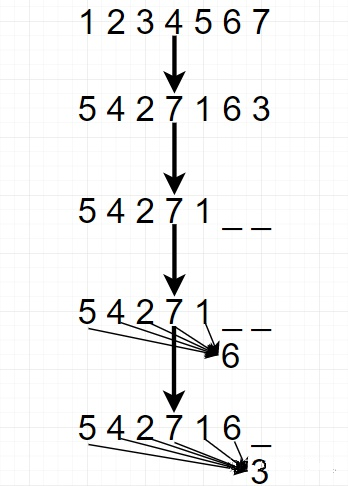
这里我稍微解释下,为什么是 “遮掩” 末尾的一些词,以及随机打乱句子的顺序有什么用?输入句子正常的顺序是 “1 2 3 4 5 6 7”,常规的自回归 LM 无法同时考虑上下文信息。如果能够同时考虑上下文信息,那 “3” 这个词,需要有 “1 2 4 5 6 7” 这些信息,换句话说,在预测 “3” 之前,我们需要保证模型已经看过 “1 2 4 5 6 7”(无所谓顺序)。而打乱句子的顺序之后(比方说上图的例子),3 这个词就来到了句子的末尾,此时按照自回归 LM 预测 “3” 的时候,模型已经看过了 “1 2 4 5 6 7”,由此便考虑到了 “3” 的上下文信息。当然,句子到底怎么打乱是无所谓的,因为我们的目标不是具体要预测哪个词,而是谁在最后,就预测谁。
这里再谈一个有意思的点,到底该挑选最后几个做遮掩呢?作者这里设了一个超参数 K,K 等于总长度除以需要预测的个数。拿上面的例子,总长为 7 而需要预测为 2,于是 K = 7/2。而论文中实验得出的最佳 K 值介于 6 和 7 (更好)之间,其实如果我们取 K 的倒数(即 ),然后转为百分比,就会发现最佳的比值介于 14.3% 到 16.7% 之间,还记得 BERT 论文的同学肯定就会开始觉得眼熟了。因为 BERT 里将 Token 遮掩成 “[MASK]” 的百分比就是 15%,正好介于它们之间,我想这并不只是偶然,肯定有更深层的联系
对于一个长度为 T T T 的句子,我们可以遍历 T ! T! T! 种排列,然后学习语言模型的参数,但是这个计算量非常大(10 个词的句子就有 10!=3628800 种组合)。因此实际我们只随机的采样 T ! T! T! 里的部分排列,为了用数学语言描述,我们引入几个记号。 Z T \mathcal {Z}_T ZT 表示长度为 T T T 的序列的所有排列组成的集合,则 z ∈ Z T z\in \mathcal {Z}_T z∈ZT 是其中一种排列方法。我们用 z t z_t zt 表示排列的第 t t t 个元素,而 z < t z_{<t} z<t 表示 z z z 的第 1 到第 t − 1 t-1 t−1 个元素
有了上面的记号,则 Permutation LM 的目标是调整模型参数使得下面的似然概率最大:
m
a
x
θ
E
z
∼
Z
T
[
∑
t
=
1
T
log
p
θ
(
x
z
t
∣
x
z
<
t
)
]
\underset{\theta}{max} \mathbb{E}_{z \sim \mathcal{Z}_T}[\sum_{t=1}^T\log p_\theta(x_{z_t}|\mathbf{x}_{z_{<t}})]
θmaxEz∼ZT[t=1∑Tlogpθ(xzt∣xz<t)]
上面的公式看起来有点复杂,细读起来其实很简单:从所有的排列中采样一种,然后根据这个排列来分解联合概率成条件概率的乘积,然后加起来
论文中 Permutation 具体的实现方式不是打乱输入句子的顺序,而是通过对 Transformer 的 Attention Mask 进行操作
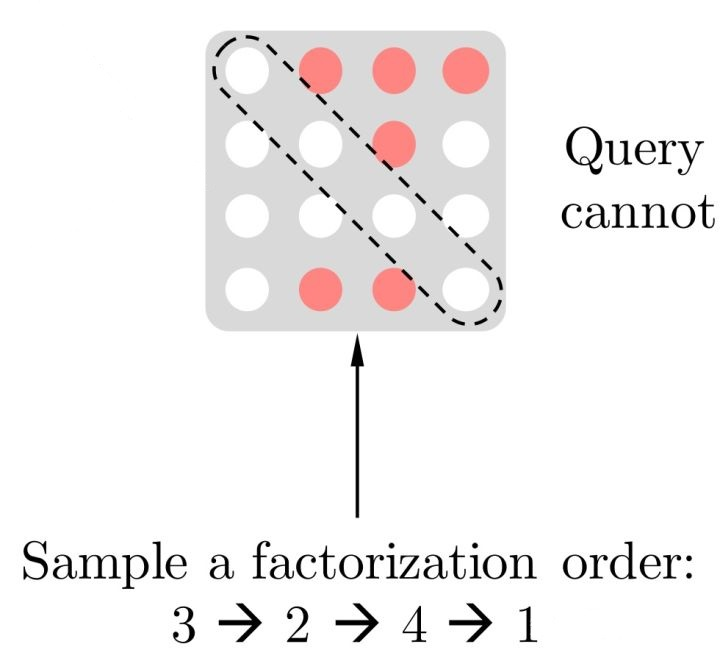
