






概要
在阅读FasterNet的过程中,提到了Depthwise Convolution(深度卷积),于是阅读了Xception的论文,对Depthwise Separable Convolution(深度可分离卷积)进行了学习理解。本文对于深度可分离卷积的理解来自Xception: Deep Learning with Depthwise Separable Convolutions这篇论文。
在本文章中,我用DSConv来表示Depthwise Separable Convolution。
DSConv由两部分组成:DepthWise Conv和PointWise Conv. 对这两个部分的解释我在本文下方给出了解释。
需要注意一点,Xception中的深度可分离卷积和传统的深度可分离卷积有细微区别,传统DwConv先对每个通道卷积,再对所有通道做1*1卷积,而Xception中的DwConv则是先对所有输入图像的所有通道进行1*1的卷积得到Feature Map,再由每个Kernel对1*1卷积的Outputs中的每个通道进行卷积,总结就是DepthWise Conv和PointWise Conv的顺序相反
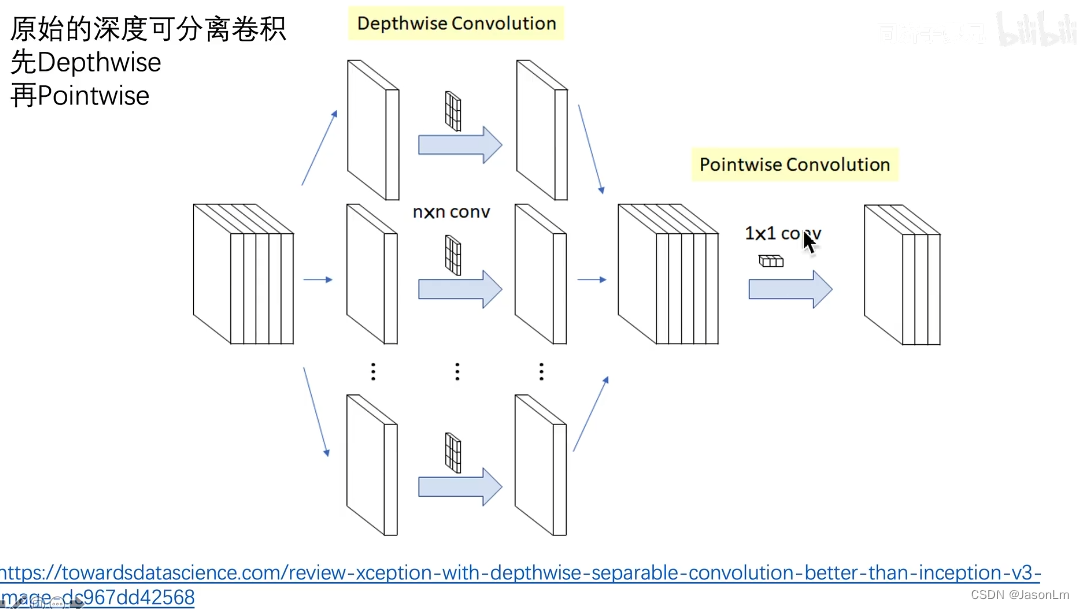
上图是FasterNet中提到DwConv(深度卷积)的示意图
阅读Xception论文的记录:
概念
Inception是介于传统卷积和深度可分离卷积的中间形态
Xception彻底解耦为深度可分离卷积
不同卷积Kernel与Channel的关系
普通卷积中:一个Kernel处理所有Channel
深度可分离卷积:一个Kernel处理一个Channel
Inception模块中:一个Kernel处理的通道数可以调节,介于普通卷积和深度可分离卷积之间
性能优势
论文中提到,Xception的参数量和Inception V3相近,但由于采用了DSConv可以减少大量参数量和计算量,减少模型大小(关于计算/参数量为什么减少详细见MobileNet论文)
DwConv卷积介绍
