







论文题目:Adaptive Rectangular Convolution for Remote Sensing Pansharpening
中文题目:基于自适应矩形卷积的遥感全色锐化
所属单位:电子科技大学
核心速览:本文提出了一种名为Adaptive Rectangular Convolution (ARConv)的创新卷积模块,用于改进遥感图像的Pansharpening技术。ARConv能够自适应地调整卷积核的高度和宽度,并动态改变采样点的数量,从而有效捕捉图像中不同大小物体的特定尺度特征,优化核尺寸和采样位置。结合ARConv模块,作者还提出了ARNet网络架构,并通过多个数据集的广泛评估,证明了该方法在提升Pansharpening性能方面优于先前的技术。
论文代码已打包好,文章末尾扫码名片自取 
论文研究背景:
-
研究问题:在遥感图像处理领域,如何将低分辨率多光谱图像(LRMS)与高分辨率全色图像(PAN)融合,以生成高分辨率多光谱图像(HRMS),是当前研究的重要问题。这一过程被称为Pansharpening。高质量的遥感图像对于军事应用、农业等多个领域至关重要。
-
研究难点:现有的Pansharpening技术存在局限性,尤其是在特征提取方面。传统卷积模块的采样位置固定在一个确定大小的正方形窗口内,且卷积核的采样点数量是预先设定且不变的。这些刚性参数导致无法有效适应遥感图像中不同物体的尺度差异,从而影响特征提取的效率。
-
文献综述:文章提到了多种针对Pansharpening的卷积方法,包括空间自适应卷积、形状自适应卷积和多尺度卷积等。这些方法虽然在一定程度上提高了特征提取的灵活性,但仍然存在一些问题,如形状自适应卷积的参数数量随着核大小的增加而呈二次方增长,导致在小数据集上难以收敛;多尺度卷积的核大小是预先确定的,无法适应图像中不同尺度的特征模式和结构。基于这些分析,作者提出了ARConv模块,旨在克服现有技术的不足。
论文贡献
-
自适应矩形卷积(ARConv):提出了一种新的卷积模块,能够根据输入图像中不同对象的大小动态学习高度和宽度自适应的卷积核,并根据学习到的尺度动态调整采样点的数量。ARConv通过学习两个参数(卷积核的高度和宽度)来实现采样位置的自适应调整,而不需要随着卷积核尺寸的增加而增加额外的计算负担。此外,引入仿射变换增强ARConv的空间适应性。
-
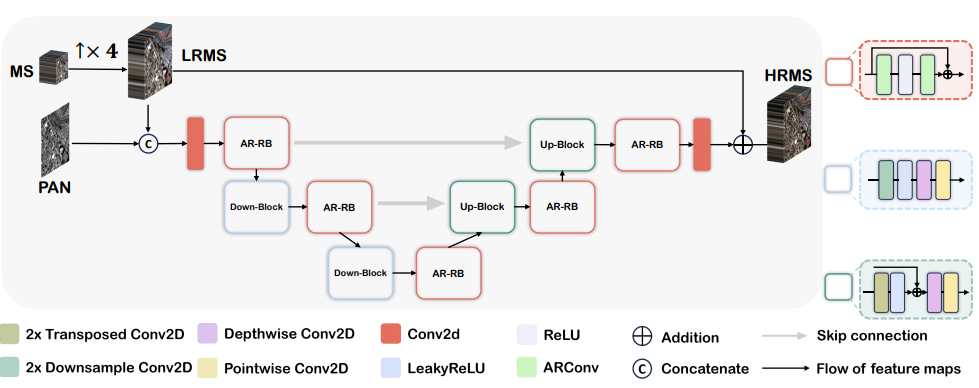