比如说序号依次为 1234 的句子,先随机取一种排列 3241。根据这个排列我们就做出类似上图的 Attention Mask,先看第 1 行,因为在新的排列方式中 1 在最后一个,根据从左到右 AR 方式,1 就能看到 234 全部,于是第一行的 234 位置是红色的(没有遮盖掉,会用到),以此类推,第 2 行,因为 2 在新排列是第二个,只能看到 3 于是 3 位置是红色,第 3 行,因为 3 在第一个,看不到其他位置,所以全部遮盖掉。
没有目标 (target) 位置信息的问题
上面的思想很简单,但是如果我们使用标准的 Transformer 实现时会有问题。下面举个例子
假设输入的句子是”I like New York”,并且一种排列为 z=[1, 3, 4, 2],假设我们需要预测的是
z
3
=
4
z_3=4
z3=4,那么根据 Simple LM 的公式:
p
θ
(
X
z
3
=
x
∣
x
z
1
z
2
)
=
p
θ
(
X
4
=
x
∣
x
1
x
3
)
=
exp
(
e
(
x
)
T
h
θ
(
x
1
x
3
)
)
∑
x
′
exp
(
e
(
x
′
)
T
h
θ
(
x
1
x
3
)
)
p_\theta(X_{z_3}=x|x_{z_1z_2})=p_\theta(X_4=x|x_1x_3)=\frac{\exp(e(x)^Th_\theta(x_1x_3))}{\sum_{x'}\exp(e(x')^Th_\theta(x_1x_3))}
pθ(Xz3=x∣xz1z2)=pθ(X4=x∣x1x3)=∑x′exp(e(x′)Thθ(x1x3))exp(e(x)Thθ(x1x3))
我们通常用大写的 X X X 表示随机变量,比如 X 4 X_4 X4,而小写的 x x x 表示某一个具体取值,比如假设 x x x 是 “York”,则 p θ ( X 4 = x ) p_\theta (X_4=x) pθ(X4=x) 表示第 4 个词是 York 的概率。用自然语言描述: p θ ( X 4 = x ) p_\theta (X_4=x) pθ(X4=x) 表示的是第一个词是 I,第 3 个词是 New 的条件下第 4 个词是 York 的概率
另外我们再假设一种排列为 z’=[1,3,2,4],我们需要预测
z
3
=
2
z_3=2
z3=2,那么:
p
θ
(
X
z
3
=
x
∣
x
z
1
z
2
)
=
p
θ
(
X
2
=
x
∣
x
1
x
3
)
=
exp
(
e
(
x
)
T
h
θ
(
x
1
x
3
)
)
∑
x
′
exp
(
e
(
x
′
)
T
h
θ
(
x
1
x
3
)
)
p_\theta(X_{z_3}=x|x_{z_1z_2})=p_\theta(X_2=x|x_1x_3)=\frac{\exp(e(x)^Th_\theta(x_1x_3))}{\sum_{x'}\exp(e(x')^Th_\theta(x_1x_3))}
pθ(Xz3=x∣xz1z2)=pθ(X2=x∣x1x3)=∑x′exp(e(x′)Thθ(x1x3))exp(e(x)Thθ(x1x3))
我们先不管预测的真实值是什么,先假设 x x x 是 “York” 时的概率,则 p θ ( X 2 = x ∣ x 1 x 3 ) p_\theta (X_2=x|x_1x_3) pθ(X2=x∣x1x3) 表示的是第一个词是 I,第 3 个词是 New 的条件下第 2 个词是 York 的概率
我们仔细对比一下上面两个公式会发现它们是相等的。但是根据经验,显然这两个概率是不同的,而且上面的那个概率大一些,因为 York 跟在 New 之后是一个城市,而”York New” 是什么呢?