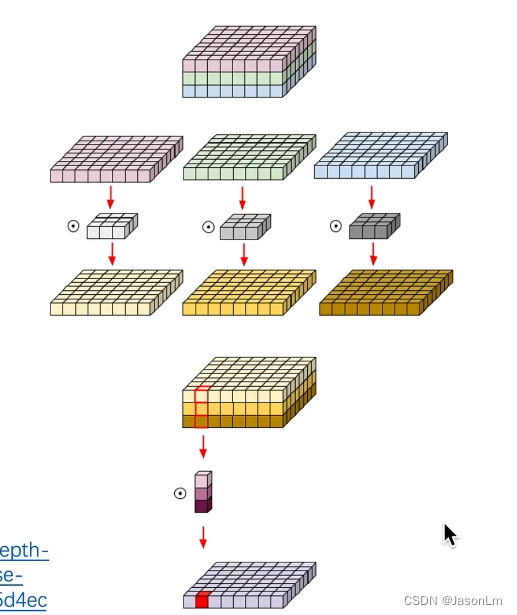
深度可分离卷积示意图
在深度可分离卷积当中,包含两个步骤Dethpwise Conv和Pointwise Conv,针对每一个Channel,采用一个Kernel进行卷积操作,该操作只对长宽方向的信息(每一个通道平面)进行处理。
但是若只处理长宽方向信息会造成信息丢失,为了补充跨通道信息,用1*1卷积,对跨通道维度进行处理,得到一个新的feature map,有多少个1*1卷积核,就得到多少个channel的feature map,这里只用了一个,所以只得到了一个feature map。红色感受野与紫色卷积核对应位置权重相乘(点乘)求和,填在feature map对应位置上。
Dethpwise Conv 处理长宽方向的空间信息,Pointwise Conv 1*1卷积处理跨通道的信息,这样就把两种信息解耦了。
若您不知道什么是卷积,下面是补充知识,为您展示了普通卷积的过程
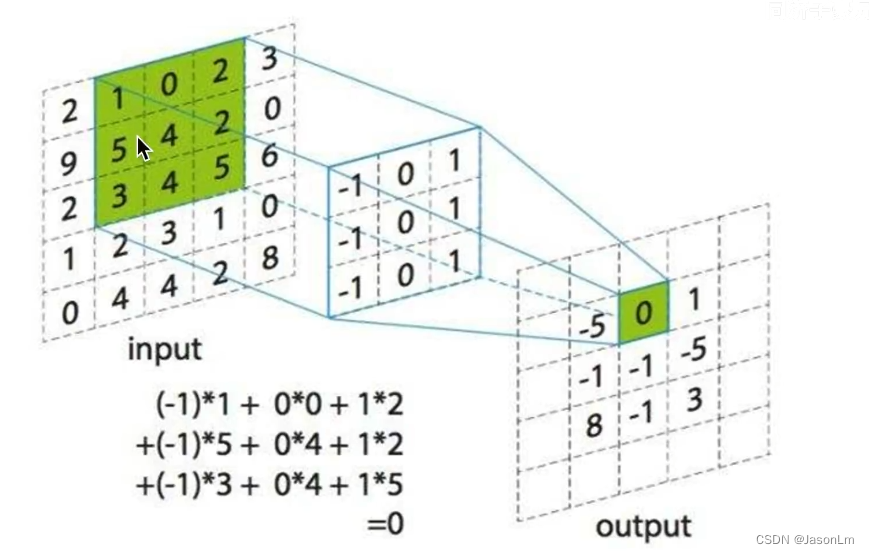
input中绿色感受野与卷积核对应位置权重相乘(点乘)求和示意图
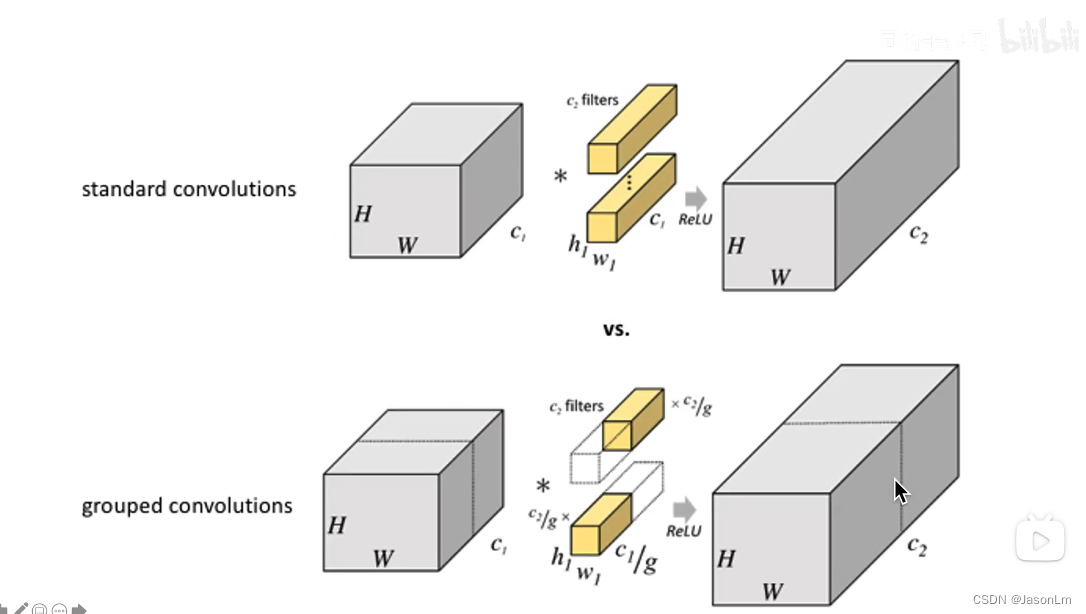
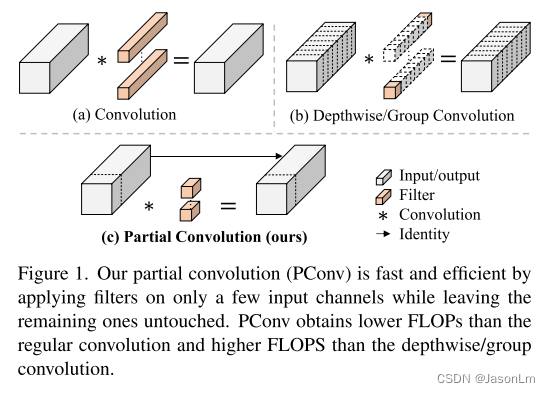
Group Convolution(组卷积)/Depthwise Convolution(深度卷积)示意图
参考论文地址:
Xception:https://arxiv.org/abs/1610.02357
FasterNet:https://arxiv.org/abs/2303.03667
参考学习地址:
https://www.bilibili.com/video/BV1Gb4y1m7e3?p=2&vd_source=aed42df4b6ffa54b23d443fb8f0ecd1b

















 968
968

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









