









1. 定义与概述
大模型,顾名思义,是指具有极高参数量、复杂度和强大表示能力的深度学习模型。这类模型通过在海量的数据上进行训练,能够学习到丰富的知识和模式,从而在多种任务上展现出卓越的性能。大模型不仅限于自然语言处理(NLP)领域,如GPT系列、BERT等,也逐渐渗透到计算机视觉、强化学习等其他人工智能领域。它们的出现标志着人工智能向更通用、更智能的方向迈进了一大步。
大模型是指具有大规模参数和复杂计算结构的机器学习模型。"这些模型通常由深度神经网络构建而成,拥有数十亿甚至数千亿个参数。大模型的设计目的是为了提高模型的表达能力和预测性能,能够处理更加复杂的任务和数据。大模型在各种领域都有广泛的应用,包括自然语言处理、计算机视觉、语音识别和推荐系统等。大模型通过训练海量数据来学习复杂的模式和特征,具有更强大的泛化能力,可以对未见过的数据做出准确的预测。
ChatGPT对大模型的解释更为通俗易懂,也更体现出类似人类的归纳和思考能力:大模型本质上是一个使用海量数据训练而成的深度神经网络模型,其巨大的数据和参数规模,实现了智能的涌现,展现出类似人类的智能。

那么,大模型和小模型有什么区别?
小模型通常指参数较少、层数较浅的模型,它们具有轻量级、高效率、易于部署等优点,适用于数据量较小、计算资源有限的场景,例如移动端应用、嵌入式设备、物联网等。
而当模型的训练数据和参数不断扩大,直到达到一定的临界规模后,其表现出了一些未能预测的、更复杂的能力和特性,模型能够从原始训练数据中自动学习并发现新的、更高层次的特征和模式,这种能力被称为“涌现能力"。而且备通现能力的机器学习模型就被认为是独立意义上的大模型,这也是其和小模型最大意义上的区别。
相比小模型,大模型通常参数较多、层数较深,具有更强的表达能力和更高的准确度,但也需要更多的计算资源和时间来训练和推理,适用于数据量较大、计算资源充足的场景,例如云端计算、高性能计算、人工智能等。
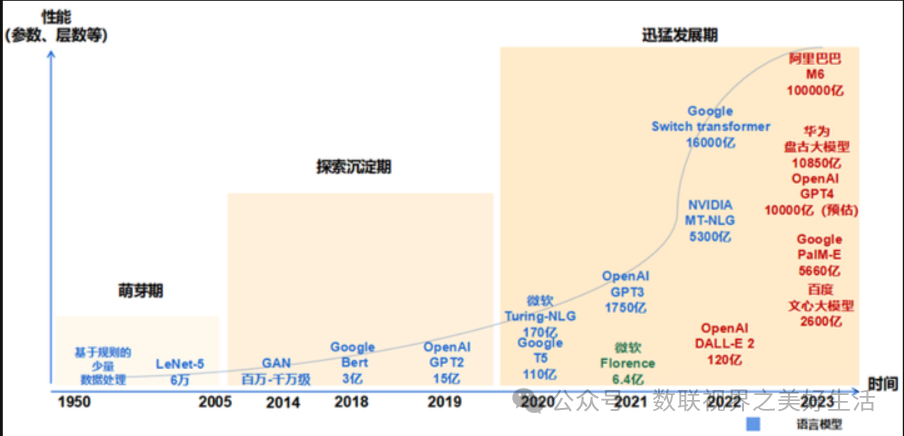
2022年11月30日,OpenAI推出一款人工智能对话聊天机器人ChatGPT其出色的自然语言生成能力引起了全世界范围的广泛关注,2个月突破1亿用户,国内外随即掀起了一场大模型浪潮,Gemini、文心一言、Copilot、LLaMA、SAM、SORA等各种大模型如雨后春笋般涌现,2022年也被誉为大模型元年。
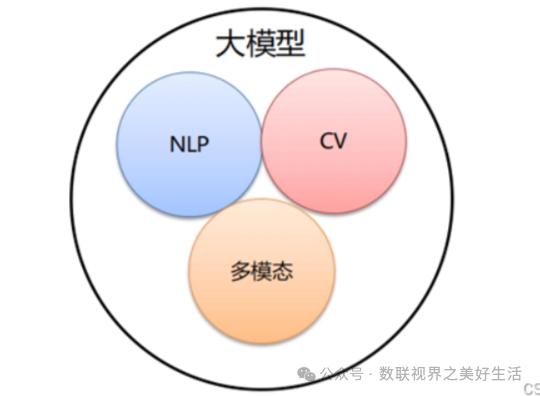
大模型分类:
1、语言大模型(NLP):是指在自然语言处理(Natural Language Processing,NLP)领域中的一类大模型,通常用于处理文本数据和理解自然语言。这类大模型的主要特点是它们在大规模语料库上进行了训练,以学习自然语言的各种语法、语义和语境规则。例如:GPT系列(OpenAl)、文心一言等。
2、视觉大模型(CV):是指在计算机视觉(Computer Vision,CV)领域中使用的大模型,通常用于图像处理和分析。这类模型通过在大规模图像数据上进行训练,可以实现各种视觉任务,如图像分类、目标检测、图像分割、姿态估计、人脸识别等。
3、多模态大模型:是指能够处理多种不同类型数据的大模型,例如文本、图像、音频等多模态数据。这类模型结合了 NLP 和 CV 的能力,以实现对多模态信息的综合理解和分析,从而能够更全面地理解和处理复杂的数据。
按照应用领域的不同,大模型主要可以分为L0、L1、L2 三个层级:
通用大模型 L0:是指可以在多个领域和任务上通用的大模型。它们利用大算力、使用海量的开放数据与具有巨量参数的深度学习算法在大规模无标注数据上进行训练,以寻找特征并发现规律,进而形成可“举一反三"的强大泛化能力,可在不进行微调或少量微调的情况下完成多场景任务,相当于 AI完成了“通识教育”。
行业大模型L1:是指那些针对特定行业或领域的大模型。它们通常使用行业相关的数据进行预训练或微调,以提高在该领域的性能和准确度,相当于 A| 成为“行业专家”。
垂直大模型L2:是指那些针对特定任务或场景的大模型。它们通常使用任务相关的数据进行预训练或微调,以提高在该任务上的性能和效果。
2. 技术架构基础
大模型的技术架构主要建立在分布式计算系统和高效的深度学习框架之上。为了处理庞大的数据量和计算需求,大模型训练通常依赖于高性能计算集群(HPC)或云计算平台,利用多GPU、TPU等硬件加速技术。在软件层面,TensorFlow、PyTorch等深度学习框架提供了灵活的模型定义、高效的计算图优化以及自动微分等关键功能,为大模型的构建和训练提供了强大的支持。
3. 数据处理与清洗
数据是大模型性能的关键因素。在训练前,需要对原始数据进行严格的清洗和预处理,包括去除噪声、处理缺失值、归一化/标准化、文本分词与编码等步骤。此外,由于大模型需要处理的数据量巨大,高效的数据加载和流式处理机制也至关重要。数据增强技术也被广泛应用以增加模型的泛化能力。
4. 模型结构与算法
大模型的结构往往复杂且多样,包括多层Transformer结构、残差网络(ResNet)、密集连接网络(DenseNet)等。这些结构的设计旨在提高模型的表达能力和深度,同时减少训练过程中的梯度消失或爆炸问题。算法上,通常采用梯度下降法或其变种(如Adam优化器)来优化模型参数,并通过预训练-微调范式来提高模型在不同任务上的适应性。
5. 训练与优化策略
大模型的训练是一个计算密集型和资源消耗巨大的过程。为了加速训练过程,常采用混合精度训练、梯度累积、学习率调度等策略。同时,为了防止过拟合,会采用正则化技术(如Dropout、L1/L2正则化)、早停法等手段。此外,通过知识蒸馏、模型剪枝等技术可以在保持模型性能的同时减少其规模和计算复杂度。
6. 应用场景与案例
大模型在多个领域展现出了广泛的应用潜力。在自然语言处理领域,它们可以用于文本生成、问答系统、机器翻译等任务;在计算机视觉领域,则可用于图像识别、物体检测、图像生成等;在智能客服、内容推荐、药物研发等领域,大模型也发挥了重要作用。具体案例包括GPT系列在文本创作和聊天机器人中的应用,以及BERT在搜索引擎中的优化。
7. 性能评估标准
评估大模型性能的标准多种多样,根据任务类型不同而有所区别。在自然语言处理领域,常用BLEU、ROUGE等指标评估文本生成的质量;在分类任务中,则常用准确率、召回率、F1分数等指标。此外,推理速度、模型大小、能耗等也是评估大模型实用性的重要指标。
8. 未来发展趋势
展望未来,大模型的发展将呈现以下几个趋势:一是模型规模继续扩大,追求更高的性能和更广泛的任务覆盖;二是模型的可解释性和可控性将受到更多关注,以提升其安全性和可靠性;三是模型的轻量化和边缘部署将成为重要研究方向,以满足更多实际应用场景的需求;四是跨模态学习和大一统模型的兴起,有望打破领域壁垒,实现更加智能和通用的AI系统。
一、全套AGI大模型学习路线
AI大模型时代的学习之旅:从基础到前沿,掌握人工智能的核心技能!