上面问题的关键是模型并不知道要预测的那个词在原始序列中的位置。了解 Transformer 的读者可能会问:不是输入了位置编码吗?位置编码的信息不能起作用吗?注意:位置编码是和输入的 Embedding 加到一起作为输入的,因此 p θ ( X 2 = x ∣ x 1 x 3 ) p_\theta (X_2=x|x_1x_3) pθ(X2=x∣x1x3) 里的 x 1 , x 3 x_1,x_3 x1,x3 是带了位置信息的,模型(可能)知道(根据输入的向量猜测)“I” 是第一个词,而 New 是第三个词,但是第四个词的向量显然还不知道(知道了就不用预测了),因此就不可能知道它要预测的词到底是哪个位置的词,所以我们必须 “显式” 的告诉模型我要预测哪个位置的词
为了后面的描述,我们再把上面的两个公式写出更加一般的形式。给定排列 z,我们需要计算
p
θ
(
X
z
t
∣
x
z
<
t
=
x
)
p_\theta (X_{z_t} \vert \mathbf {x}_{z_{<t}}=x)
pθ(Xzt∣xz<t=x),如果我们使用普通的 Transformer,那么计算公式为:
p
θ
(
X
z
t
=
x
∣
x
z
<
t
)
=
exp
(
e
(
x
)
T
h
θ
(
x
z
<
t
)
)
∑
x
′
exp
(
e
(
x
′
)
T
h
θ
(
x
z
<
t
)
)
p_\theta(X_{z_t}=x \vert \mathbf{x}_{z_{<t}})=\frac{\exp(e(x)^Th_\theta(\mathbf{x}_{z_{<t}}))}{\sum_{x'}\exp(e(x')^Th_\theta(\mathbf{x}_{z_{<t}}))}
pθ(Xzt=x∣xz<t)=∑x′exp(e(x′)Thθ(xz<t))exp(e(x)Thθ(xz<t))
根据前面的讨论,我们知道问题的关键是模型并不知道要预测的到底是哪个位置的词,为了解决这个问题,我们把预测的位置
z
t
z_t
zt 放到模型里:
p
θ
(
X
z
t
=
x
∣
x
z
<
t
)
=
exp
(
e
(
x
)
T
g
θ
(
x
z
<
t
,
z
t
)
)
∑
x
′
exp
(
e
(
x
′
)
T
g
θ
(
x
z
<
t
,
z
t
)
)
p_\theta(X_{z_t}=x \vert \mathbf{x}_{z_{<t}})=\frac{\exp(e(x)^Tg_\theta(\mathbf{x}_{z_{<t}}, z_t))}{\sum_{x'}\exp(e(x')^Tg_\theta(\mathbf{x}_{z_{<t}}, z_t))}
pθ(Xzt=x∣xz<t)=∑x′exp(e(x′)Tgθ(xz<t,zt))exp(e(x)Tgθ(xz<t,zt))
上式中 g θ ( x z < t , z t ) g_\theta (\mathbf {x}_{z_{<t}}, z_t) gθ(xz<t,zt) 表示这是一个新的模型 g g g,并且它的参数除了之前的词 x z < t \mathbf {x}_{z_{<t}} xz<t,还有要预测的词的位置 z t z_t zt
Two-Stream Self-Attention