ARNet网络架构:基于U-net架构,将标准卷积层替换为ARConv模块,形成ARNet。ARNet通过一系列下采样和上采样步骤,利用不同深度的ARConv层来适应不同尺度的特征提取,最终将学习到的细节注入到低分辨率多光谱图像中,生成高分辨率多光谱图像。
论文创新
一、ARConv
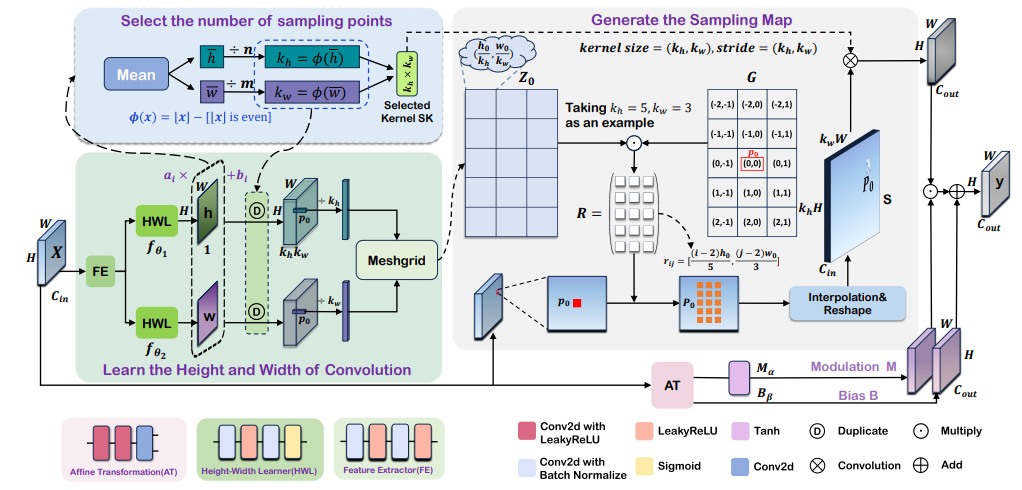
ARConv动态地根据输入图像中对象的大小来调整卷积核的尺寸和采样点的数量,从而有效地捕获不同尺度特征。实现步骤:
1、学习卷积核的高度和宽度:ARConv通过两个子网络来预测卷积核的高度和宽度。这两个子网络共享一个特征提取器,并且各自包含一个用于学习高度和宽度的特定学习器。学习得到的高度和宽度特征图分别表示为y1和y2,它们通过Sigmoid函数进行归一化处理,得到的值在0到1之间,表示相对大小。为了将这些相对大小转换为实际的卷积核尺寸,引入了两个调制因子a和b,通过公式yi = ai * yi + bi来约束卷积核的高度和宽度范围。
2、选择采样点的数量:首先计算y1和y2的平均值,得到学习到的高度和宽度的平均水平。然后,根据高度和宽度的平均值,通过一个函数ϕ(x) = x — [x is even]来确定卷积核在垂直和水平方向上的采样点数量。这个函数确保了卷积核的采样点数量为奇数。如果计算得到的采样点数量为偶数,则选择最接近的奇数。
3、生成采样图:在标准卷积中,使用规则网格G对输入特征图X进行采样,然后用权重w对这些采样值进行加权求和。ARConv使用一个偏移矩阵G来表示标准卷积的偏移量,并计算每个像素位置p0的缩放矩阵Z0。然后,通过元素间乘法计算ARConv在位置p0的偏移矩阵R。由于采样点通常不与网格点中心重合,因此需要使用双线性插值来估计它们的像素值。
4、卷积操作的实现:将每个像素位置的采样点值提取出来,组成一个新的网格P0,这个网格取代了原始像素p0。对每个像素完成这样的扩展后,得到最终的采样图S。然后对采样图S应用卷积操作,使用设置为(kh, kw)的卷积核大小和步长进行特征提取。为了引入空间适应性,对输出特征图应用仿射变换。
二、ARNet
实验分析
本文在多个数据集上进行了广泛的评估,结果显示 ARConv 方法在提升 pansharpening 性能方面优于已有技术,并通过消融研究和可视化进一步验证了 ARConv 的有效性。具体的数据集名称在文中未提及。
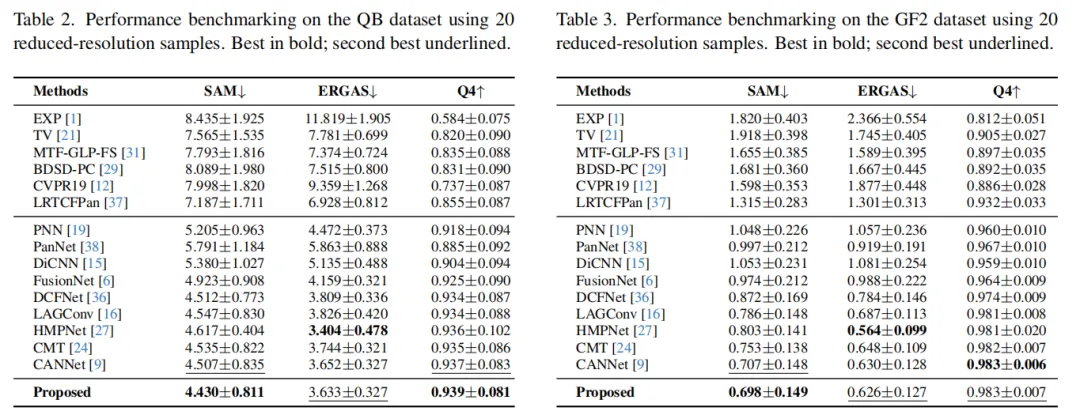