因篇幅有限,仅展示部分资料,需要点击下方链接即可前往获取
2024最新版CSDN大礼包:《AGI大模型学习资源包》免费分享
二、640套AI大模型报告合集
这套包含640份报告的合集,涵盖了AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。

因篇幅有限,仅展示部分资料,需要点击下方链接即可前往获取
2024最新版CSDN大礼包:《AGI大模型学习资源包》免费分享
三、AI大模型经典PDF籍
随着人工智能技术的飞速发展,AI大模型已经成为了当今科技领域的一大热点。这些大型预训练模型,如GPT-3、BERT、XLNet等,以其强大的语言理解和生成能力,正在改变我们对人工智能的认识。 那以下这些PDF籍就是非常不错的学习资源。

因篇幅有限,仅展示部分资料,需要点击下方链接即可前往获取
2024最新版CSDN大礼包:《AGI大模型学习资源包》免费分享
四、AI大模型商业化落地方案

因篇幅有限,仅展示部分资料,需要点击下方链接即可前往获取
2024最新版CSDN大礼包:《AGI大模型学习资源包》免费分享
作为普通人,入局大模型时代需要持续学习和实践,不断提高自己的技能和认知水平,同时也需要有责任感和伦理意识,为人工智能的健康发展贡献力量。















 779
779

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