接下来的问题是用什么模型来表示 g θ ( x z < t , z t ) g_\theta (\mathbf {x}_{z_{<t}}, z_t) gθ(xz<t,zt) 。当然有很多种可选的函数(模型),我们需要利用 x z < t \mathbf {x}_{z_{<t}} xz<t ,通过 Attention 机制提取需要的信息,然后预测 z t z_t zt 位置的词。那么它需要满足如下两点要求:
- 为了预测 x z t \mathbf {x}_{z_{t}} xzt, g θ ( x z < t , z t ) g_\theta (\mathbf {x}_{z_{<t}}, z_t) gθ(xz<t,zt) 只能使用位置信息 z t z_t zt 而不能使用 x z t \mathbf {x}_{z_{t}} xzt。这是显然的:你预测一个词当然不能知道要预测的是什么词
- 为了预测 z t z_t zt 之后的词, g θ ( x z < t , z t ) g_\theta (\mathbf {x}_{z_{<t}}, z_t) gθ(xz<t,zt) 必须编码了 x z t \mathbf {x}_{z_{t}} xzt 的信息(语义)
但是上面两点要求对于普通的 Transformer 来说是矛盾的无法满足的。这里非常重要,所以我这里再啰嗦一点举一个例子
假设输入的句子还是”I like New York”,并且一种排列为 z = [ 1 , 3 , 4 , 2 ] z=[1, 3, 4, 2] z=[1,3,4,2],假设 t = 2 t=2 t=2(即 ) z t = z 2 = 3 z_t=z_2=3 zt=z2=3,我们现在要计算 g θ ( x z < t , z t ) g_\theta (\mathbf {x}_{z_{<t}}, z_t) gθ(xz<t,zt),也就是给定第一个位置的词为 “I”,预测第三个位置为 “New” 的概率。显然我们不能使用 “New” 本身的信息,而只能根据第一个位置的 “I” 来预测。假设我们非常幸运的找到了一很好的函数 g g g,它可以能够比较好的预测这个概率 g θ ( x 1 , z 2 ) g_\theta (x_1, z_2) gθ(x1,z2)。现在我们轮到计算 t = 3 t=3 t=3(即 z 3 = 4 z_3=4 z3=4 ),也就是根据 g θ ( x 1 , z 2 ) g_\theta (x_1, z_2) gθ(x1,z2) 和 z t z_t zt 来预测 “York”。显然,知道第三个位置是 “New” 对于预测第四个位置是 “York” 会非常有帮助,但是 g θ ( x 1 , z 2 ) g_\theta (x_1, z_2) gθ(x1,z2) 并没有 New 这个词的信息。读者可能会问:你不是说 g g g 可以比较好的根据第一个词 “I” 预测第三个词 “New” 的概率吗?这里有两点:“I” 后面出现 “New” 的概率并不高;在预测 “York” 时我们是知道第三个位置是 New 的,只不过由于模型的限制,我们无法重复利用这个信息
为了解决这个问题,论文引入了两个 Stream,也就是两个隐状态:
- 内容隐状态 h θ ( x z < t ) h_\theta (\mathbf {x}_{z_{<t}}) hθ(xz<t),简写为 h z t h_{z_t} hzt,它就和标准的 Transformer 一样,既编码上下文(context)也编码 x z t \mathbf {x}_{z_{t}} xzt 的内容
- 查询隐状态 g θ ( x z < t , z t ) g_\theta (\mathbf {x}_{z_{<t}}, z_t) gθ(xz<t,zt) ,简写为 g z t g_{z_t} gzt ,它只编码上下文和要预测的位置 z t z_t zt,但是不包含 x z t \mathbf {x}_{z_{t}} xzt
下面我们介绍一下计算过程。我们首先把查询隐状态 g i ( 0 ) g_i^{(0)} gi(0) 初始化为一个变量 w w w,把内容隐状态 h i ( 0 ) h_i^{(0)} hi(0) 初始化为词的 Embedding e ( x i ) e (x_i) e(xi)。这里的上标 0 表示第 0 层(不存在的层,用于计算第一层)。因为内容隐状态可以编码当前词,因此初始化为词的 Embedding 是比较合适的
接着从 m=1 一直到第 M 层,逐层计算:
g
z
t
(
m
)
←
A
t
t
e
n
t
i
o
n
(
Q
=
g
z
t
(
m
−
1
)
,
K
V
=
h
z
<
t
(
m
−
1
)
;
θ
)
h
z
t
(
m
)
←
A
t
t
e
n
t
i
o
n
(
Q
=
h
z
t
(
m
−
1
)
,
K
V
=
h
z
≤
t
(
m
−
1
)
;
θ
)
\begin{split} g_{z_t}^{(m)} & \leftarrow Attention(Q=g_{z_t}^{(m-1)},KV=h_{\color{red} {z_{<t}}}^{(m-1)};\theta) \\ h_{z_t}^{(m)} & \leftarrow Attention(Q=h_{z_t}^{(m-1)},KV=h_{\color{red} {z_{\le t}}}^{(m-1)};\theta) \end{split}
gzt(m)hzt(m)←Attention(Q=gzt(m−1),KV=hz<t(m−1);θ)←Attention(Q=hzt(m−1),KV=hz≤t(m−1);θ)
Query Stream: use
z
t
z_t
zt but cannot see
x
z
t
\mathbf {x}_{z_{t}}
xzt
Content Stream: use both
z
t
z_t
zt and
x
z
t
\mathbf {x}_{z_{t}}
xzt
上面两个流分别使用自己的 Query 向量 g z t g_{z_t} gzt 和 Content 向量 h z t h_{z_t} hzt;但是 Key 和 Value 向量都是用的 h h h。但是注意 Query 流不能访问 z t z_t zt 的内容,因此 K 和 V 是 h z < t ( m − 1 ) h_{z_{<t}}^{(m-1)} hz<t(m−1)。而 Content 流的 KV 是 h_{z_{<=t}}^{(m-1)},它包含 x z t \mathbf {x}_{z_{t}} xzt