1. 数据集与评估指标:在WorldView3(WV3)、QuickBird(QB)和GaoFen-2(GF2)传感器捕获的图像数据集上进行评估。使用不同分辨率的测试集,并采用SAM、ERGAS、Q8、Ds、Dλ和HQNR等指标进行性能评估。
2. 训练细节:所有实验使用l1损失函数和Adam优化器,批量大小为16。初始学习率为0.0006,每200个周期学习率衰减0.8倍。探索阶段为100个周期,之后随机选择一组卷积核采样点组合并固定。
3. 性能基准测试:与包括传统方法和基于深度学习的方法在内的多种方法进行比较,包括EXP、MTF-GLP-FS、TV、LRTCFPan、PNN、PanNet、DiCNN、FusionNet、DCFNet、LAGConv、HMPNet、CMT和CANNet等。ARNet在多个数据集上表现出色,特别是在全分辨率数据集上,HQNR指标显示ARNet的性能优于其他方法。ARNet的输出图像与真实图像最为接近,证明了其在不同对象尺寸和尺度上的特征提取能力。

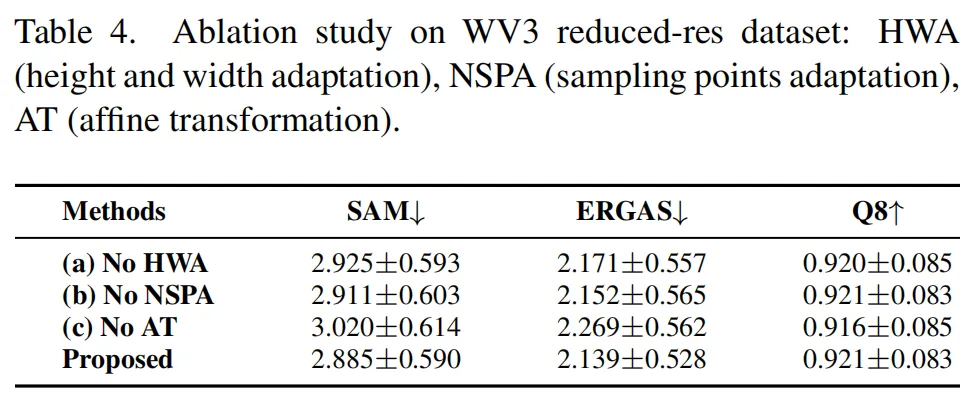
4. 消融研究:通过移除ARConv中的不同组件(高度和宽度自适应、采样点自适应、仿射变换)进行消融实验,结果表明ARConv在适应不同对象尺寸方面非常有效。仿射变换的引入显著提高了模型的灵活性。
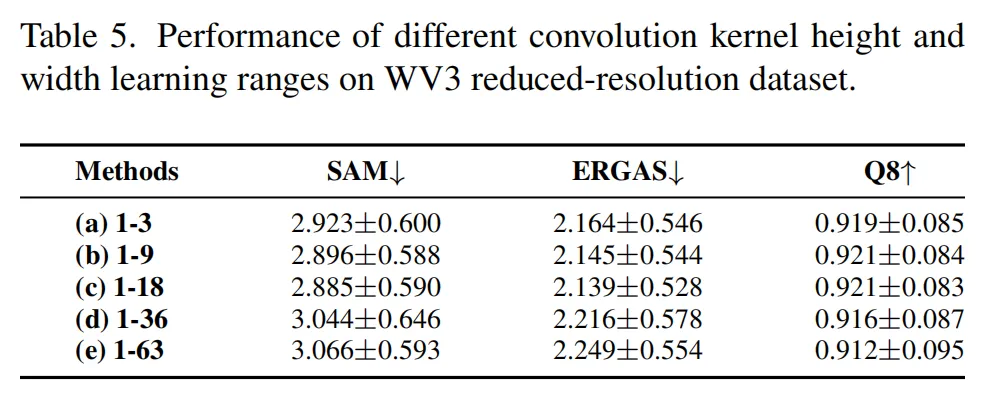
5. 不同高度和宽度学习范围的影响:通过设计不同的卷积核高度和宽度学习范围进行实验,结果表明ARNet的性能随着学习范围的增加而提高,但超过一定范围后性能会下降。
结论
1. ARConv的有效性:ARConv模块能够根据输入图像中对象的大小动态调整卷积核的尺寸和采样点数量,有效捕获不同尺度的特征,显著提升了遥感图像的融合性能。
2. ARNet的优越性:将ARConv集成到U-net架构中形成的ARNet,在多个数据集上均展现出卓越的性能,特别是在全分辨率数据集上,ARNet的HQNR指标最高,证明了其在保持光谱信息和空间细节方面的优势。
3. 未来展望:ARConv和ARNet为遥感图像融合任务提供了新的解决方案,未来的研究可以进一步探索ARConv在其他图像处理任务中的应用潜力。

















 1312
1312

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