上面的梯度更新和标准的 Self Attention 是一样的。在 fine-tuning 的时候,我们可以丢弃掉 Query 流而只用 Content 流。最后在计算公式的时候我们可以用最上面一层的 Query 向量 g z t ( M ) g_{z_t}^{(M)} gzt(M)
我们可以通过下图来直观的了解计算过程
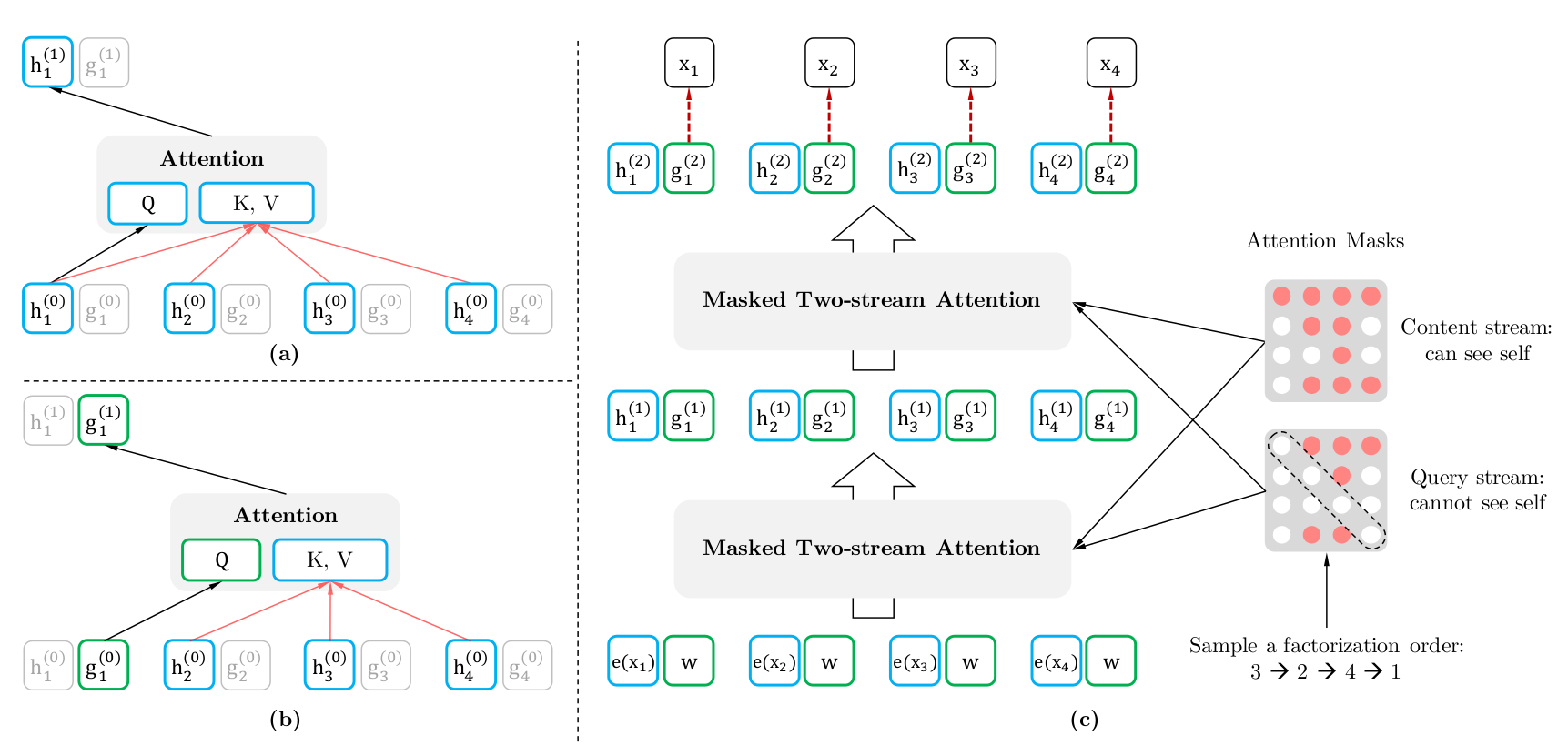
左上图是 Content 流的计算,假设排列为 3 → 2 → 4 → 1 3→2→4→1 3→2→4→1,并且我们现在预测第 1 个位置的词的概率。根据排列,我们可以参考所有 4 个词的 Content,因此 K & V = [ h 1 ( 0 ) , h 2 ( 0 ) , h 3 ( 0 ) , h 4 ( 0 ) ] K\&V=[h_1^{(0)},h_2^{(0)},h_3^{(0)},h_4^{(0)}] K&V=[h1(0),h2(0),h3(0),h4(0)],而 Q = h 1 ( 0 ) Q=h_1^{(0)} Q=h1(0)
左下图是 Query 流的计算,因为不能参考自己的内容,因此 K & V = [ h 2 ( 0 ) , h 3 ( 0 ) , h 4 ( 0 ) ] K\&V=[h_2^{(0)},h_3^{(0)},h_4^{(0)}] K&V=[h2(0),h3(0),h4(0)],而 Q = g 1 ( 0 ) Q=g_1^{(0)} Q=g1(0)
图的右边是完整的计算过程,我们从下往上看。首先 h h h 和 g g g 分别被初始化为 e ( x i ) e (x_i) e(xi) 和 W W W,然后 Content Mask 和 Query Mask 计算第一层的输出 h ( 1 ) h^{(1)} h(1) 和 g ( 1 ) g^{(1)} g(1),然后计算第二层……。注意最右边的两个 Mask,我们先看 Content Mask。它的第一行全是红点,表示第一个词可以 attend to 所有的词(根据 3 → 2 → 4 → 1 3→2→4→1 3→2→4→1),第二个词可以 attend to 它自己和第三个词……。而 Query Mask 和 Content Mask 的区别就是不能 attend to 自己,因此对角线都是白点
到此为止,XLNet 的核心思想已经比较清楚了。主要使用 LM,但是为了解决上下文的问题,引入了 Permutation LM。Permutation LM 在预测时需要 target 的位置信息,因此通过引入 Two-Stream,Content 流编码到当前时刻的内容,而 Query 流只参考之前的历史以及当前要预测位置。最后为了解决计算量过大的问题,对于一个句子,我们只预测后 1 K \frac {1}{K} K1 个词
XLNet 借鉴了 Transformer-XL 的优点,它对于长文本的上下文的处理是要优于传统的 Transformer 的。关于Transformer-XL,可以参考:Transformer-XL 论文精读

















 451
451











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











